







leveldb中的Cache类是一个抽象类,主要定义了针对缓存操作的虚函数接口。通过引入相应的缓存替换策略,可以提高缓存数据在内存中的查找命中率,最大限度减少在外存储器中的查找过程,提高数据库的查询效率。
leveldb内建了基于LRU策略的ShardedLRUCache类作为Cache抽象类的默认实现,下面将分别介绍Cache抽象类和ShardedLRUCache类,并详细分析ShardedLRUCache类的具体实现方式以及包含的LRUCache和HandleTable类。
首先,来看cache抽象类的主要代码,以及阅读代码过程对注释的翻译:
leveldb-1.9.0\include\leveldb\cache.h
// A Cache is an interface that maps keys to values. It has internal
// synchronization and may be safely accessed concurrently from
// multiple threads. It may automatically evict entries to make room
// for new entries. Values have a specified charge against the cache
// capacity. For example, a cache where the values are variable
// length strings, may use the length of the string as the charge for
// the string.
//
// A builtin cache implementation with a least-recently-used eviction
// policy is provided. Clients may use their own implementations if
// they want something more sophisticated (like scan-resistance, a
// custom eviction policy, variable cache sizing, etc.)
//一个Cache是一个从key到value的映射接口。它有内部的同步机制并实现了安全地多线程并发访问
//它可以通过自动排除旧条目为新条目分配空间。Values对于Cache容量有一个指定的控制管理。
//例如,一个存储变长度字符串values的cache可以用这个字符串长度作为对这个字符串的管理。
//
//leveldb提供了一个基于LRU的内置cache实现。也可以根据自己的复杂场景需求来实现自己的cache。
//例如,反扫描策略,变长缓存分配策略
#ifndef STORAGE_LEVELDB_INCLUDE_CACHE_H_
#define STORAGE_LEVELDB_INCLUDE_CACHE_H_
#include <stdint.h>
#include "leveldb/slice.h"
namespace leveldb {
class Cache;
// Create a new cache with a fixed size capacity. This implementation
// of Cache uses a least-recently-used eviction policy.
//
//创建一个新的固定容量的Cache。这个Cache的实现利用了LRU策略。具体见 leveldb-1.9.0\util\cache.cc
extern Cache* NewLRUCache(size_t capacity);
class Cache {
public:
Cache() { }
// Destroys all existing entries by calling the "deleter"
// function that was passed to the constructor.
//通过调用在构造函数中传入的deleter()函数,可以销毁所有已经存在的所有cache条目
virtual ~Cache();
// Opaque handle to an entry stored in the cache.
//handle对存储在Cache里的条目是不透明的,它是对外的接口。
struct Handle { };
// Insert a mapping from key->value into the cache and assign it
// the specified charge against the total cache capacity.
//
// Returns a handle that corresponds to the mapping. The caller
// must call this->Release(handle) when the returned mapping is no
// longer needed.
//
// When the inserted entry is no longer needed, the key and
// value will be passed to "deleter".
//插入一个KV映射到cache并从总的容量里分配指定的内存开销。
//
//返回一个与映射相对应的handle。当这个返回的映射不再需要时,
//这个调用者必须调用this->Release(handle)释放。
//
//当这个插入的条目不再需要时,这个key和value将会被传递给deleter函数销毁。
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) = 0;
// If the cache has no mapping for "key", returns NULL.
//
// Else return a handle that corresponds to the mapping. The caller
// must call this->Release(handle) when the returned mapping is no
// longer needed.
//如果这个cache中不存在当前查询的“key”时,返回NULL。
//否则返回一个与映射相对应的handle。当这个返回的映射不再需要时,
//这个调用者必须调用this->Release(handle)释放。
virtual Handle* Lookup(const Slice& key) = 0;
// Release a mapping returned by a previous Lookup().
// REQUIRES: handle must not have been released yet.
// REQUIRES: handle must have been returned by a method on *this.
//释放由之前Lookup()函数返回的映射。
//要求:handle必须是还没有被释放。
//要求:handle必须是由方法*this返回的。
virtual void Release(Handle* handle) = 0;
// Return the value encapsulated in a handle returned by a
// successful Lookup().
// REQUIRES: handle must not have been released yet.
// REQUIRES: handle must have been returned by a method on *this.
//返回包裹在handle中的Value,该hanle由成功查询函数Lookup()返回。
///要求:handle必须是还没有被释放。
//要求:handle必须是由方法*this返回的。
virtual void* Value(Handle* handle) = 0;
// If the cache contains entry for key, erase it. Note that the
// underlying entry will be kept around until all existing handles
// to it have been released.
//
//如果当前cache包含对应key的条目,就清除它。
//请注意,潜在的条目将会保留,直到所有的现有的handles被释放
virtual void Erase(const Slice& key) = 0;
// Return a new numeric id. May be used by multiple clients who are
// sharing the same cache to partition the key space. Typically the
// client will allocate a new id at startup and prepend the id to
// its cache keys.
