







一、实验介绍
实验室有hadoop集群,想自己装一下在自己电脑玩玩。
知识点
- Hadoop 的体系结构
- Hadoop 的主要模块
- Hadoop 伪分布式模式部署
- HDFS 的基本使用
- WordCount 测试用例
实验环境
- Hadoop-2.6.1
二、Hadoop 简介
Hadoop的框架最核心的设计就是:HDFS和MapReduce。 HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
2.1 核心概念
Hadoop 项目主要包含了以下四个模块:
- Hadoop 通用模块(Hadoop Common): 为其他 Hadoop 模块提供支持的公共实用程序。
- Hadoop 分布式文件系统(HDFS, Hadoop Distributed File System):提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop YARN: 任务调度和集群资源管理框架。
- Hadoop MapReduce: 基于 YARN 的大规模数据集并行计算框架。
对于初次学习 Hadoop 的用户而言,应重点关注 HDFS 和 MapReduce。作为一个分布式计算框架,HDFS 承载了该框架对于数据的存储需求,而 MapReduce 满足了该框架对于数据的计算需求。
下图是 HDFS基本架构。
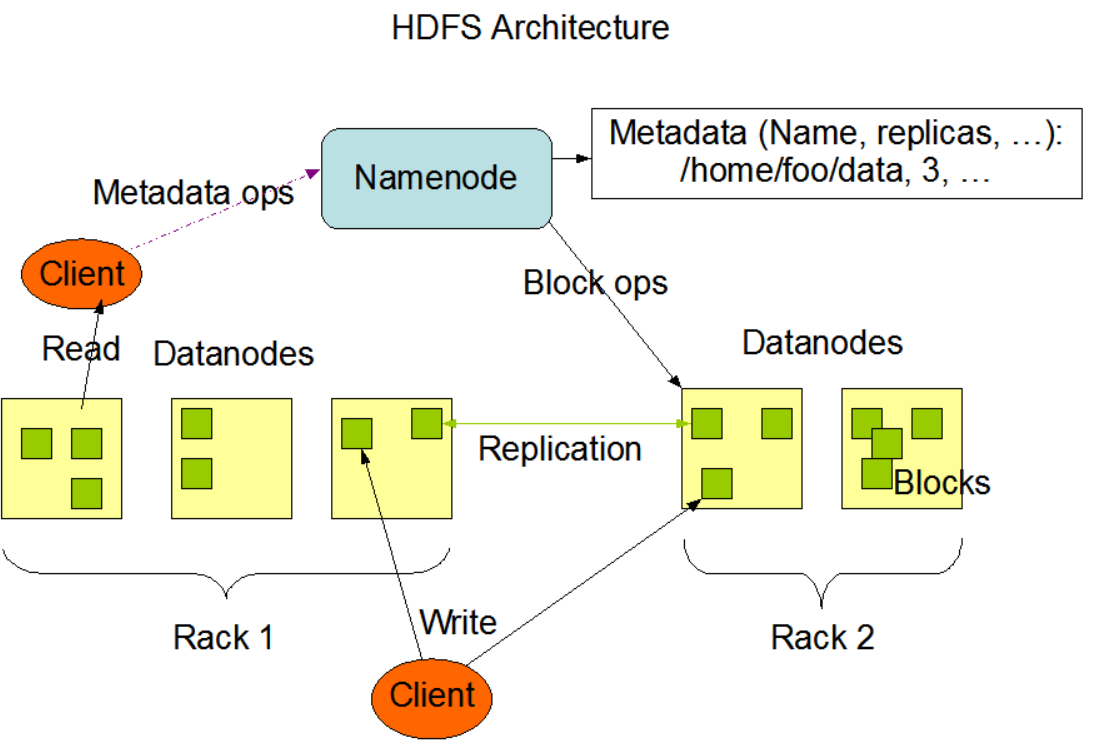
Facebook 对于 Hadoop 的利用主要集中在流式计算和 Java API 的调用。其中最为出名的一个创新便是数据仓库框架—— Hive 。此外,该公司也基于 HDFS 实现了用户空间文件系统(FUSE, Filesystem in Userspace)。
2.2 Hadoop生态体系
如同 Facebook 在 Hadoop 的基础上衍生了 Hive 数据仓库一样,社区中还有大量与之相关的开源项目,下面列出了一些近期比较活跃的项目:
- HBase:一个可伸缩的、支持大表的结构化数据存储的分布式数据库。
- Hive:提供数据汇总和临时查询的数据仓库基础框架。
- Pig:用于并行计算的高级数据流语言和执行框架。
- ZooKeeper:适用于分布式应用的高性能协调服务。
- Spark:一个快速通用的 Hadoop 数据计算引擎,具有简单和富有表达力的编程模型,支持数据 ETL(提取、转换和加载)、机器学习、流处理和图形计算等方面的应用。
以 Hadoop 为起点,陆续展开对相关组件的基本用法介绍。
值得特别关注的是,Spark 这一分布式内存计算框架就是脱胎于 Hadoop 体系的,它对 HDFS 、YARN 等组件有了良好的继承,同时也改进了 Hadoop 现存的一些不足。
部分学习者可能会对 Hadoop 和 Spark 的使用场景重叠产生疑问,但学习 Hadoop 的工作模式和编程模型,将有利于加深对 Spark 框架的理解,这也是本系列课程首先学习 Hadoop 的原因。
三部署Hadoop
对于初学者而言,2.0 版本之后的 Hadoop 差异不大,本节课程将以 2.6.1 版本为例进行讲解。
3.1 Hadoop部署模式介绍
Hadoop 主要有以下三种部署模式:
- 单机模式:在单台计算机上以单个进程的模式运行。
- 伪分布式模式:在单台计算机上以多个进程的模式运行。该模式可以在单节点下模拟“多节点”的场景。
- 完全分布式模式:在多台计算机上分别以单个进程的模式运行。
3.2 设置用户及用户组
双击打开终端,输入以下命令以创建名为 hadoop 的用户:
$ sudo adduser hadoop
并按照提示输入 hadoop 用户的密码,实验楼环境中密码设定为 hadoop 。
随后,将创建好的 hadoop 用户添加进 sudo 用户组,以赋予该用户更高的权限。
$ sudo usermod -G sudo hadoop
3.2 安装依赖环境
3.3.1 安装 JDK
之前安装过jdk,并配好环境了,这里就不操作了
在前文中已经介绍 Hadoop 主要是通过 Java 语言开发的,因此运行它就需要一个 Java 环境。
不同版本的 Hadoop 对 Java 的版本需求有细微的差别,你可以在 Hadoop Wiki 网站的 Hadoop Java Versions 中查看拟使用的 Hadoop 应该选择哪个版本的 JDK 。
通常,实验环境中已经默认配置了 JDK 及其环境变量,输入以下命令来检查 Java 版本是否是需要的:
$ java -version
正常情况下,如果系统中已经配置好了 JDK ,则会看到如下的提示:

