







Scrapy Cluster新手教程
最近正在接触大数据和人工智能方面的工作。为了满足数据量需求,需要开发一个爬虫系统来收集数据。在网上查了很多资料,发现大家用得比较多包括Scrapy, Scrapy Redis和Scrapy Cluster。前两个项目用得人比较多,也非常容易搭建。相比之下,Scrapy Cluster的相关文档少很多,网上的资料也少。因此就打算写一篇文档,记录以下学习过程和一些坑。
爬虫框架Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。具体Scrapy信息可以访问其主页scrapy.org。附带Scrapy的文档地址: https://docs.scrapy.org/en/latest/
分布式爬虫框架Scrapy Cluster
Scrapy Cluster是一个基于Scrapy项目的分布式解决方案。在Scrapy的基础上引入了Kafka,Zookeeper,Redis组件。使用Scrapy Cluster可以快速的搭建易扩展,高并发的分布式爬虫集群。该项目的的GitHub站点:https://github.com/istresearch/scrapy-cluster/。该项目的文档地址:https://scrapy-cluster.readthedocs.io/en/latest/
Scrapy Cluster有以下特点:
- 允许任何web页面的任意集合提交给scrapy集群,包括动态需求
- 大量的scrapy实例在单个机器或多个机器上进行爬取。
- 协调和优化他们的抓取工作所需的网站。
- 存储抓取的数据。
- 并行执行多个抓取作业。
- 深度信息抓取工作,网站排名,预测等。
- 可以任意add/remove/scale爬虫而不会造成数据丢失或停机等待。
- 利用Kafka作为集群的数据总线与集群的(提交工作,信息输入,停止工作,查看结果)
