







前言
最近跟同学参加了个比赛,我负责Object-Detection的技术实现,需要从网上扒大量的数据(主办方每种识别物就给了一张demo🤣),发现数据准备是一个真的是一个非常重要但又耗时耗力的过程。对我来说,给我一类待识别的标签,我一般会用以下的环节来获取数据:
- 从Google等网站搜关键词,然后爬个几百张数据,或者直接用google的搜相似图的功能
- 一些离线的数据增强处理
- 数据重命名(个人习惯,用data_{index}的顺序让数据排列的整齐一点)
但是准备几千张数据来组成数据集实在是有点烦人…于是我写了一组脚本,能够自动化的实现从数据获取到数据增强,然后批量重命名的脚本,希望能给同样需要处理大量数据的小伙伴剩下一点时间。
Github仓库地址:
> https://github.com/zin-Fu/Automation-Data-Processing
p.s.如果觉得对你有帮助欢迎给我点个👀watch或者star⭐吖!
关于Auto-DataProcessing
这组脚本的主要功能如下:
-
🚀数据收集:
crawler_keyword.py: 根据指定的关键词从谷歌图像搜索下载图片。crawler_similar.py: 从给定的 URL 获取图像(我是用来搜相似图的时候用的),可以从特定网站或来源收集数据。
-
🚀数据增强:
DataAugment.py: 通过应用翻转、旋转、添加噪声、高斯模糊、调整亮度对比度等多种数据增强技术,扩充和优化我们的数据集。创建多样化和鲁棒的训练数据。
3.🚀 数据管理:
rename.py: 重命名目录中所有图像文件,添加指定的前缀和连续编号,确保文件结构的一致。
此外,所有的参数(获取图片的数量,URL和数据增强的类型这些)都是执行之后在终端直接输入的,不用自己在代码里设定。以数据增强的脚本运行起来的终端为例:
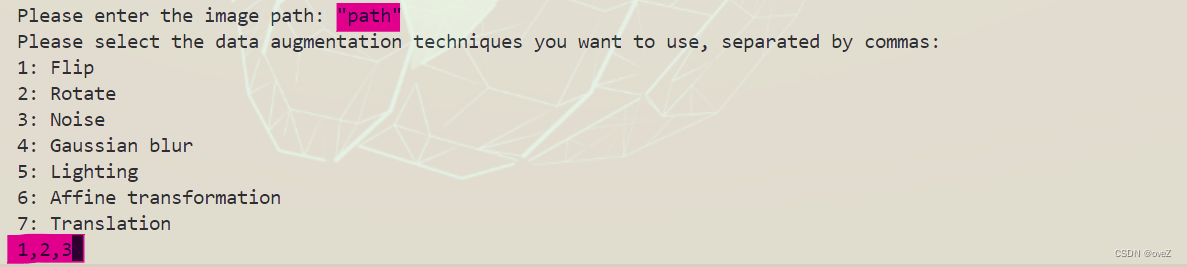
我们只需要输入要处理文件的路径和选择数据增强的序号就行啦~
一些关键部分的实现
crawler_keyword.py
def google_image_scraper(keyword, num_images, save_dir):
# Create Chrome WebDriver instance
driver = webdriver.Chrome()
driver.implicitly_wait(5)
google_image_scraper函数接受关键词(keyword)、图像数量(num_images)和保存目录(save_dir)作为参数。这个函数用于爬取和下载Google图像搜索结果。在函数内部,我们创建了一个Chrome WebDriver实例,并使用implicitly_wait方法设置了一个隐式等待时间,以确保页面加载完成。
# Open Google Image Search page
driver.get("https://www.google.com/imghp")
driver.get方法用于打开指定的URL,这里我们打开了Google图像搜索页面。
from selenium.webdriver.common.by import By
# Locate the search box and enter the keyword
search_box = driver.find_element(By.NAME, "q")
search_box.send_keys(keyword)
search_box.send_keys(Keys.RETURN)
使用driver.find_elements方法和CSS选择器定位到所有的图像元素。然后,我们使用os.makedirs方法创建保存图像的目录。exist_ok=True参数表示如果目录已经存在,不会引发异常。
# Download images
downloaded_images = set()
for i, image in enumerate(images[:num_images]):
try:
image_url = image.get_attribute("src")
image_hash = hashlib.sha256(image_url.encode('utf-8')).hexdigest()
# Check if image has been downloaded
if image_hash in downloaded_images:
print(f"Image {i+1} already downloaded, skipping...")
continue
# Check if image link is https
if not image_url.startswith('https://'):
print(f"Image {i+1} is not from a secure source, skipping...")
