







本篇解决的问题
使用Java 的Runtime调用操作系统的命令,出现异常时使用getErrorStream()获取错误信息的字节流,转换该字节流为字符串显示时,出现乱码。
Java调用操作系统命令
这里以Windows 操作系统为例, 调用cd 命令切换路径。
使用Java调用操作系统本身的命令使用Runtime 的exec() 方法,执行的命令以 cmd.exe /c 开头,后面接上需要执行的语句, 代码如下:
Runtime rt = Runtime.getRuntime();
Process pr = rt.exec("cmd.exe /c cd errorpath");
如何获取执行的结果呢? 甚至如果执行失败, 获取执行的错误信息。
- Process 的 waitFor() 方法用于等待进程完成,然后获取返回码
- 错误信息也可以通过Process 的getErrorStream()方法获取错误的字节流,通过Java的字节流和字符串的转换可以错误信息的字符串, 完整的代码如下所示:
int exitCode = pr.waitFor(); // 等待进程完成,然后获取返回码
if (exitCode == 0) {
System.out.println("命令执行成功!");
} else {
System.out.println("命令执行失败, 返回码: " + exitCode);
try (BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(pr.getErrorStream()))) {
String line;
StringBuilder content = new StringBuilder();
while ((line = bufferedReader.readLine()) != null) {
content.append(line);
content.append(System.lineSeparator()); // 添加行分隔符,如果需要的话
}
String errorText = content.toString();
// 打印或处理错误消息
System.out.println("错误信息:"+errorText);
}
}
问题描述
上面的代码为了演示错误的场景直接切换到一个不存在的目录,在某些环境下(操作系统、JVM)是正常的, 但是在笔者的机器上,在Eclipse中执行的时候,错误信息的显示确是乱码, 界面如下:

在命令行直接执行该命令的时候,效果如下:

可以看到这里的操作系统使用的是中文的字符。
如何查看Windows操作系统的字符集
查看Windows 操作系统的默认字符集,可以通过如下步骤:
- 打开控制面板
- 点击区域和语言选项(在某些Windows版本中可能叫做区域或者时钟,语言和区域)。
- 查看系统的区域设置
如下图:
注意: 这里查看的只是区域设置, 并不是直接的字符集。 是否还有其他方式查看呢?比如说命令行。
Windows的命令行有一个 systeminfo 命令可以用来查看操作系统的一些设定,执行的结果如下:
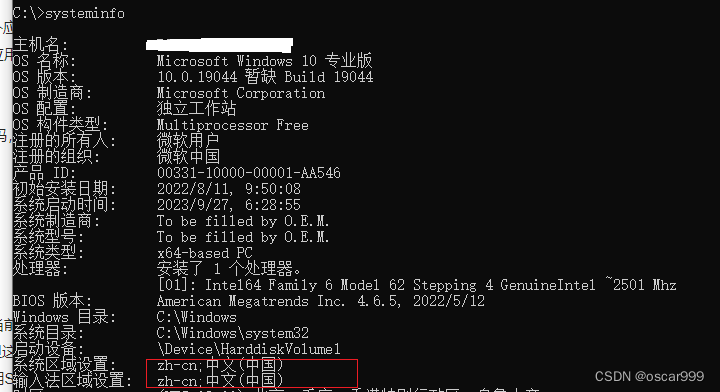
这个命令看到的结果和上面使用控制面板看到的基本一样, 可以查看当前系统的区域语言设置。但并不是直接的字符集。系统字符集通常从区域语言设置和其他系统配置片断中获取,但这些信息并不直接等于字符集。也就是说在Windows命令行中(CMD),不能直接获取当前的字符编码,但可以查看当前的区域语言设置,它影响了系统非Unicode程序使用的字符集。
如果系统区域设置(system locale)是 zh_CN,那么表示系统使用的是简体中文(中国)。在这种设置下,Windows系统通常使用GBK作为默认的字符编码, 注意是“通常”,并不是一定。如何能坐实操作系统使用的字符集呢?
使用Maven查看语言设置和字符集
如果当前的机器安装了Maven ,可以使用Maven查看版本的命令其实可以看到这两种的设置:
在命令行输入:
mvn -v
命令的输入如下:

以上可以看到操作系统的语言区域和字符集分别是 zh_CN和GBK
Java 的字符集是如何设定
Windows操作系统支持多种不同的字符集,每个应用程序可能使用不同的设置。如果你在Java中创建一个新的进程,那么该进程的默认字符集设置将会继承自Java应用的设置。可以通过Charset.defaultCharset()查询到Java使用的默认字符集。
如果想在Java程序中获取Windows的默认字符集,可以使用System.getProperty(“file.encoding”),这一命令将返回运行Java程序的JVM的系统字符集。在大多数情况下,这应当等同于Windows的系统字符集。然而,这将取决于你的JVM启动参数和环境变量。
所以在Java中获取默认字符集的方式有两种:
- 通过System获取文件编码的系统属性
System.getProperty("file.encoding") - 通过Charset获取
具体的代码方式如下:
System.out.println(System.getProperty("file.encoding"));
System.out.println(Charset.defaultCharset());
这里的输出是:
UTF-8
UTF-8
注意: 这两种方式返回的字符编码可能不一样,也可能一样,但是书写并不一致, 可能一个是UTF8,另一个是UTF-8, 但这都不是最主要的, 最主要的是这里的场景下, 为什么不是上面的 GBK? 直接说结论吧:
不管是在Eclipse还是在其他任何环境下运行Java程序,编码配置可能会受到多种因素的影响,包括JVM配置和操作系统设定等。
在Java中,系统默认的字符编码由JVM本身决定,通常与宿主操作系统的区域设置和字符编码设置相同。
系统默认的字符编码是在JVM启动时就被确定下来的,通常是 JVM 根据操作系统的环境设置来决定的。但是 JVM 的默认字符编码也可以通过 JVM 启动参数来改变,如 -Dfile.encoding=UTF-8。
也就是说Java除了可以继承操作系统的字符集外,也可以自行设定字符集。
JVM的字符编码也是可以改变的。
- 在 Eclipse 中,这可以在 “Run Configurations” -> “Arguments” -> “VM arguments” 中设置。例如添加 -Dfile.encoding=GBK。
- 也可以通过设置 JVM 的启动参数来实现
字符集的设定
既然上面Java的字符集编码是UTF-8, 那么这里出现乱码的原因是否是字节流转换为字符串时编码的问题呢?
于是想到是否 在InputStreamReader读取字节流的时候转为UTF-8的编码就可以了呢?
于是代码修改为如下:
new InputStreamReader(pr.getErrorStream(),StandardCharsets.UTF_8))
到时, 到这输出的还是乱码。
于是想: 在cmd命令行输出的是中文, 是否字节流转换成GBK的编码就可以了呢?
在 Java 中,StandardCharsets 是一个预定义字符集的工具类,它定义了一些常用的字符集实例。但是,GBK 并没有被包含在 StandardCharsets 里。StandardCharsets 只定义了以下这些常用字符集:US-ASCII、ISO-8859-1、UTF-8、UTF-16BE、 UTF-16LE 和 UTF-16。
如果需要使用 GBK 编码,那么就不能从 StandardCharsets 查找到,而需要直接使用字符串 “GBK” 来代替。例如,如果需要将一个 InputStream 根据 GBK 编码转换为 Reader ,可以使用如下方式:
InputStream inputStream = ...; // 输入流
Reader reader = new InputStreamReader(inputStream, "GBK");
这段代码将会根据 GBK 编码创建一个新的 InputStreamReader。
需要注意的是,字符编码字符串 “GBK” 是大小写不敏感的,你也可以写为 “gbk”。然而,因为大写字符通常更容易阅读和理解,所以 “GBK” 通常是更常用的写法。
字节流转换成GBK 之后, 就正常的输出中文错误信息了, 乱码问题解决了。
最终的解法
在执行操作系统命令, 获取返回信息或是错误信息的场景中, 为了解决乱码的问题,终极的解法就是定义一个获取字符集的方法,因为无法直接获取操作系统的字符集, 就先获取区域语言,如果是 zh_CN,就使用 GBK编码, 否则就使用UTF-8的编码。相关的其他场景也可以据此思路扩展此方法, 方法的定义如下:
public static String getCharsetName() {
String charaset = StandardCharsets.UTF_8.toString();
Locale locale = Locale.getDefault();
if ("zh_CN".equals(locale.toString())) {
charaset = "GBK";
}
return charaset;
}















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











