






【背景】
flink有几种聚合,使用上是有一些不同,需要加以区分:
分组聚合:group agg
over聚合:over agg
窗口聚合:window agg
省流版:
| 触发计算时机 | 结果流类型 | 状态大小 | |
| 分组聚合group agg | 每当有新行就输出更新的结果 | update流 | 保持中间结果,所以状态可能无限膨胀 |
| over agg | 每当有新行就输出更新的结果,类似一个滑动窗口 | append流 | 保持中间结果,所以状态可能无限膨胀 |
| window agg | 窗口结束产生一个总的聚合结果 | append流 | 不生成中间结果,自动清除状态 |
下面是详细对比和具体的例子(主要讨论的是流处理下的情况)。
over聚合:over agg
OVER 聚合通过排序后的范围数据为每行输入计算出聚合值。和 GROUP BY 聚合不同, OVER 聚合不会把结果通过分组减少到一行,它会为每行输入增加一个聚合值,结果是一个append流。
OVER 窗口的语法。
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition),
...
FROM ...over聚合很少用到,所以本地自己做了一个测试:
create table test_window_tab
(
region String
,qa_id String
,count_qa_id Bigint
) COMMENT ''
with
(
'properties.bootstrap.servers' ='',
'json.fail-on-missing-field' = 'false',
'connector' = 'kafka',
'format' = 'json',
'topic' = 'test_window_tab'
)
;
create table dwm_qa_score
(
,qa_id String
,agent_id String
,region String
,saas_id String
,version_timestamp bigint
, ts as to_timestamp(from_unixtime(`version_timestamp`, 'yyyy-MM-dd HH:mm:ss'))
,`event_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL
,WATERMARK FOR `ts` AS `ts` - INTERVAL '10' SECOND
) COMMENT ''
with
(
'properties.bootstrap.servers' ='',
'json.fail-on-missing-field' = 'false',
'connector' = 'kafka',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset',
'topic' = 'dwm_qa_score'
)
;
insert into test_window_tab(region,qa_id,count_qa_id)
select region,qa_id,count(1) over w as count_qa_id
from dwm_qa_score
window w as(
partition by region,qa_id
order by ts
rows between 2 preceding and current row
)dwm_qa_score这个topic现有数据:
{ "qa_id": "123", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
{ "qa_id": "123", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
{ "qa_id": "123", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
{ "qa_id": "123", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
{ "qa_id": "123", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
{ "qa_id": "1234", "agent_id": "497235295815123",
