







 本文深入解析了Linux内核中的task_struct结构,详细介绍了其作为进程描述符的角色,并通过list_entry函数演示了如何从任务队列中获取下一个进程。
本文深入解析了Linux内核中的task_struct结构,详细介绍了其作为进程描述符的角色,并通过list_entry函数演示了如何从任务队列中获取下一个进程。
以task_struct 为例来看
/task_struct 进程描述符***************/
struct task_struct {
volatile long state;
void *stack;
atomic_t usage;
unsigned int flags;
unsigned int ptrace;
……
struct list_head tasks; //任务队列
……
}
struct list_head {
struct list_head *next, *prev;
};
/******list_entry 函数使用(获取链表中的下一个进程)/
struct task_struct *task;
list_entry(task->tasks.next, struct task_struct, tasks)
/list_entry 源码**********************/
#define list_entry(ptr, type, member) container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
offsetof(TYPE,MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
//list_head是任务队列,所有的tasks都挂在上面,linux 内核链表中,不是在链表结构中包含数据,而是在数据结构中包含链表节点 list_head,链表结构如下图(原谅我拙劣的画图技术 ̄□ ̄||)
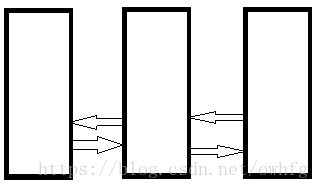
注意:这里的链表并不是指向下一个或者上一个元素的首地址。
看到这个结构,就可以想象怎么获得下一个表首地址,先获取下一个表的list_head元素地址,然后找到元素相对于表首地址的偏移量,元素地址—偏移量 就是首地址。
下面来说源码实现过程:
&((TYPE *)0)->MEMBER:
//把“0”强制转化为指针类型,则该指针一定指向“0”地址因为指针是“type *”型的,所以可取到以“0”为基地址的一个type型变量member域的地址。那么这个地址也就等于member域到结构体基地址的偏移字节数。
//也就是获得tasks成员相对于task_struct结构体首地址的地址偏移量
//再来看 ((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member))):
*****//(char *)(ptr)使得指针的加减操作步长为一字节,(unsigned long)(&((type *)0)->member)等于ptr指向的member到该member所在结构体基地址的偏移字节数。二者一减便得出该结构体的地址。转换为 (type *)型的指针,大功告成。
//也就是说获得tasks变量的地址,再减去偏移量,即得到task_struct结构体的首地址
//这样就通过链表节点得到了数据结构的地址

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









