







声明:本文为引用他人文章,具体来自哪里不记得了,之前收藏在笔记中的
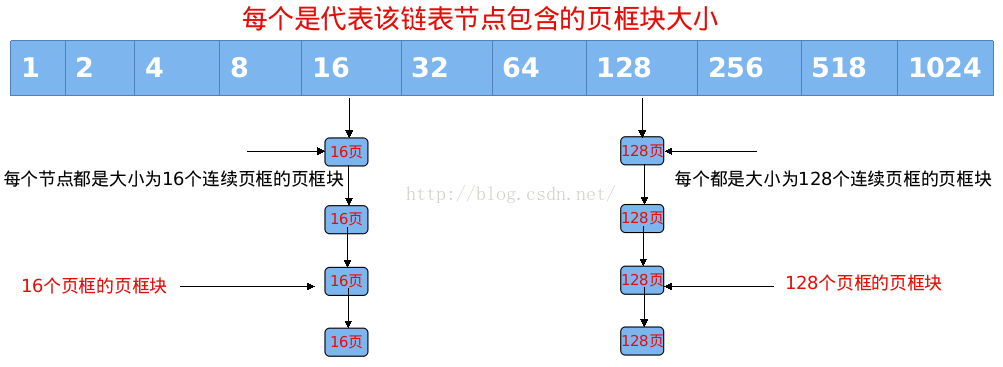
1、为了便于数据的频繁分配与回收,编程人员通常会用到空闲链表。
空闲链表包含可供使用的、已分配好的数据结构块。当代码需要一个新的数据结构实例时,就从空闲链表中抓取一个,而不需要分配内存,把数据放进去。以后,当不再需要这个数据结构时,就把他放回空闲链表中,而不是释放它。
从这个意义上说,空闲链表相当于高速缓存----快速存储频繁使用的对象类型。
2、但是,在内核中,空闲链表面临的一个问题是不能全局控制。当内存紧缺时,内核无法通知每个空闲链表,让它们挤出一些内存空闲来。事实上,内核根本就不知道有这些空闲链表的存在。
所以,为了弥补这一点,Linux内核提供了slab层(也就是所谓的slab分配器)slab分配器扮演了通用的数据结构缓存层的角色。
3、slab规则
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