"region": "TH", "version_timestamp": 1709807228
}
当读数据选择了offset=ealiest-offset,则运行程序会得到结果如下:
{"region":"TH","qa_id":"123","count_qa_id":1}
{"region":"TH","qa_id":"123","count_qa_id":2}
{"region":"TH","qa_id":"123","count_qa_id":3}
{"region":"TH","qa_id":"123","count_qa_id":3}
{"region":"TH","qa_id":"123","count_qa_id":3}
{"region":"TH","qa_id":"1234","count_qa_id":1}
这里注意:
- 对每条数据都会返回一个聚合值
- 由于我们是“rows between 2 preceding and current row“,所以count_qa_id最多是3
如果此时往dwm_qa_score这个topic插入新数据:
{ "qa_id": "1234", "agent_id": "497235295815123",
"region": "TH"
}
或者
{ "qa_id": "1234", "agent_id": "497235295815123",
"region": "TH","version_timestamp": null
}
或者
{ "qa_id": "1234", "agent_id": "497235295815123",
"region": "TH","version_timestamp": 0
}
会发现flink作业中输出的record多了一条:
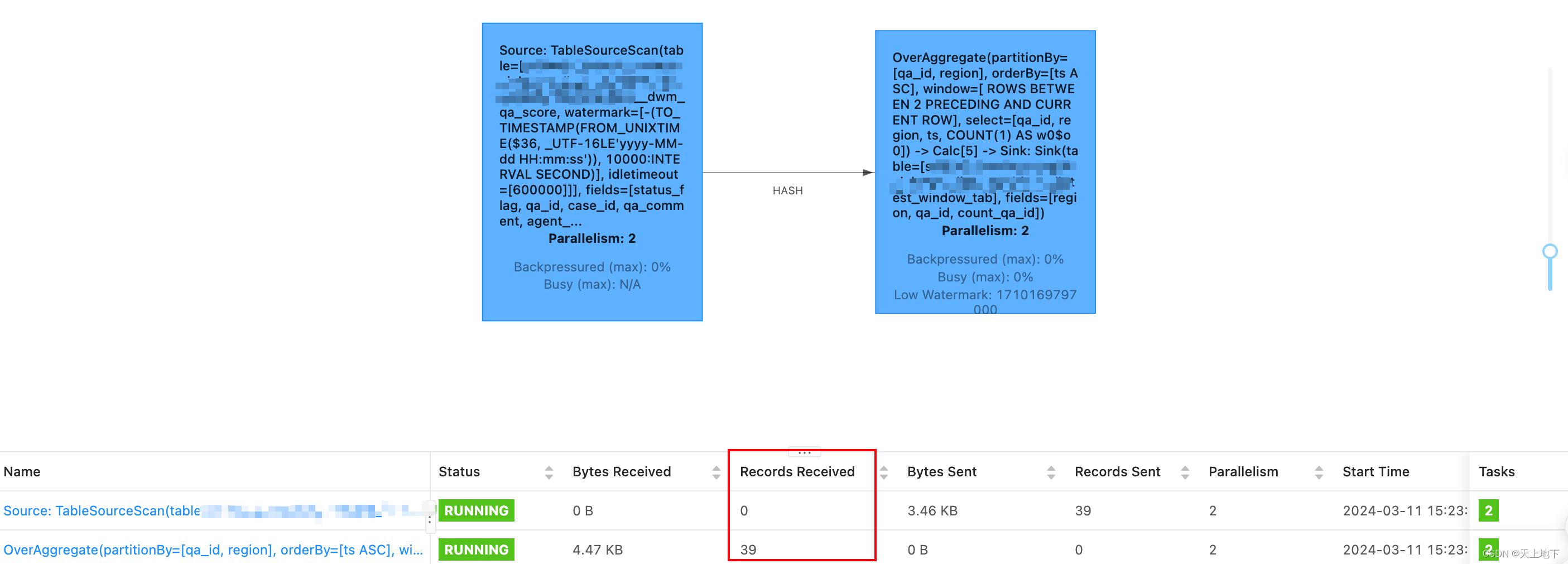
但是在目标kafka:test_window_tab中没有新增结果
原因是我们插入的新数据中没有version_timestamp这一列为空或为0
如果往dwm_qa_score这个topic插入新数据:
{
"qa_id": "1234",
"region": "TH",
"version_timestamp": 1710145110
}
则可以看到对应目标kafka:test_window_tab中会新增结果数据
{"region":"TH","qa_id":"1234","count_qa_id":2}
如果等一分钟后,再次往dwm_qa_score这个topic插入新数据:
{
"qa_id": "1234",
"region": "TH",
"version_timestamp": 1710145110
}
则在目标kafka:test_window_tab中没有新增结果,原因应该是数据过期被丢弃了(watermark)
你可以在一个 SELECT 子句中定义多个 OVER 窗口聚合。然而,对于流式查询,由于目前的限制,所有聚合的 OVER 窗口必须是相同的。
ORDER BY
OVER 窗口需要数据是有序的。因为表没有固定的排序,所以 ORDER BY 子句是强制的。对于流式查询,Flink 目前只支持 OVER 窗口定义在升序(asc)的 时间属性 上。其他的排序不支持。
PARTITION BY
OVER 窗口可以定义在一个分区表上。PARTITION BY 子句代表着每行数据只在其所属的数据分区进行聚合。
范围(RANGE)定义
范围(RANGE)定义指定了聚合中包含了多少行数据。范围通过 BETWEEN 子句定义上下边界,其内的所有行都会聚合。Flink 只支持 CURRENT ROW 作为上边界。
有两种方法可以定义范围:ROWS 间隔 和 RANGE 间隔
RANGE 间隔
RANGE 间隔是定义在排序列值上的,在 Flink 里,排序列总是一个时间属性。下面的 RANG 间隔定义了聚合会在比当前行的时间属性小 30 分钟的所有行上进行。
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
ROW 间隔
ROWS 间隔基于计数。它定义了聚合操作包含的精确行数。下面的 ROWS 间隔定义了当前行 + 之前的 10 行(也就是11行)都会被聚合。
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
常见错误
OVER windows' ordering in stream mode must be defined on a time attribute.
