







Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
1、scrapy初始
我们知道,写一个爬虫是比较费劲的,比如说发起请求、数据解析、反反爬虫机制、异步请求等。如果我们每次都手动去操作,就很麻烦。scrapy这个框架已经把一些基础的内容封装好了,我们可以直接来使用,非常方便。
2、scrapy架构
我们通过下面两个图,来简单有个认识;

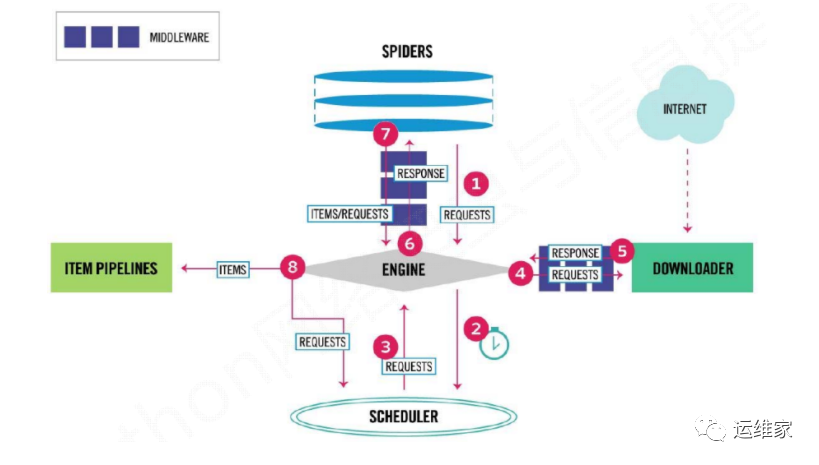
可以个上图看到,scrapy也是有很多组件组成的,那么我们分别看下每个组件的作用是什么吧;
3、scrapy组成
-
Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。 -
Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。 -
Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。 -
Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。 -
Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。 -
Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。 -
Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
本文结束,相关内容每日更新。
更多内容请转至VX公众号 “运维家” ,获取最新文章。
------ “运维家” ------
------ “运维家” ------
------ “运维家” ------
linux系统下,mknodlinux,linux目录写权限,大白菜能安装linux吗,linux系统创建文件的方法,领克linux系统怎么装软件,linux文本定位;
ocr识别linux,linux锚定词尾,linux系统使用记录,u盘有linux镜像文件,应届生不会Linux,linux内核64位,linux自启动管理服务;
linux计算文件夹大小,linux设备名称有哪些,linux能用的虚拟机吗,linux系统进入不了命令行,如何创建kalilinux,linux跟so文件一样吗。
















 3673
3673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