continue
image_path = os.path.join(save_dir, f"{keyword}_{i}.jpg")
# Check if file already exists, if so, change filename
counter = 0
while os.path.exists(image_path):
counter += 1
image_path = os.path.join(save_dir, f"{keyword}_{i}_{counter}.jpg")
if image_url.startswith('data:image/jpeg;base64,') or image_url.startswith('data:image/gif;base64,'):
base64_data = image_url.split(',', 1)[1]
image_data = base64.b64decode(base64_data)
with open(image_path, 'wb') as f:
f.write(image_data)
else:
response = requests.get(image_url```
with open(image_path, "wb") as f:
f.write(response.content)
crawler_similar.py
def download_images_from_url(url, num_images, save_dir):
# Create Chrome WebDriver instance
driver = webdriver.Chrome()
driver.implicitly_wait(5)
download_images_from_url函数接受URL(url)、图像数量(num_images)和保存目录(save_dir)作为参数。这个函数用于从给定的URL下载图像。在函数内部,我们创建了一个Chrome WebDriver实例,并使用implicitly_wait方法设置了一个隐式等待时间,以确保页面加载完成。
try:
driver.get(url)
# Get all image elements
images = driver.find_elements(By.CSS_SELECTOR, "img")
# Create directory to save images
os.makedirs(save_dir, exist_ok=True)
使用driver.get方法打开指定的URL。然后,使用driver.find_elements方法和CSS选择器定位到页面上的所有图像元素。我们还使用os.makedirs方法创建保存图像的目录。exist_ok=True参数表示如果目录已经存在,不会引发异常。
# Download images
downloaded_images = set()
for i, image in enumerate(images[:num_images]):
try:
image_url = image.get_attribute("src")
if not image_url:
continue
image_hash = hashlib.sha256(image_url.encode('utf-8')).hexdigest()
# Check if image has been downloaded
if image_hash in downloaded_images:
print(f"Image {i+1} already downloaded, skipping...")
continue
image_save_path = os.path.join(save_dir, f"image_{i}.jpg")
'''剩下的实现就跟crawler_keyword.py差不多'''
遍历图像元素列表,并尝试下载每个图像。先获取图像的URL,并使用哈希函数计算URL的哈希值。如果图像的哈希值已经在downloaded_images集合中,表示该图像已经下载过,就跳过它。然后根据索引和计数器生成图像的保存路径。如果文件已经存在,则增加计数器以避免文件名冲突。
DataAugment.py
def data_augmentation(img, techniques):
img_list = []
if '1' in techniques:
# Flip
img_list.append(cv2.flip(img, 1)) # Horizontal flip
img_list.append(cv2.flip(img, 0)) # Vertical flip
img_list.append(cv2.flip(img, -1)) # Horizontal and vertical flip
data_augmentation函数接受输入的图像和要应用的数据增强技术列表。根据技术列表中的编号,函数将应用不同的数据增强技术。在这种情况下,技术编号1表示翻转操作。通过使用cv2.flip函数,图像将水平翻转、垂直翻转和水平垂直翻转,然后将增强后的图像添加到img_list列表中。
if '2' in techniques:
# Rotate
scale = 1.0
rows, cols = img.shape[:2]
center = (cols / 2, rows / 2) # Image center
angle = [45, 315]
for a in angle:
M = cv2.getRotationMatrix2D(center, a, scale)
rotated = cv2.warpAffine(img, M, (cols, rows), borderValue=(255, 255, 255))
img_list.append(rotated)
技术编号2表示旋转操作。使用cv2.getRotationMatrix2D函数获取旋转矩阵,然后使用cv2.warpAffine函数将图像应用旋转变换,生成旋转后的图像。将增强后的图像添加到img_list列表中。
if '3' in techniques:
# Noise
noise_img = img.copy()
for _ in range(1500):
noise_img[random.randint(0, noise_img.shape[0] - 1)][random.randint(0, noise_img.shape[1] - 1)][:] = 255
img_list.append(noise_img)
技术编号3表示添加噪声操作。首先复制原始图像,然后通过随机选择像素位置并将其设置为白色(255)来添加噪声。这里的噪声是通过在图像上随机选择位置并将其像素值设置为白色来模拟的。将增强后的图像添加到img_list列表中。
if '4' in techniques:
# Gaussian blur
blur1 = cv2.GaussianBlur(img, (9, 9), 1.5)
blur2 = cv2.blur(img, (11, 11), (-1, -1))
img_list.append(blur1)
img_list.append(blur2)
技术编号4表示应用高斯模糊操作。通过cv2.GaussianBlur函数和cv2.blur函数应用不同的模糊核生成模糊后的图像。将增强后的图像添加到img_list列表中。
if '5' in techniques:
# Lighting
contrast = 1 # Contrast
brightness = 100 # Brightness
light1 = cv2.addWeighted(img, contrast, img, 0, brightness)
light2 = cv2.addWeighted(img, 1.5, img, 0, 50)
img_list.append(light1)
img_list.append(light2)
其他三个增强的方式实现的原理类似。
每个脚本详细的运行方式见:readme里的详细说明
使用方法
- 根据需求先运行两个crawler文件,获取数据
- 用数据增强的脚本进行需要的数据增强
- 用Rename.py脚本批量重命名
然后就得到了一个(不错的)数据集,可以去LabelImg里标注啦(打标签…感觉又入了一个大坑😭)















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









