







CTC
ctc可以做到online recognition,它只需要encoder,在进行语音辨识时,要选择一些可以支持online recognition的encoder,例如:单向RNN。
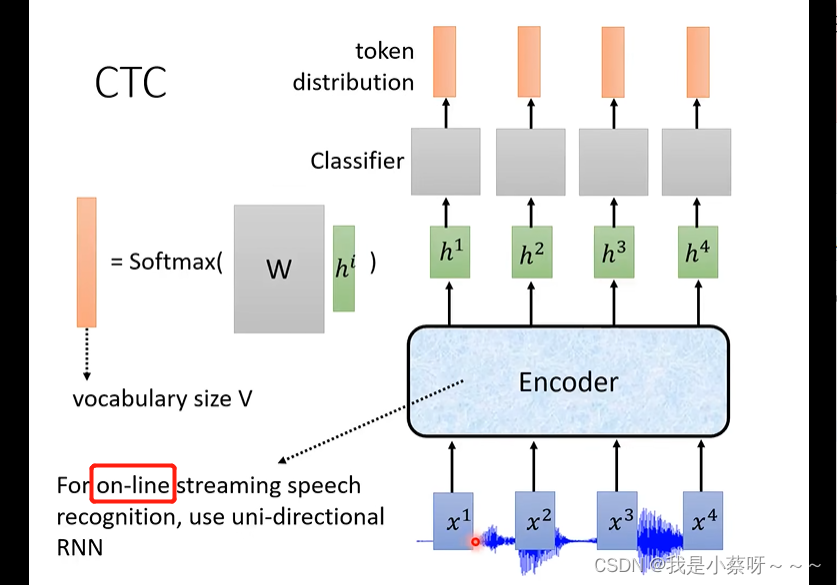
但是输入的x1——声音讯号特征,其frame很小,往往代表了少量信息甚至null,因此较难判断是哪个token,所以在ctc的token中引入了一个null。
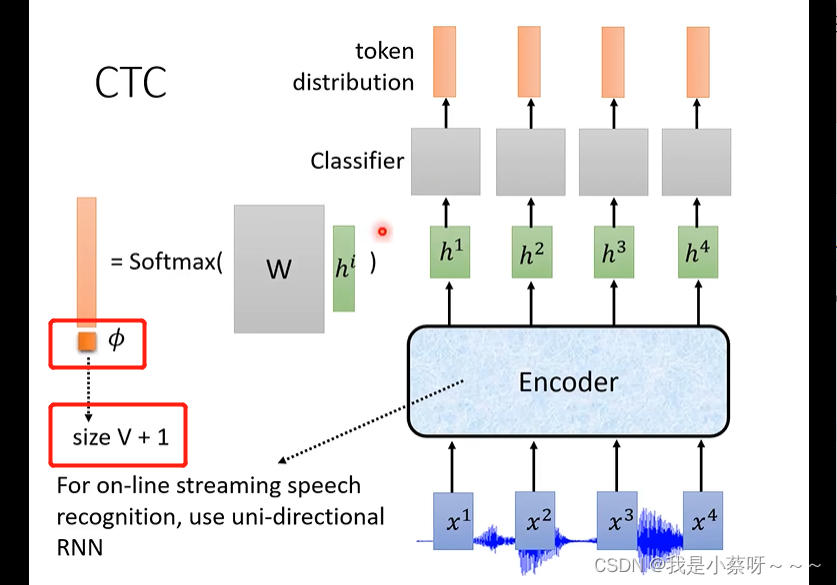
输出中有一部分是null,但实际输出中不能有null,所以ctc会做一下后处理,即合并token,移除null。

怎么训练呢?
question:不知道正确的输出是什么,4个位置应该放什么。
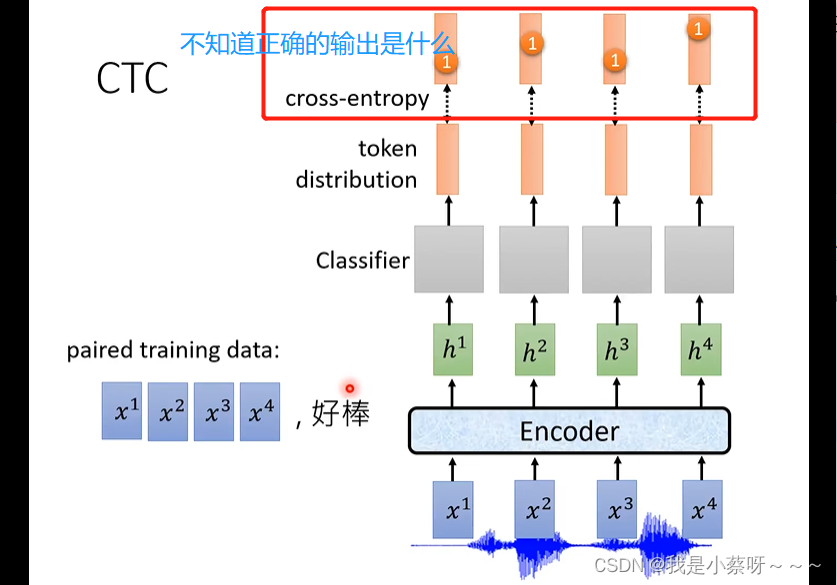
自己制造合适的label,穷举所有的alignment。



来自博客添加链接描述

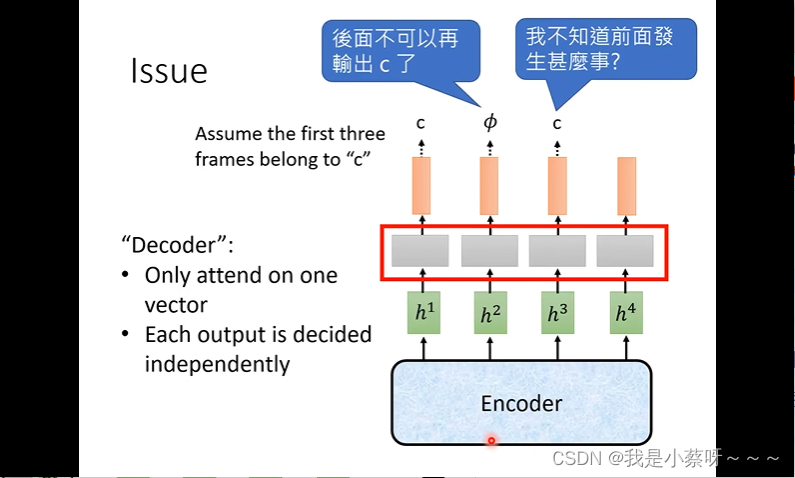
CTC存在的问题
假设前三个frame都是ccc,正常来说是最后输出的是c。但是第二个没识别成功认为它是null,那么前三个frame就是c null c,最后输出就是cc,就结巴了…,但是也没有这么糟糕,我们可以在encoder中做一些处理,比如已经输出c了我们则降低输出c的概率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