- 能够调整管理独立的爬虫在多台机器上,但必须用相同的IP
Scrapy Cluster原理流程图
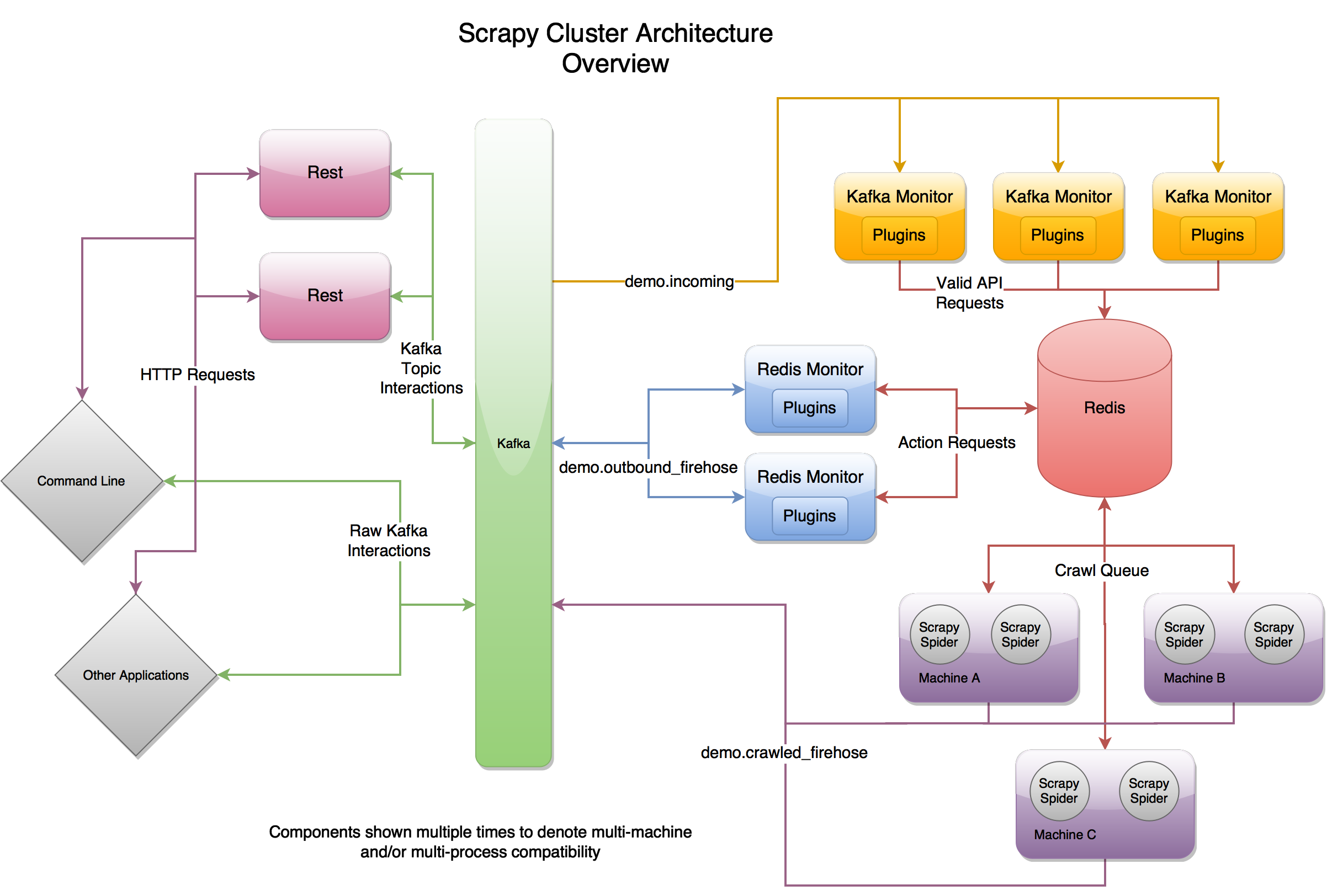
在最高层次上,Scrapy Cluster集群作用于单个输入Kafka的Topic,和两个地理输出kafka的Topic。所有请求传入集群的Kafka Topic都是通过demo.incoming,并根据传入请求将生成行为请求Topic, demo.outbound_firehose或网页爬取请求Topic demo.crawled_firehose。这里包括的三个组件是可扩展的,kafka组建和Redis组建都使用“插件”以提高自己的能力,Scrapy可以运用Middlewares,Pipline,Spider去定制自己的爬取需求,这三个组建在一起允许缩放和分布式运行在许多机器上。
Scrapy Cluster本机搭建
Scrapy Cluster系统需要开Kafka服务,Zookeeper服务,Redis服务和本身的Scrapy Cluster服务。由于篇幅问题,本文就不涉及到Kafka,Zookeeper,和Redis的安装配置。毕竟网上相关资源比较多,如果要在一台机器上装这些服务也非常简单。本文就说说在本机上安装,配置,和启动Scrapy Cluster服务。
下载
我们可以到Scrapy Cluster的GitHub上下载到最新的发布版本。在写这篇文章的时候,最新版本为1.2.1。
下载Scrapy Cluster 1.2.1
安装依赖包
进入文件根目录,根据requirements.txt文件下载依赖需求:
pip install -r requirements.txt
当出现Successfully installed scutils-1.2.0 tldextract-2.0.2 ujson-1.35字样时,就代表安装成功了!