如果不是以上提示,则表明需要全新安装 JDK ,可以参考以下命令。
$ sudo add-apt-repository ppa:webupd8team/java -y
$ sudo apt update; sudo apt install -y oracle-java8-installer
$ javac -version
$ sudo apt install -y oracle-java8-set-default
3.3.2 配置 SSH 免密码登录
安装和配置 SSH 的目的是为了让 Hadoop 能够方便地运行远程管理守护进程的相关脚本。这些脚本需要用到 sshd 服务。
在配置时,首先切换到 hadoop 用户。在终端中输入以下命令:
$ su hadoop
若提示输入密码,则输入之前创建用户时填写的密码(hadoop)。
切换用户成功后,命令行提示符应该如上图所示。后续步骤都将以 hadoop 用户的身份来执行相关操作。
接下来生成用于 SSH 免密码登录的秘钥。
所谓“免密码”,是将 SSH 的认证方式由密码登录更改为密钥登录,这样 Hadoop 的各个组件在相互访问时就不必通过用户交互输入密码,能够减少大量冗余操作。
首先切换到用户主目录,然后利用 ssh-keygen 命令来生成 RSA 密钥。
请在终端中输入以下命令:
$ cd /home/hadoop
$ ssh-keygen -t rsa #一路回车
在遇到输入密钥存放位置等信息时,可以直接按回车键使用默认值。
具体操作如下图所示。