//
//返回一个新的数值ID。可以被用于共享同一个缓存的多个客户端来划分key空间。
//典型的客户端在启动时会分配一个新的id并追加这个id到它的缓存key表中。
virtual uint64_t NewId() = 0;
private:
void LRU_Remove(Handle* e);//从LRU表中删除handle节点e
void LRU_Append(Handle* e);//向LRU表中添加handle节点e
void Unref(Handle* e);//减少handle节点e的引用数
struct Rep;//
Rep* rep_;
// No copying allowed
//不允许复制,参数为const
Cache(const Cache&);
void operator=(const Cache&);
};
} // namespace leveldb
#endif // STORAGE_LEVELDB_UTIL_CACHE_H_
以上就是Cache类的抽象接口,接下来看具体实现。
leveldb在util中实现了基于LRU策略LRUCache类。它的具体结构如下图所示,
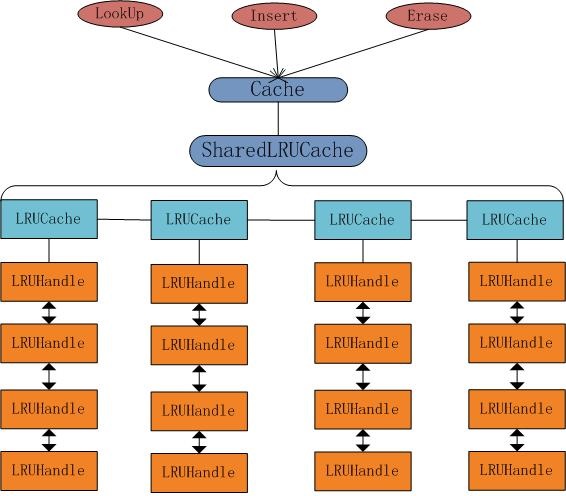
Cache抽象类调用Cache* NewLRUCache(size_t capacity) 函数,返回一个Cache*指向SharedLRUCache对象。SharedLRUCache对象中维护了一个LRUCache对象数组,每个LRUCache指向一个双向循环链表,节点元素为LRUHandle。
针对cache.h中的NewLRUCahce(size_t capacity)函数声明
extern Cache* NewLRUCache(size_t capacity);Cache* NewLRUCache(size_t capacity) {
return new ShardedLRUCache(capacity);
}
主要函数列表如下:
private:
static inline uint32_t HashSlice(const Slice& s);//私有内联函数,用来计算key的hash值
static uint32_t Shard(uint32_t hash);//根据hash值来计算当前缓存在shard_数组中的存放位置
public:
explicit ShardedLRUCache(size_t capacity);//ShardedLRUCahce的显式构造函数
virtual ~ShardedLRUCache();//析构函数
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));//插入一条KV条目
virtual Handle* Lookup(const Slice& key);//查找key值
virtual void Release(Handle* handle);//释放handle
virtual void Erase(const Slice& key);//清除对应key的条目
virtual void* Value(Handle* handle);//得到handle中的Value
virtual uint64_t NewId();//
在实现ShardedLRUCache前,当前匿名空间域中引入了两个静态常量,设置存放缓存分段数量
static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits;//将1左移4位,得到值为16private:
LRUCache shard_[kNumShards];//定义<span style="font-family: Arial, Helvetica, sans-serif;">LRUCache 数组</span>shard_[16]
port::Mutex id_mutex_;//互斥量
uint64_t last_id_;//64位无符号整形private:
static inline uint32_t HashSlice(const Slice& s) {//私有内联函数,用来计算key的hash值
return Hash(s.data(), s.size(), 0);//Hash函数,计算Slice对象s的hash值,具体实现见leveldb-1.9.0\include\leveldb\hash.cc
}
static uint32_t Shard(uint32_t hash) {
return hash >> (32 - kNumShardBits);//取hash的高4位,最大为15
}public:
explicit ShardedLRUCache(size_t capacity)//explicit 构造函数传参只能显示调用
: last_id_(0) {//初始化last_id_=0
const size_t per_shard = (capacity + (kNumShards - 1)) //设置shard_数组的每个元素大小为capacity+(kNumShards - 1),
for (int s = 0; s < kNumShards; s++) {
shard_[s].SetCapacity(per_shard);//设置每个LRUCache元素的内存空间
}
}
virtual ~ShardedLRUCache() { }
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
const uint32_t hash = HashSlice(key);//先计算key的hash值
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter);//调用私有函数Shard(hash),得到hash值的高4位,即决定了该KV条目存放入shard_数组中的元素位置
}
virtual Handle* Lookup(const Slice& key) {
const uint32_t hash = HashSlice(key);//计算key的hash值
return shard_[Shard(hash)].Lookup(key, hash);//调用LRUCache的Lookup()函数,查找当前key值,并返回对应的LRUHandle
}
virtual void Release(Handle* handle) {//释放LRUHandle的空间
LRUHandle* h = reinterpret_cast<LRUHandle*>(handle);
shard_[Shard(h->hash)].Release(handle);
}
virtual void Erase(const Slice& key) {//清楚指定的KV条目值
const uint32_t hash = HashSlice(key);