**注意:**当前Scrapy Cluster版本1.2.1只支持Python2.7,因此使用Python3或者Pip3安装依赖包会报错。
**注意:**如果在Windows中安装Scrapy Cluster,scrapy-cluster需要安装ujson, scutils, tldextract。由于ujson是c++编译的,所以需要c++的环境,如果没有安装Micorsoft Visual C++ Compiler for Python 2.7的包就会报错:
Installing collected packages: ujson, scutils, tldextract
Running setup.py install for ujson ... error
Complete output from command c:\python27\python.exe -u -c "import setuptools, tokenize;__file__='c:\\users\\kylin\\appdata\\local\\temp\\pip-install-vpfa55\\ujson\\setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record c:\users\kylin\appdata\local\temp\pip-record-h1jdhp\install-record.txt --single-version-externally-managed --compile:
running install
running build
running build_ext
building 'ujson' extension
error: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27
解决办法是下载Micorsoft Visual C++ Compiler for Python 2.7,安装后继续安装scrapy-cluster。
配置文件
Scrapy Cluster有几个地方需要配置。分别在以下三个文件夹中:
./kafka-monitor
./redis-monitor
./crawler/crawling
这里需要注意的是,以上文件夹中都有一个
setting.py
文件。个人建议,不要动这个文件。如果需要修改配置,可以在同级文件夹下创建
localsettings.py
。以下是本人的配置样例:
# localsettings.py in kafka-monitor
REDIS_HOST = 'test'
REDIS_PORT = 6379
KAFKA_HOSTS = 'test:9092'
# localsettings.py in redis-monitor
REDIS_HOST = 'test'
REDIS_PORT = 6379
KAFKA_HOSTS = 'test:9092'
ZOOKEEPER_HOSTS = 'test:2181'
# localsettings.py in crawler/crawling
REDIS_HOST = 'test'
REDIS_PORT = 6379
KAFKA_HOSTS = 'test:9092'
ZOOKEEPER_HOSTS = 'test:2181'
以上配置文件中,test是一个主机名,大家可以改为自己的服务器地址,例如127.0.0.1,或者在主机中做相关配置。
验证配置是否正确
验证配置是否正确的方法可以按照官方文档的方式离线运行单元测试,以确保一切似乎正常:
$ ./run_offline_tests.sh
但是文档里面的很多方法都不太方便。我这里总结了一个比较简单的方案,就是在kafka-monitor文件夹下运行以下命令来验证Kafka是否可以连接:
python kafkadump.py list
如果在配置文档中仍然使用test主机名,但是在系统hosts文件中没有配置,会报错,因此建议在运行以上命令前先参考Hosts文件配置章节:
Traceback (most recent call last):
File "kafkadump.py", line 173, in <module>
sys.exit(main())
File "kafkadump.py", line 78, in main
kafka = KafkaClient(kafka_host)
File "C:\Python27\lib\site-packages\kafka\__init__.py", line 45, in __init__
super(KafkaClient, self).__init__(*args, **kwargs)
File "C:\Python27\lib\site-packages\kafka\client.py", line 57, in __init__
self.load_metadata_for_topics() # bootstrap with all metadata
File "C:\Python27\lib\site-packages\kafka\client.py", line 531, in load_metadata_for_topics
resp = self.send_metadata_request(topics)
File "C:\Python27\lib\site-packages\kafka\client.py", line 596, in send_metadata_request
return self._send_broker_unaware_request(payloads, encoder, decoder)
File "C:\Python27\lib\site-packages\kafka\client.py", line 178, in _send_broker_unaware_request
conn.recv()
File "C:\Python27\lib\site-packages\kafka\conn.py", line 595, in recv
if not self.connected() and not self.state is ConnectionStates.AUTHENTICATING:
File "C:\Python27\lib\site-packages\kafka\conn.py", line 481, in connected
return self.state is ConnectionStates.CONNECTED
如果在终端中能够输出以下内容,表示配置正确:
2019-06-05 11:05:47,750 [kafkadump] INFO: Connected to test:9092
Topics:
- demo.outbound_firehose
- demo.incoming
- demo.crawled_firehose
- __consumer_offsets
启动服务
按照Scrapy Cluster文档中的描述,需要在命令行中启动以下服务,在运行命令行之前,请确保对应的文件夹路径。首先,我们启动kafka-monitor服务,在文件夹kafka-monitor下运行:
python kafka_monitor.py run
随后请开启另一个命令行窗口,在文件夹redis-monitor下运行以下命令启动redis-monitor服务:
python redis_monitor.py
最后启动Scrapy爬虫组件,例如我们要启动Scrapy Cluster自带的爬虫link_spider.py(我们可以在文件夹scrapy-cluster-1.2.1\crawler\crawling\spiders中找到),可以在crawler文件夹下运行:
scrapy runspider crawling/spiders/link_spider.py
爬虫小试
Scrapy Cluster是分布式爬虫框架。如果需要输入爬取指令,需要把指令发送到Kafka,随后kafka-monitor服务会从Kafka中消费该消息并转化为一个爬取指令并发送到Redis服务。随后Scrapy爬虫会从Redis中获取需要爬取的任务内容。要生产一条爬取指令,我们可以在scrapy-cluster-1.2.1/kafka-monitor路径下执行以下代码:
python kafka_monitor.py feed '{"url": "http://101.132.238.47/au.php","appid": "myapp","crawlid": "jmstest","spiderid": "link"}'
由于我这边的服务是在Windows 10上跑的,会报以下错误(Linux和Mac上好像没有这个问题):
Traceback (most recent call last):
File "kafka_monitor.py", line 559, in
sys.exit(main())
File "kafka_monitor.py", line 555, in main
return kafka_monitor.feed(parsed)
File "kafka_monitor.py", line 438, in feed
result = _feed(json_item)
File "C:\Python27\lib\site-packages\scutils\method_timer.py", line 43, in f2
old_handler = signal.signal(signal.SIGALRM, timeout_handler)
AttributeError: 'module' object has no attribute 'SIGALRM'
以上是由于平台问题,在Windows平台上,signal.SIGALRM信号是不存在的。因此我们可以把以下代码注释掉,不影响使用。
C:\Python27\lib\site-packages\scutils\method_timer.py, line 43的old_handler = signal.signal(signal.SIGALRM, timeout_handler)
C:\Python27\lib\site-packages\scutils\method_timer.py, line 51的signal.signal(signal.SIGALRM, old_handler),并加上pass
C:\Python27\lib\site-packages\scutils\method_timer.py, line 52的signal.alarm(0)
C:\Python27\lib\site-packages\scutils\method_timer.py, line 45的signal.alarm(timeout_time)
另外,在Windows的终端窗口输入feed命令还可能碰到以下错误:
E:\scrapy-cluster-1.2.1\scrapy-cluster-1.2.1\kafka-monitor>python kafka_monitor.py feed '{"url": "http://101.132.238.47/au.php","appid": "myapp","crawlid": "jmstest","spiderid": "link"}'
usage: kafka_monitor.py [-h] {feed,run} ...
kafka_monitor.py: error: unrecognized arguments: http://101.132.238.47/au.php,appid: myapp,crawlid: jmstest,spiderid: link}'
只是由于单引号和双引号的问题,全部改为双引号并添加反斜杠(\)即可:
python kafka_monitor.py feed "{\"url\": \"http://101.132.238.47/au.php\",\"appid\": \"myapp\",\"crawlid\": \"jmstest\",\"spiderid\": \"link\"}"
如果以上指令运行成功,会输出类似以下内容,表示信息成功推送至Kafka。
2019-06-05 14:12:39,974 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"url": "http://101.132.238.47/au.php",
"spiderid": "link",
"crawlid": "jmstest",
"appid": "myapp"
}
2019-06-05 14:12:40,009 [kafka-monitor] INFO: Successfully fed item to Kafka
接下来,我们会在启动爬虫的窗口中看到类似以下内容说明整个Scrapy Cluster已经跑通了:
2019-06-05 14:26:05,502 [sc-crawler] DEBUG: Logging to stdout
2019-06-05 14:26:05,559 [sc-crawler] DEBUG: Connected to Redis in LogRetryMiddleware
2019-06-05 14:26:05,565 [sc-crawler] DEBUG: Setting up log retry middleware stats
2019-06-05 14:26:05,621 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_15_MINUTE'
2019-06-05 14:26:05,706 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_HOUR'
2019-06-05 14:26:05,772 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_6_HOUR'
2019-06-05 14:26:05,857 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_12_HOUR'
