






通过创建类和引用父类完成拟合。
from operator import itemgetter
from pickletools import optimize
import numpy.matlib
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data=torch.Tensor([[1.0,],[2.0],[3.0]])
y_data=torch.Tensor([[2.0,],[4.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=self.linear(x)
return y_pred
model=LinearModel()
criterion=torch.nn.MSELoss(size_average=False)#参数的含义是求取均值,这是损失函数
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#参数1:遍历,寻找权重,参数2:学习率
这是优化器
epoch_l=[]
loss_try=[]
for epoch in range(100):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
epoch_l.append(epoch)
loss_try.append(loss.item())
print(epoch,loss.item())#输出值,没有张量
optimizer.zero_grad()#手动更新权重
loss.backward()
optimizer.step()#更新w
print("w=",model.linear.weight.item())
print("b=",model.linear.bias.item())
x_test=torch.tensor([[4.0]])
y_test=model(x_test)
print("y_pred=",y_test.data)
plt.plot(epoch_l,loss_try)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()这里我修改了epoch,让图像从: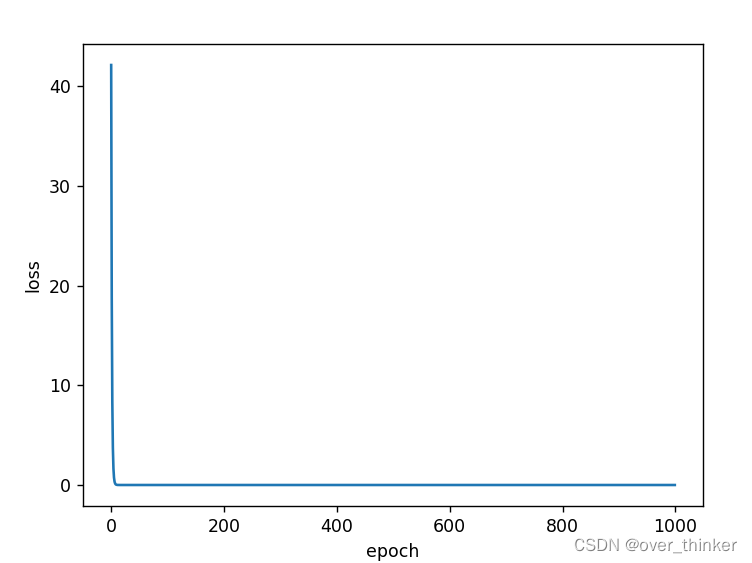
变成 :
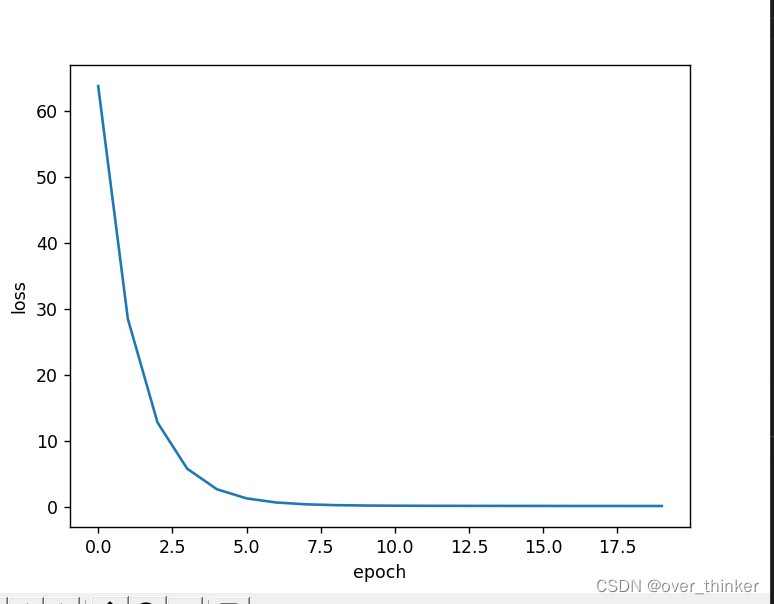
根据作业,我们来观察一下不同优化器的效果。
torch.optim.Adagrad
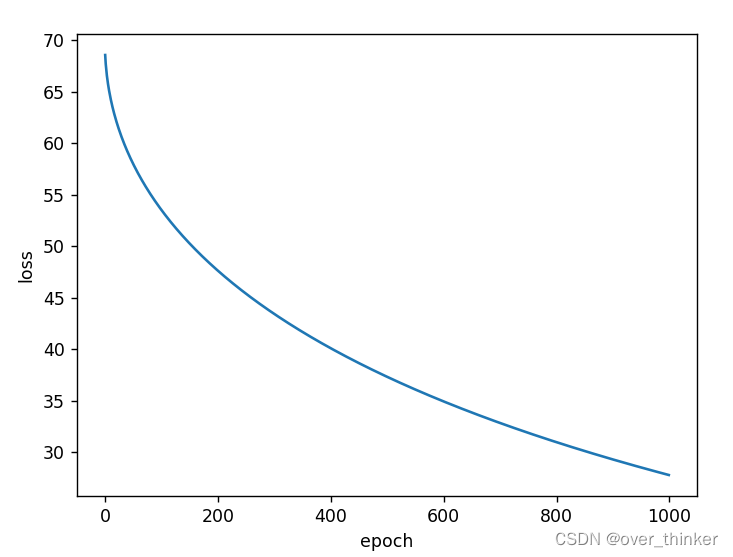
效果不咋地
torch.optim.Adam