随后请继续输入以下命令,将生成的公钥添加到主机认证记录中。为 authorized_keys 文件赋予写权限,否则验证时将无法正确进行。
$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
$ chmod 600 .ssh/authorized_keys
添加成功后,尝试登录到本机。请在终端中输入以下命令:
$ ssh localhost
在第一次登录时会提示是否确认公钥指纹,输入 yes 并确认即可。之后再登录就是免密码的状态了。
3.4配置hadoop
下载hadoop 2.6.1
$ wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.1/hadoop-2.6.1.tar.gz
3.4.2 解压和目录设置
$ tar zxvf hadoop-2.6.1.tar.gz
$ sudo mv hadoop-2.6.1 /opt/hadoop-2.6.1
$ sudo chown -R hadoop:hadoop /opt/hadoop-2.6.1
$ vim /home/hadoop/.bashrc
在 /home/hadoop/.bashrc 文件的末尾添加以下内容:
export HADOOP_HOME=/opt/hadoop-2.6.1
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出 Vim 编辑器,在终端中输入 source 命令来激活新添加的环境变量。
$ source /home/hadoop/.bashrc
3.4.3 伪分布式模式配置
在大多数情况下,Hadoop 都是应用在集群环境中,即我们需要在多个节点上部署 Hadoop 。同时, Hadoop 还可以以伪分布式模式运行在单个节点上,通过多个独立的 Java 进程来模拟多节点的情况。在初始学习阶段,暂时没有必要耗费大量的资源来创建不同的节点,因此本小节及后续的章节将主要采用 伪分布式模式 来进行 Hadoop “集群”的部署。
在终端中使用文本编辑器打开 core-site.xml 文件:
$ vim /opt/hadoop-2.6.1/etc/hadoop/core-site.xml
在该配置文件中,将 configuration 标签的值修改为以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
fs.defaultFS 配置项用于指示集群默认使用的文件系统的位置。
编辑完成后保存并退出,打开另一个配置文件 hdfs-site.xml :
$ vim /opt/hadoop-2.6.1/etc/hadoop/hdfs-site.xml
在该配置文件中,将 configuration 标签的值修改为以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
该配置项用于指示 HDFS 中文件副本的数量,默认情况下是 3 份,由于我们在单台节点上以伪分布式的方式部署,所以将其修改为 1 。
修改完成后保存退出。
接下来,编辑 hadoop-env.sh 文件:
$ vim /opt/hadoop-2.6.1/etc/hadoop/hadoop-env.sh
将其中 export JAVA_HOME 的值修改为 JDK 的实际位置,即 /usr/lib/jvm/java-8-oracle 。
编辑完成后保存并退出 Vim 编辑器。
接下来,编辑 yarn-site.xml 文件:
$ vim /opt/hadoop-2.6.1/etc/hadoop/yarn-site.xml
在 configuration 标签内添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
编辑完成后保存并退出 Vim 编辑器。
最后,需要编辑 mapred-site.xml 文件。首先需要从模板复制过来:
$ cp /opt/hadoop-2.6.1/etc/hadoop/mapred-site.xml.template /opt/hadoop-2.6.1/etc/hadoop/mapred-site.xml
用 Vim 编辑器打开该文件:
$ vim /opt/hadoop-2.6.1/etc/hadoop/mapred-site.xml
同样的,在 configuration 标签内添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑完成后保存并退出 Vim 编辑器。
四、hadoop启动测试
首先打开桌面上的 Xfce终端,切换到 Hadoop 用户下(密码为:hadoop):
$ su -l hadoop #密码为 hadoop
4.1 初始化 HDFS
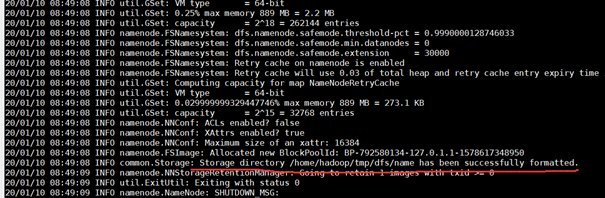
对 HDFS 的初始化主要是格式化。
注意:格式化的操作只需要进行一次即可,不需要多次格式化。每一次格式化 namenode 都会清除 HDFS 分布式文件系统中的所有数据文件。同时,多次格式化容易出现 namenode 和 datanode 不同步的问题。
$ hdfs namenode -format
4.2 启动 HDFS
HDFS 初始化完成之后,就可以启动 NameNode 和 DataNode 的守护进程。启动之后,Hadoop 的应用(如 MapReduce 任务)就可以从 HDFS 中读写文件。
在终端中输入以下命令来启动守护进程:
$ start-dfs.sh
在首次启动时需要确认公钥的指纹,输入 yes 并回车即可。
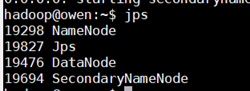
为了确认伪分布式模式下的 Hadoop 已经成功运行,可以利用 Java 的进程查看工具 jps 来查看是否有相应的进程。
在终端中输入以下命令:
$ jps
如图所示,如果看到 NameNode 、DataNode 及 SecondaryNameNode 的进程,则表明 Hadoop 的服务处于正常运行状态。
注意:如果执行 jps 发现没有 NameNode 服务进程,可以先检查一下是否执行了 namenode 的初始化操作。如果没有初始化 namenode ,先执行 stop-dfs.sh ,然后执行 hdfs namenode -format ,最后执行 start-dfs.sh 命令,通常来说这样就能够保证这三个服务进程成功启动
4.3查看日志文件和WebUI
在遇到 Hadoop 无法启动、任务运行期间报错等情况,除了终端的提示信息以外,查看日志是定位问题的最佳方法。根据实验楼大数据相关课程学习者的提问情况来看,绝大多数问题可以通过相关软件的日志查找到原因和解决办法。作为大数据领域的学习者,掌握分析日志的能力与学习相关计算框架的能力同样重要,应当予以重视。
Hadoop 的守护进程日志默认输出在安装目录的 log 文件夹中,在终端中输入以下命令进入到日志目录:
$ cd /opt/hadoop-2.6.1/logs
$ ls
你可以使用 Vim 编辑器来查看任意的日志文件。
HDFS 在启动完成之后,还会由内部的 Web 服务提供一个查看集群状态的网页。点击桌面左下角的任务栏按钮“应用程序菜单”,打开“互联网”菜单下的 Firefox 浏览器,在地址栏中输入以下地址:
http://localhost:50070/
打开网页后,可以在其中查看到集群的概览、DataNode的状态等信息。