2019-06-05 14:26:05,913 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_DAY'
2019-06-05 14:26:06,046 [sc-crawler] DEBUG: Set up LRM status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_WEEK'
2019-06-05 14:26:06,111 [sc-crawler] DEBUG: Set up status code 504, link spider,host LAPTOP-ER0J6T4G Stats Collector 'lifetime'
2019-06-05 14:26:06,184 [sc-crawler] DEBUG: Connected to Redis in ScraperHandler
2019-06-05 14:26:06,372 [sc-crawler] DEBUG: Setup before pipeline
2019-06-05 14:26:06,655 [sc-crawler] DEBUG: Setup kafka pipeline
2019-06-05 14:26:06,742 [sc-crawler] DEBUG: Current public ip: b'123.58.180.7'
2019-06-05 14:26:06,743 [sc-crawler] INFO: Changed Public IP: None -> b'123.58.180.7'
2019-06-05 14:26:06,816 [sc-crawler] DEBUG: Added new Throttled Queue link:101.132.238.47.:queue
2019-06-05 14:26:06,819 [sc-crawler] DEBUG: Trying to establish Zookeeper connection
2019-06-05 14:26:07,102 [sc-crawler] DEBUG: Successfully set up Zookeeper connection
2019-06-05 14:26:07,193 [sc-crawler] DEBUG: Current public ip: b'123.58.180.7'
2019-06-05 14:26:07,193 [sc-crawler] DEBUG: Reporting self id
2019-06-05 14:26:07,532 [sc-crawler] DEBUG: Found url to crawl http://101.132.238.47/au.php
2019-06-05 14:26:07,743 [sc-crawler] DEBUG: processing redis stats middleware
2019-06-05 14:26:07,792 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_15_MINUTE'
2019-06-05 14:26:07,839 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_HOUR'
2019-06-05 14:26:07,858 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_6_HOUR'
2019-06-05 14:26:07,920 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_12_HOUR'
2019-06-05 14:26:07,937 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_DAY'
2019-06-05 14:26:07,960 [sc-crawler] DEBUG: Set up status code 200, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_WEEK'
2019-06-05 14:26:08,012 [sc-crawler] DEBUG: Set up status code 200, link spider,host LAPTOP-ER0J6T4G Stats Collector 'lifetime'
2019-06-05 14:26:08,032 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_15_MINUTE'
2019-06-05 14:26:08,098 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_HOUR'
2019-06-05 14:26:08,122 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_6_HOUR'
2019-06-05 14:26:08,158 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_12_HOUR'
2019-06-05 14:26:08,180 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_DAY'
2019-06-05 14:26:08,210 [sc-crawler] DEBUG: Set up status code 404, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_WEEK'
2019-06-05 14:26:08,232 [sc-crawler] DEBUG: Set up status code 404, link spider,host LAPTOP-ER0J6T4G Stats Collector 'lifetime'
2019-06-05 14:26:08,249 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_15_MINUTE'
2019-06-05 14:26:08,275 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_HOUR'
2019-06-05 14:26:08,318 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_6_HOUR'
2019-06-05 14:26:08,341 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_12_HOUR'
2019-06-05 14:26:08,368 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_DAY'