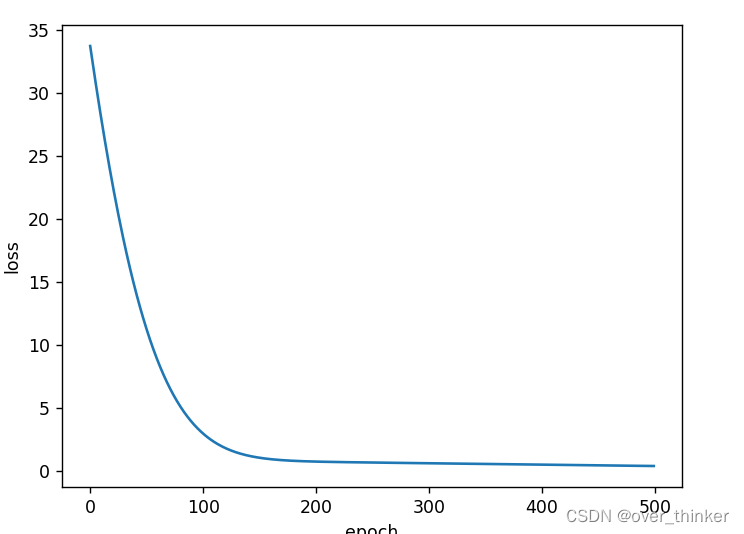 还行,不如第一个。
还行,不如第一个。
torch.optim.Adamax
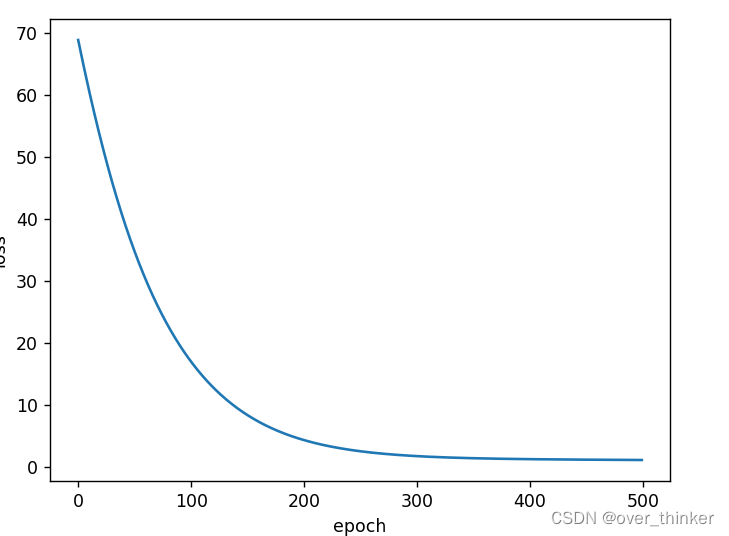
不如上一个。
torch.optim.ASGD
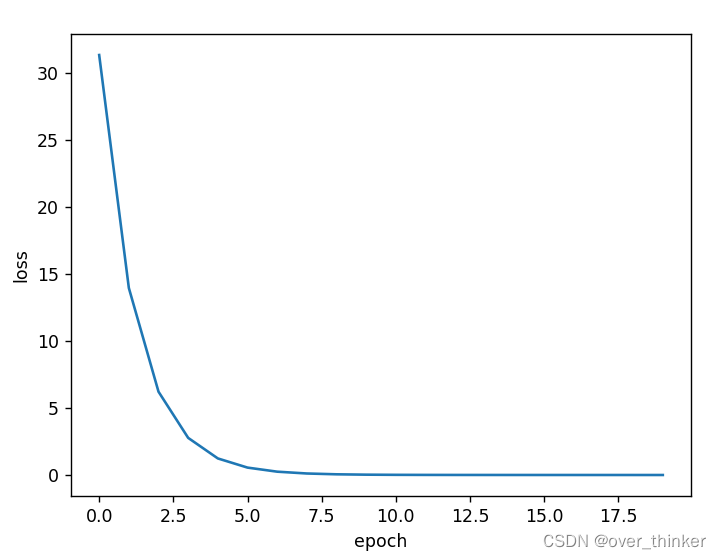
也很不错。
其他的就不重复试了。
补充知识:
1.类与对象的知识,super()
def __init__(self,...):#这里注意下划线是两个。
在创建类时,我们可以手动添加一个 __init__() 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
构造方法用于创建对象时使用,每当创建一个类的实例对象时,Python 解释器都会自动调用它。
另外,__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。也就是说,类的构造方法最少也要有一个 self 参数。
另外,关于self参数--并不非得是self,也可以是别的。
在子类中的构造方法中,调用父类构造方法的方式有 2 种,分别是:
- 类可以看做一个独立空间,在类的外部调用其中的实例方法,可以向调用普通函数那样,只不过需要额外备注类名(此方式又称为未绑定方法);
- 使用 super() 函数。但如果涉及多继承,该函数只能调用第一个直接父类的构造方法。
讲的有一点复杂,其实就是子类和父类中有同名函数时使用父类的函数。
2.nn.linear()
nn.Linear(in_feature,out_feature,bias)
in_feature: int型, 在forward中输入Tensor最后一维的通道数
out_feature: int型, 在forward中输出Tensor最后一维的通道数
bias: bool型, Linear线性变换中是否添加bias偏置
他不讲人话,实际上就是构造w矩阵,让x矩阵在经过运算后能得到y举证。
x_data=torch.Tensor([[1.0,],[2.0],[3.0]])
y_data=torch.Tensor([[2.0,],[4.0],[6.0]])
但这里不能被维度误导了,例如上方,其实可以理解成:将一个列表看成行向量,这就是三个行向量组成的3*1的矩阵 。
但我仍然无法理解这个计算的机制,怎么选取w,b的。没有找到好的博客。
3.backward这函数是反向传播求偏导,但是梯度值在一步loss的时候就已经计算了,所以要清零。














 3625
3625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