你可以随意点击网页上方的菜单来探索其中的提示信息和功能。
4.4 HDFS文件上传测试
HDFS 运行起来之后,可将其视作一个文件系统。此处进行文件上传的测试,首先需要按照目录层级逐个创建目录,并尝试将 Linux 系统中的一些文件上传到 HDFS 中。
$ cd ~
$ hdfs dfs -mkdir /user
$ hdfs dfs -mkdir /user/hadoop
如果需要查看创建好的文件夹,可以使用如下命令:
hdfs dfs -ls /user

目录创建成功之后,使用 hdfs dfs -put 命令将本地磁盘上的文件(此处是随意选取的 Hadoop 配置文件)上传到 HDFS 之中。
$ hdfs dfs -put /opt/hadoop-2.6.1/etc/hadoop /user/hadoop/input
如果要查看上传的文件,可以执行如下命令:
hdfs dfs -ls /user/hadoop/input
4.5WordCount测试用例
可以说,绝大多数部署在实际生产环境并且解决实际问题的 Hadoop 应用程序都是基于 WordCount 所代表的 MapReduce 编程模型变化而来。因此,WordCount既可以作为入门 Hadoop 的 “HelloWorld” 程序,也可以在此基础上加入自己的想法解决具体的问题。
4.5.1 启动任务
在上一节的最后,我们将一些配置文件作为样例上传到了 HDFS 之中,下面我们可以尝试运行 WordCount 测试用例,来对这些文件进行词频统计,并按照我们的过滤规则进行输出。
在终端中首先启动 YARN 计算服务:
$ start-yarn.sh
然后输入以下命令以启动任务(执行如下命令需要等待较长时间,请耐心等待),在这个过程中我们可以看到 map 和 reduce 任务的执行过程:
$ hadoop jar /opt/hadoop-2.6.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount /user/hadoop/input/ output
上述参数中,关于路径的参数有三个,分别是 jar 包的位置、输入文件的位置和输出结果的存放位置。在填写路径时,应当养成填写绝对路径的习惯。这样做将有利于定位问题和传递工作。

4.5.2 查看结果
耐心等待计算完成,然后将 HDFS 上的文件导出到本地目录查看:
$ rm -rf /home/hadoop/output
$ hdfs dfs -get /user/hadoop/output output
导出之后,使用 cat 命令查看文件内容:
$ cat output/*
可以看到输出的文件内容均是以“单词 词频”的组合出现的:

4.5.3 关闭 HDFS 服务
计算完毕后,如无其他软件需要使用 HDFS 上的文件,则应及时关闭 HDFS 守护进程。
作为分布式集群和相关计算框架的使用者,应当养成良好的习惯,在每次涉及到集群开启和关闭、软硬件安装和更新的时候,都主动检查相关软硬件的状态。
在终端中使用以下命令关闭 HDFS 和 YARN 的守护进程:
$ stop-yarn.sh
$ stop-dfs.sh
五、实验总结
本节课程介绍了 Hadoop 的体系结构、伪分布模式的安装部署方法,并运行 WordCount 进行了基本测试。
以下是本节实验主要涉及的知识点:
- Hadoop 的体系结构
- Hadoop 的主要模块
- Hadoop 伪分布式模式部署
- HDFS 的基本使用
- WordCount 测试用例
欢迎关注我的公众号-owen炼丹之路
















 7230
7230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