2019-06-05 14:26:08,414 [sc-crawler] DEBUG: Set up status code 403, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_WEEK'
2019-06-05 14:26:08,434 [sc-crawler] DEBUG: Set up status code 403, link spider,host LAPTOP-ER0J6T4G Stats Collector 'lifetime'
2019-06-05 14:26:08,533 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_15_MINUTE'
2019-06-05 14:26:08,572 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_HOUR'
2019-06-05 14:26:08,619 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_6_HOUR'
2019-06-05 14:26:08,642 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_12_HOUR'
2019-06-05 14:26:08,674 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_DAY'
2019-06-05 14:26:08,713 [sc-crawler] DEBUG: Set up status code 504, link spider, host LAPTOP-ER0J6T4G Stats Collector 'SECONDS_1_WEEK'
2019-06-05 14:26:08,733 [sc-crawler] DEBUG: Set up status code 504, link spider,host LAPTOP-ER0J6T4G Stats Collector 'lifetime'
2019-06-05 14:26:08,885 [sc-crawler] DEBUG: Incremented status_code '200' stats
2019-06-05 14:26:08,989 [sc-crawler] DEBUG: processing meta passthrough middleware
2019-06-05 14:26:08,989 [sc-crawler] DEBUG: crawled url http://101.132.238.47/au.php
2019-06-05 14:26:08,989 [sc-crawler] DEBUG:
2019-06-05 14:26:08,990 [sc-crawler] DEBUG: Not spidering links in 'http://101.132.238.47/au.php' because cur_depth=0 >= maxdepth=0
2019-06-05 14:26:08,990 [sc-crawler] DEBUG: Processing item in LoggingBeforePipeline
2019-06-05 14:26:08,990 [sc-crawler] INFO: Scraped page
2019-06-05 14:26:08,990 [sc-crawler] DEBUG: Processing item in KafkaPipeline
2019-06-05 14:26:09,040 [sc-crawler] INFO: Sent page to Kafka
爬虫指令在Redis中的存储方式
爬取命令发送到Kafka以后会被kafka-monitor消费并转化为对象存到Redis中。使用Redis Desktop Manager可以查看Redis服务器中的数据。爬取命令对象在Redis中对应的key,按照官方文档的描述,key的格式为::queue。按照以上示例,key应该为link:101.132.238.47.:queue。在没有开启Scrapy爬虫服务的情况下,这个key是存在的,value值为:
{
"allowed_domains": null,
"allow_regex": null,
"crawlid": "jmstest",
"url": "http:\/\/101.132.238.47\/au.php",
"expires": 0,
"ts": 1559720508.3933498859,
"priority": 1,
"deny_regex": null,
"spiderid": "link",
"attrs": null,
"appid": "myapp",
"cookie": null,
"useragent": null,
"deny_extensions": null,
"maxdepth": 0
}
如果开启了Scrapy爬虫服务,爬虫会搜索这个key并且拿到相应的爬虫指令。如果这个key中只有一条指令,该key就会被清空。
如何配置系统的Hosts文件
本文中的配置文件使用的是机器名test作为服务地址,例如KAFKA_HOSTS = ‘test:9092’。在Linux中可以编辑/etc/hosts文件指定主机名对应的IP地址。在Windows环境下,Hosts是一个没有扩展名的系统文件,其基本作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统再会将网址提交DNS域名解析服务器进行IP地址的解析,如果发现是被屏蔽的IP或域名,就会禁止打开此网页!我们可以在Windows中编辑C:\Windows\System32\drivers\etc\hosts文件,加入
123.58.180.7 test
此时在命令行窗口中ping test得到以下信息,说明配置成功:
正在 Ping test [101.89.92.183] 具有 32 字节的数据:
来自 101.89.92.183 的回复: 字节=32 时间=14ms TTL=36
来自 101.89.92.183 的回复: 字节=32 时间=13ms TTL=36
来自 101.89.92.183 的回复: 字节=32 时间=13ms TTL=36
101.89.92.183 的 Ping 统计信息:
数据包: 已发送 = 3,已接收 = 3,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 13ms,最长 = 14ms,平均 = 13ms
结束语
本文大部分内容是在Windows 10上完成的,因此如果您在Linux或Mac上,可能会碰到其它问题。另外本文使用的是Scrapy Cluster 1.2.1,不同的版本可能会有不同的问题。另外,本文没有涉及到Kafka,Zookeeper和Redis的安装部署。如果朋友们在安装和使用Scrapy Cluster的过程中有任何问题,可以留言。














 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