shard_[Shard(hash)].Erase(key, hash);
}
virtual void* Value(Handle* handle) {//得到LRUHandle的Value值
return reinterpret_cast<LRUHandle*>(handle)->value;
}
virtual uint64_t NewId() {//用户的访问ID,多用户访问同一个缓存时,追加在key值上
MutexLock l(&id_mutex_);
return ++(last_id_);
}接着就来分析LRUCache类的具体实现过程
LRUCache类的变量和函数列表如下:
public:
LRUCache();
~LRUCache();
void SetCapacity(size_t capacity) { capacity_ = capacity; }//设置LRUCache的内存空间大小
Cache::Handle* Insert(const Slice& key, uint32_t hash,
void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));//插入一条KV数据
Cache::Handle* Lookup(const Slice& key, uint32_t hash);//查找指定的key
void Release(Cache::Handle* handle);//释放查找返回的LRUHandle
void Erase(const Slice& key, uint32_t hash);//清楚该KV值
private:
void LRU_Remove(LRUHandle* e);//内部私有函数移除LRUHandle
void LRU_Append(LRUHandle* e);//添加最新的LRUHandle
void Unref(LRUHandle* e);//解引用
size_t capacity_;//内存容量
port::Mutex mutex_;//互斥量
size_t usage_;//使用量
uint64_t last_id_;//访问ID
LRUHandle lru_;//lru.prev是最新的条目,lru.next是最少使用的条目
HandleTable table_;//存粗LRUHandle*指针的hash表LRUCache::LRUCache()//构造函数
: usage_(0),
last_id_(0) {
lru_.next = &lru_;//作为双向循环链表lru_的头结点,它的两个LRUHandle*成员变量prev和next初始化指向自己
lru_.prev = &lru_;
}Cache::Handle* LRUCache::Insert(//插入
const Slice& key, uint32_t hash, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
MutexLock l(&mutex_);//互斥同步
LRUHandle* e = reinterpret_cast<LRUHandle*>(
malloc(sizeof(LRUHandle)-1 + key.size()));//分配节点的堆空间大小为sizeof(LRUHandle)-1 + key.size()
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->refs = 2; // 此时保存两个引用,一个是LRUCache,一个是返回的Handle指针
memcpy(e->key_data, key.data(), key.size());//将整个字符串复制给key_data
LRU_Append(e);//完成节点的数据值初始化后,调用LRU_Append函数,将<span style="font-family: Arial, Helvetica, sans-serif;">该节点作为最新节点,</span>添加到双向循环链表中。
usage_ += charge;//计算当前内存利用率
LRUHandle* old = table_.Insert(e);//将节点指针插入或更新到table_
if (old != NULL) {//old不为NULL时,从双向循环链表中移除该节点,并释放该节点的空间
LRU_Remove(old);
Unref(old);
}
while (usage_ > capacity_ && lru_.next != &lru_) {//容量溢出检测,当超过cache的容量时,根据LRU策略删除最后的节点
LRUHandle* old = lru_.next;//得到此时双向循环链表中lru_.next始终指向的最后节点
LRU_Remove(old);//先从链表中移除old节点
table_.Remove(old->key(), old->hash);//从table链表中移除old
Unref(old);//
}
return reinterpret_cast<Cache::Handle*>(e);
}而LRU_Append函数是如何将当前节点作为最新节点加入到双向循环链表中的呢,实现方式如下:
void LRUCache::LRU_Append(LRUHandle* e) {//添加新节点
// Make "e" newest entry by inserting just before lru_
//最新的条目总是添加到lru_的前面,即lru_.prev指向最新节点
e->next = &lru_;
e->prev = lru_.prev;
e->prev->next = e;
e->next->prev = e;
}
由上图,每次新插入的节点时,操作过程如下:先给节点的前后指针赋值,接着再给让前一个节点的next指针指向自己,让后一个节点的prev指针指向自己。其中lru_节点的prev指针始终指向最近使用节点,next指针始终指向最少使用节点。
除了插入新的节点外,另一种情况也要考虑到LRU策略,那就是查找命中。如果执行查找操作且在当前缓存中找到了该节点,则需要更新被找到的节点到最新的位置,即lru_.prev指向被找到的节点。查找代码如下:
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
LRUHandle* e = table_.Lookup(key, hash);
if (e != NULL) {
e->refs++;
LRU_Remove(e);//找到e,更新e节点的前后节点指针指向
LRU_Append(e);//更新到双向链表最前
}
return reinterpret_cast<Cache::Handle*>(e);
}void LRUCache::LRU_Remove(LRUHandle* e) {
e->next->prev = e->prev;
e->prev->next = e->next;
}