这个报错,是建表的时候需要指定时间语义的字段,WATERMARK 是必须的,而且WATERMARK所用字段必须是order by的时间字段,例如下面用的是 order by load_date,那么WATERMARK就要用load_date生成,即WATERMARK FOR load_date AS load_date - INTERVAL '1' MINUTE
object SqlOverRows02 {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance().inStreamingMode().build()
val tEnv = TableEnvironment.create(settings)
tEnv.executeSql(
"""
|create table projects(
|id int,
|name string,
|score double,
|load_date timestamp(3),
|WATERMARK FOR load_date AS load_date - INTERVAL '1' MINUTE
|)with(
|'connector' = 'kafka',
|'topic' = 'test-topic',
|'properties.bootstrap.servers' = 'server120:9092',
|'properties.group.id' = 'testGroup',
|'scan.startup.mode' = 'latest-offset',
|'format' = 'csv'
|)
|""".stripMargin)
tEnv.executeSql(
"""
|select
| name,
| max(score)
| over(partition by name
| order by load_date
| RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW )max_score,
| min(score)
| over(partition by name
| order by load_date
| RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW )min_score,
| current_time
| from
| projects
|""".stripMargin).print()
}
}
分组聚合:group agg
Apache Flink 支持标准的 GROUP BY 子句来聚合数据。
SELECT COUNT(*) FROM Orders GROUP BY order_id
特点:
1、聚合函数把多行输入数据计算为一行结果。例如,有一些聚合函数可以计算一组行的 “COUNT”、“SUM”、“AVG”、“MAX”和 “MIN”。
2、对于流式查询,重要的是要理解 Flink 运行的是连续查询,永远不会终止,会根据其输入表的更新来更新其结果表。对于上述查询,每当有新行插入 Orders 表时,Flink 都会实时计算并输出更新后的结果。
3、对于流式查询,用于计算查询结果的状态可能无限膨胀。状态的大小取决于分组的数量以及聚合函数的数量和类型。例如:MIN/MAX 的状态是重量级的,COUNT 是轻量级的,因为COUNT只需要保存计数值。
因此,可以设置table-exec-state-ttl,但是可能会影响查询结果的正确性,因为状态超时会被丢弃。
注意:
Flink 对于分组聚合提供了一系列性能优化的方法。更多参见:性能优化,包括MiniBatch 聚合、Local-Global 聚合、拆分 distinct 聚合、在 distinct 聚合上使用 FILTER 修饰符 、MiniBatch Regular Joins
窗口聚合:window agg
窗口聚合是通过 GROUP BY 子句定义的,其特征是包含 窗口表值函数 产生的 “window_start” 和 “window_end” 列(必须包含,否则就变成分组聚合等了)。和普通的 GROUP BY 子句一样,窗口聚合对于每个组会计算出一行数据。
SELECT ...
FROM <windowed_table> -- relation applied windowing TVF
GROUP BY window_start, window_end, ...窗口聚合不产生中间结果,只在窗口结束产生一个总的聚合结果,另外,窗口聚合会清除不需要的中间状态(watermark超过窗口end+allowlateness,就会销毁窗口)。
具体例子:
SELECT window_start, window_end, SUM(price) AS
total_price
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------------+
| window_start | window_end | total_price |
+------------------+------------------+-------------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------------+















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









