






1.虚拟机网络的配置
1.网络的配置
点击vmware的编辑,然后点击虚拟网络编辑器。
![]()
在点击这个更改设置,进入NAT的设置与DHCP设置。

在这里面设置自己的网关192.168.000.2,其中000在每台电脑不一样需要自己去看。
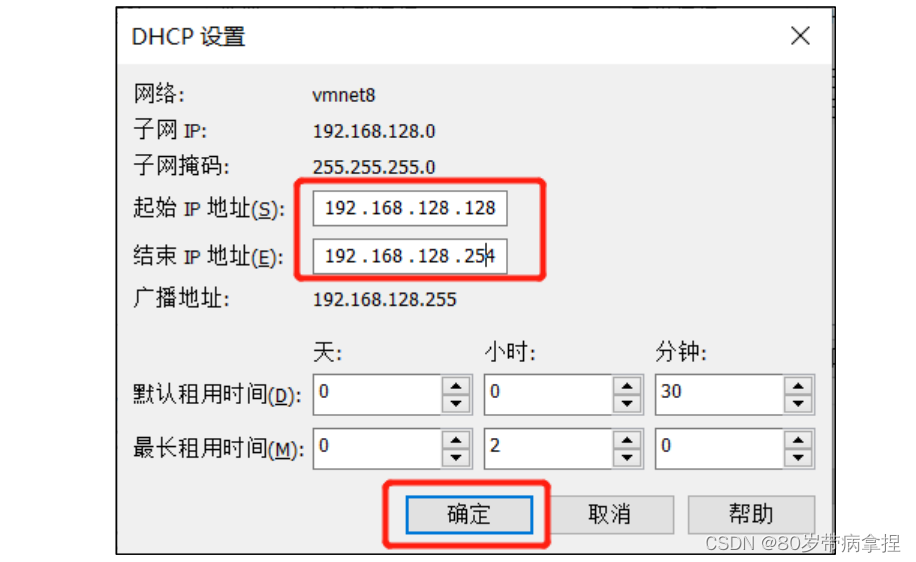
设置 DHCP,192.168.000.128与192.168.000.254.然后点击确定。
![]()
退出后选择应用。这个是给虚拟机联网的
2.ip地址的配置
由于我们每次进去虚拟机ip地址可能不一样,所以我们配置固定的ip地址方便我们远程联机。在虚拟机中我们输入命令来配置ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33在文件中我们我们修改并添加内容 (其中000为自己电脑的,每个人不一样)
#修改:
BOOTPROTO=static
ONBOOT=yes
#添加以下内容
NM_CONTROLLED=no
IPADDR=192.168.000.130
NETMASK=255.255.255.0
GATEWAY=192.168.000.2
DNS=8.8.8.8然后输入命令重启网络然后就能看到我们自己配置的ip地址。
service network restart
ip addr现在我们可以用xshall来远程登录了,对我们的电脑进行配置。
2.hadoop 文件配置
1.yum源的配置
以阿里的yum源来配置为例,因为系统自带的yum源下载可能比较缓慢。先备份系统自己的yum源,然后在下载阿里的yum源作为默认的系统默认yum源 。
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
然后现在下载阿里的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
在这里面要用一个工具wget有的系统可能没有装,在这里面我们就不介绍了。 然后要清除原来的yum缓存,然后生成新的yum缓存。
yum clean all
yum makecache
现在我们配置好一台虚拟机的配置,我们需要克隆出来两台虚拟机来进行集群的搭建。克隆两台以后更改虚拟机的ip。具体参照上面的ip地址配置更改IPADDR=192.168.000.131与192.168.000.132。在重启网络,看ip地址是否改变。然后我们就可以用xshall连接这两台电脑。然后对每台电脑进行改名。
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave22.hadoop的安装与文件配置
1.安装jdk每个节点都要安装
将jdk的安装包传入到虚拟机的/opt目录下面,进入/opt,对jdk进行安装。
rpm -ivh jdk-8u381-linux-x64.rpm注意查看自己的jdk路径,后面很重要。在将hadoop传入master的?opt目录下面,然后进去/opt对hadoop进行解压与安装到/usr/local中。
tar -zxf hadoop-3.1.4.tar.gz -C /usr/local在进入hadoop中对配置文件进行配置
cd /usr/local/hadoop-3.1.4/etc/hadoop/对 core-site.xml文件进行配置vi cor-site.xml。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>对hadoop-env.sh文件进行配置 vi hadoop-env.sh。更改为自己的jdk路径。
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64在对hdfs-site.xml文件进行配置 vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
对yarn-site.xml文件进行配置,注意在后面的/usr/local/hadoop-3.1.4/etc/hadoop每个人的位置不一样需要改!!!!
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.application.classpath </name>
<value>
/usr/local/hadoop-3.1.4/etc/hadoop:/usr/local/hadoop3.1.4/share/hadoop/common/lib/*:/usr/local/hadoop3.1.4/share/hadoop/common/*:/usr/local/hadoop3.1.4/share/hadoop/hdfs:/usr/local/hadoop3.1.4/share/hadoop/hdfs/lib/*:/usr/local/hadoop3.1.4/share/hadoop/hdfs/*:/usr/local/hadoop3.1.4/share/hadoop/mapreduce/lib/*:/usr/local/hadoop3.1.4/share/hadoop/mapreduce/*:/usr/local/hadoop3.1.4/share/hadoop/yarn:/usr/local/hadoop3.1.4/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.1.4/share/hadoop/yarn/*