LRUCache中还需要注意的另一方面是关于节点的引用计数问题。它的析构函数在循环释放每个LRUHandle节点前,要保证对该节点的引用为且仅为1,如下:
以上就是LRUCache的主要介绍,接下来分析由hash值和key值的组成的HashTable。
LRUCache::~LRUCache() {
for (LRUHandle* e = lru_.next; e != &lru_; ) {
LRUHandle* next = e->next;
assert(e->refs == 1); // Error if caller has an unreleased handle
Unref(e);
e = next;
}
}
解引用函数Unref(LRUHandle* e)在调用过程会判断是否满足删除该节点的条件,如果e->refs<=0,则调用e的deleter函数,删除该KV条目。为何e->refs存在小于0的情况,应该是为了并发情况考虑。
e->refsvoid LRUCache::Unref(LRUHandle* e) {//解引用函数
assert(e->refs > 0);
e->refs--;
if (e->refs <= 0) {
usage_ -= e->charge;
(*e->deleter)(e->key(), e->value);
free(e);
}
}
HashTable维持了一个满足hash值到LRUHandle指针映射关系的动态扩容数组。
数组元素是LRUHandle*,可以看作是存储KV条目的指针。其中,
LRUHandle的构造如下:
struct LRUHandle {//双向循环链表中节点数据结构
void* value;
void (*deleter)(const Slice&, void* value);//指向函数deleter的指针
LRUHandle* next_hash;//节点不为NULL时的再次hash后的指针
LRUHandle* next;//后指针
LRUHandle* prev;//前指针
size_t charge; // TODO(opt): Only allow uint32_t?//?
size_t key_length;
uint32_t refs; //该对象被引用的个数,无符号32位整形
uint32_t hash; // Hash of key(); used for fast sharding and comparisons//hash的key值,用于快速分页和比较
char key_data[1]; // Beginning of key//key的开头。再有key_length可得到整个key
Slice key() const {//将该节点存储的value转换成Slice返回
//为了更方便地查找,我们准许在“value”中有一个临时的Handle对象来存储一个指向key的指针
if (next == this) {//next指向自己,即仅存在lru_节点
return *(reinterpret_cast<Slice*>(value));//将value由void*转换成Slice*,并取值,返回。
} else {
return Slice(key_data, key_length);//返回包装key的Slice
}
}
};
LRUHandle作为数据存储节点,保存有Key值和Value值,它在LRUCache中赋值,并在堆中分配存储空间,基于LRU策略建立起缓存数据的双向循环链表。而HandleTable负责查找和维护各节点的指针,方便LRUCache的查找调用。
HandleTable的构造函数如下:
HandleTable() : length_(0), elems_(0), list_(NULL) { Resize(); }//构造函数,初始化长度,元素,和链表
~HandleTable() { delete[] list_; }//LRUHandle** list_;list_数组元素为LRUHandle*
HashTable类的构造函数中调用了它的成员函数Resize(),来更新数组长度,初始length_=4。
HashTable类中的Hash查找函数是FindPointer(const Slice& key,uint32_t hash),该函数在当前Hash表中查找满足条件的节点指针。
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];//hash值和最大下标做与运算,取hash值的低4位,得到对应的数组下标号
while (*ptr != NULL &&
((*ptr)->hash != hash || key != (*ptr)->key())) {//遍历出hash值或key值相同的ptr
ptr = &(*ptr)->next_hash;
}
return ptr;
}
当HashTable进行插入操作后,需要对当前的数组空间进行判断,若元素数量超过数组长度时,执行Resize()函数,对HandleTable进行扩容。
LRUHandle* Insert(LRUHandle* h) {//插入节点LRUHandle*
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == NULL ? NULL : old->next_hash);//若不为NULL,更新h的next_hash,h覆盖old
*ptr = h;//将h节点指针赋值给*ptr,
if (old == NULL) {//此处原来为空,元素个数增加
++elems_;
if (elems_ > length_) {//超出当前最大长度,扩容Resize()
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;//返回原来位置的节点指针或NULL,old位置被更新后,要释放掉。
}void Resize() {//hash表增大
uint32_t new_length = 4;
while (new_length < elems_) {
new_length *= 2;//长度按照2的倍数递增,直至new_length>elems
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {//将原数据重新hash
LRUHandle* h = list_[i];
while (h != NULL) {
LRUHandle* next = h->next_hash;
Slice key = h->key();
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_;//释放原链表
list_ = new_list;
length_ = new_length;
}














 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









