







kNN算法用于分类,其基本思想很容易理解,就是找到与待分类的数据距离最近的前k个数据,再以这k个数据中出现分类最多的类别作为待分类数据的类别。是不是很简单?那我们接下来看一下距离应该如何去表示。
数据间的距离可以理解为数据间的相似度,距离越近,它们之间的相似度就越高,属于同一类别的可能性就越大。这里的距离计算我们用的是欧氏距离公式,其他的距离公式当然同样可以。所谓欧式距离公式,跟我们中学所学的两点间的距离计算公式相似,在欧氏距离中就是计算两个向量点之间的距离。
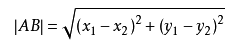
下面看一下kNN算法的伪代码:
对未知类别属性中的每一个点依次执行以下操作:
1、计算已知类别的数据点与当前数据点之间的距离
2、按照距离递增次序排序
3、选取与当前数据点距离最小的k个点
4、确定前k个点所在类别出现的频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
由于基本思路比较简单易懂,我们就直接来看一下关键代码部分
"""
函数说明: kNN算法
Params:
test —— 待分类的数据
data_set —— 已分好类的数据集
label —— 分类标签
k —— kNN算法参数,选择距离最小的k个数据
return:
classify_result —— kNN算法分类结果
"""
def classify(test, data_set, label, k):
# 计算两组数据的欧氏距离
# 复制test数据成为矩阵后利用矩阵运算计算x1-x2
test_copy = np.tile(test, (data_set.shape[0], 1)) - data_set
# 平方
sq_test_copy = test_copy ** 2
# 求和
row_sum = sq_test_copy.sum(axis=1)
# 开方,得到数据点间的距离
distance = row_sum ** 0.5
# 排序,得到距离递增的索引值
sorted_index = distance.argsort()
# 定义一个记录类别次数的字典
class_count = {}
# 遍历距离最近的前k个数据,统计类别出现次数
for v in range(k):
# 记录前 k 个元素的类别
near_data_label = label[sorted_index[v]]
# 统计类别次数
class_count[near_data_label] = class_count.get(near_data_label, 0) + 1
# 根据字典的值进行排序,从大到小
classify_result = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即待分类点的类别
return classify_result[0][0]
不太熟悉numpy或者python的话读这段代码也许会有些障碍,但思路根据伪代码和注释已经是非常清晰了,我简单总结了一下上面这段代码的一些函数,想深入了解的话也可以去百度,或者直接在编译器里面用一下这些函数,这样理解得更直观也更容易记忆。
“”"
知识点:
1、numpy函数shape[0]返回array的行数,shape[1]返回array列数(或元素数),shape[2]返回最小list元素数
(都是依次的,无绝对,然后shape会返回关于array行列数元素的所有信息)
2、numpy函数tile函数,其有两个参数,待重复元素A(可以是array,list,tuple,dict,matrix这些序列化类型)
(以及Python中的基本数据类型interesting,float,string,bool),第二个参数为重复次数及方式reps,
(可以是tuple,list,dict,array,int,bool)
3、sum() 所有元素相加,sum(0)列相加,sum(1)行相加
4、argsort()返回将列表从小到大排序后其原先的索引值
5、dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值(default)。
6、 sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
key=operator.itemgetter(1)根据字典的值进行排序
key=operator.itemgetter(0)根据字典的键进行排序
reverse降序排序字典
“”"
关于kNN的实例主要是在对数据的格式化处理后进行kNN算法调用,具体代码和数据可以访问我的github,python3的格式,有需要的可以看看详细代码
下面是简单的算法总结:
“”"
总结:
一、kNN算法基本原理:
通过计算待分类数据与已有数据之间的距离,找到距离最近的前k位的数据,再找出k位数据中出现次数最多的分类
,即为待分类数据所属类别
二、kNN算法实现基本步骤:
1、收集数据(可通过已有公开数据库或者爬虫等方式收集)
2、准备数据(最好是结构化的数据格式)
3、分析数据
4、测试算法(不需要训练算法)
5、使用算法
三、具体操作:
1、准备数据(结构化)
2、计算距离(欧式距离公式)
3、得到距离从小到大的索引值
4、找出前k个并找出类别出现次数最多的那个类别后返回
5、实例测试
“”"
kNN算法是分类数据最简单有效的方法,但它有几个明显的不足:
1、需保存全部数据,需要大量的存储空间
2、必须对每个数据进行距离计算,时间复杂度比较高
3、无法给出任何数据的基础结构信息,无法知晓平均实例样本和典型实例样本具有什么特征
本篇文章的数据来自《机器学习实战》这本书,算法思路是本人对其的简单理解,第一次写博客,记录一下以便之后使用。很多不足之处,多多包涵,以后熟悉了会写得好一点的。
2020年5月11日















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