</value>
</property>
</configuration>在对yarn-env.sh文件进行配置 vi yarn-env.sh中加入jdk的路径
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
在改workers文件删除原来的localhost 添加以下
slave1
slave2在进入启动文件 修改开启与退出命令
cd /usr/local/hadoop-3.1.4/sbin对文件进行编辑vi start-dfs.sh 和 stop-dfs.sh 添加或修改以下
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root对文件进行修改或添加vi start-yarn.sh 和 stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root在配置ip映射vi /etc/hosts中配置。注意这个每个节点都需要配置
192.168.000.130 master
192.168.000.131 slave1
192.168.000.132 slave2将master的配置文件拷贝到slave1与slave2中,拷贝的时候要输入yes与自己的root用户密码
scp -qr /usr/local/hadoop-3.1.4 slave1:/usr/local
scp -qr /usr/local/hadoop-3.1.4 slave2:/usr/local在 /etc/profile中配置hadoop的路径 vi /etc/profile 然后在进行生效 source /etc/profile。
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
export HADOOP_HOME=/usr/local/hadoop-3.1.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin3.配置无密码登录
使用命令生成密钥,以方便虚拟机之间的切换。输入命令以后要按三次enter键;
ssh-keygen -t rsa出现以下界面说明成功生成密钥。
在将生成得密钥复制到三台机器上面去,就可以无障碍切换虚拟机。
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave24.配置时间同步服务
在每个节点都要安装ntp服务用语机器的时间同步。在master节点修改配置vi /etc/ntp.conf 注释掉以 restrict default 开头以及 server 开 头的行,并添加如下内容。
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
同样修改/etc/ntp.conf 文件,注释掉 server 开头的行,并添加如下内容。
server master5.关闭防火墙与开启ntpf服务
执行命令【systemctl stop firewalld.service】关闭防火墙和【systemctl disable firewalld.service】永久性关闭防火墙,主节点和从节点都要关闭。 然后在各个 slave 节点上执行命令【ntpdate master】获取同步时间初值。在各个 slave 节点上执行【systemctl start ntpd.service】和【systemctl enable ntpd.service】即可开启并永久启动 NTP 服务。
6.对namenode节点进行格式化
切记每个集群只需要格式化一次,如果多次格式化可能造成datanode不能启动。注意在启动hadoop的时候要切换到bin目录下面 ,在格式化的时候会提示成功,不成功多半是配置文件出错误。
cd /usr/local/hadoop-3.1.4/bin
./hdfs namenode -format在master节点中启动集群,这个是分别启动两个集群。当然也可以自己全部启动./start-all.sh
./start-dfs.sh
./start-yarn.sh在使用jps查看进程有没有启动,因为配置的节点在不同的电脑上面要是更改了配置文件可能这里显示不同。

7.对本地电脑进行映射配置
在 Windows 下 C:\Windows\System32\drivers\etc\hosts 添加 IP 映射。这里面输入cmd在以管理员运行。这样在web界面才能看到我们搭建的集群。
192.168.000.130 master
192.168.000.131 slave1
192.168.000.132 slave2现在可以在web界面看到我们的集群了,hdfs的端口为9870,yarn的端口号为8088
http://master:9870
http://master:8088
关闭集群的命令与打开类似:
./stop-yarn.sh
./stop-dfs.sh现在我们的第一个集群就搭建好啦!当然在搭建的过程中可能会遇到各种各样的错误,学会看日志会极大的帮助你解决问题。














 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









