










24年6月来自清华、上海AI实验室、西工大、浙大和中国电讯的论文“Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration”。
由于物理世界的复杂性,将大语言模型 (LLM) 的推理能力应用于具身任务具有挑战性。特别是,多智体协作的 LLM 规划需要智体之间的沟通或信用分配作为反馈,重新调整所提出的规划并实现有效的协调。然而,现有的过度依赖物理验证或自我反思的方法,会受到 LLM 查询过度和效率低下的影响。本文提出一种用于多智体协作的框架,引入强化优势 (ReAd) 反馈有效地自我完善规划。具体来说,执行批评回归从 LLM 规划的数据中学习顺序优势函数,然后将 LLM 规划器视为优化器,生成最大化优势函数的操作。它赋予 LLM 远见,辨别该动作是否有助于完成最终任务。将强化学习中的优势加权回归扩展到多智体系统,提供理论分析。在 Overcooked-AI 和 RoCoBench 一个难度大变型的实验表明,ReAd 在成功率上超越了基线,并且显著减少了智体的交互步骤和 LLM 的查询轮次。
大语言模型 (LLM) 已在多个领域展现出卓越的能力,包括长文本理解、推理和文本生成 [13, 47, 6, 48]。得益于从网络上挖掘出的大规模文本语料库,LLM 可以吸收和捕获有关世界的大量知识以供决策制定。最近的研究表明,LLM 可以通过零样本或少样本示例提示以交互方式做出决策,通过思维链 (CoT) [61] 或思维树 [67] 规划来解决具身任务 [18]。然而,LLM 仅使用其内部知识进行规划,由于缺乏复杂具身智体的任务特定知识,这些知识通常不以物理世界为基础。这样的问题可能导致推理中的事实幻觉和无意义的指令解释问题 [2]。为了防止 LLM 在具身任务中输出不可行的规划,现有方法大多为交互过程设计一个带反馈的闭环框架。具体而言,一条研究路线采用自我反思,通过 LLM 进行自我评估来改进 LLM 规划器的规划生成结果 [51, 68, 21, 40];另一条研究路线利用外部环境的反馈进行物理验证,根据意外反馈动态地重规划 [26, 53]。然而,这些反馈往往是稀疏的或启发式的,基于 LLM 具身任务规划的更有原则反馈机制,仍然处于缺乏的状态。
考虑到多智体环境中更具挑战性的规划问题,基于 LLM 的智体需要通过沟通和协商与其他智体合作,这给有效反馈带来了更多困难。具体而言,自我反思和物理验证都很难评估个体行为对多智体团队结果的影响。因此,反馈机制要么受到 LLM 过多查询的影响,要么与物理环境频繁交互。例如,RoCo [42] 引入物理验证作为反馈,在多智体协作环境中改进 LLM 生成的动作,但面临效率低下的难题。如图所示,RoCo 需要过多的交互来获得物理反馈,并向 LLM 查询以获得可行的联合行动规划,这对于具体化任务来说效率极低。
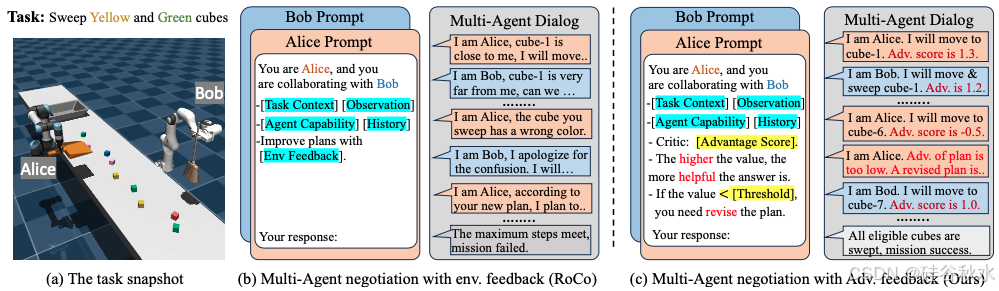
相比之下,多智体强化学习 (MARL) [74] 中的各种方法,已经开发出用于多智体信用分配(credit assignment)的价值或优势(advantage)分解理论 [49, 29],这些理论提供了有效的机制来评估单个动作在完成最终任务中的贡献,并可以生成动作进行单调策略改进 [30]。受这些原则的启发,提出一个问题:“如何在 MARL 的理论支持下增强 LLM 在具体化多智体协作中的推理能力?” 目标是利用多智体优势函数构建一种高效的反馈和改进算法,用于 LLM 辅助的多智体规划。
相关工作
在大型语料库上训练的 LLM [10, 45, 55, 56] 通过上下文学习表现出显著的推理能力 [14, 1, 3]。然而,由于缺乏现实世界的知识,LLM 也可能为具身智体提供不可行的规划。一系列研究通过自我评估和反思将开环规划框架修改为闭环框架。例如,ReAct [68]、Reflexion [51] 和 BeamSearch [65] 在上一个规划完成后将来自 LLM 评估者的反馈纳入提示中。其他研究将具身智体的域知识融入反馈中。例如,RoCo [42] 和 Inner Monologue [26] 设计了物理验证,如碰撞检查、物体识别和场景描述以供反馈。DoReMi [20] 利用 LLM 生成物理约束,而 ViLA [23] 采用视觉-语言模型 (VLM) 作为约束检测器进行验证。另一项研究开发了高级推理框架,包括思维链 [61, 43] 和思维树 [67]。[75, 21] 等研究将 LLM 视为世界模型 [37],并在规划中采用树搜索 [22]。其他研究采用规划域定义语言 (PDDL) 进行长期问题的搜索 [52, 39, 76]。
带有人类反馈的 RL (RLHF) 已被用于通过参数调整使 LLM 与人类偏好保持一致 [12, 17, 54]。先前的研究尝试在树搜索框架 [7] 下将 RL 集成到 LLM 规划中。例如,FAFA [40] 和 TS-LLM [16] 学习环境模型和价值函数来规划 MCTS 中的子程序。REX [44] 提出在基于 LLM 的 MCTS 中平衡探索和利用。SayCan [2] 和 Text2Motion [38] 等其他研究采用无模型方式,通过学习价值函数将 LLM 知识与物理环境联系起来。SwiftSage [35] 进行模仿学习以实现快速思考,而 LLM 则进行有条不紊的训练。 Remember [72] 学习价值函数,以便 LLM 通过提示中的样本预测 Q 值并根据 Q 值选择操作。
强化优势 (ReAd) 反馈作为多智体协作中 LLM 的一个闭环反馈。提供两种可选的 LLM 生成规划细化方案,包括具有局部优势的顺序个体规划细化(称为 ReAd-S)和具有联合优势的联合规划细化(称为 ReAd-J)。其中, (i) ReAd-J 评估联合动作的优势函数,这需要 LLM 同时生成所有智体的联合规划。相比之下,(ii) ReAd-S 遵循 MARL 中的多智体优势分解原则 [29] 来评估每个智体动作的局部优势,这允许 LLM 按顺序为每个智体生成动作。这两个优势函数均由回归 LLM 规划数据的评论网络做估计。基于优势函数,LLM 规划器被用作优化器,提示生成最大化优势值的动作。否则,如果优势值很小,则需要 LLM 规划器重规划。将优势加权回归 [46] 扩展到多智体设置,为此类过程提供了理论动机。
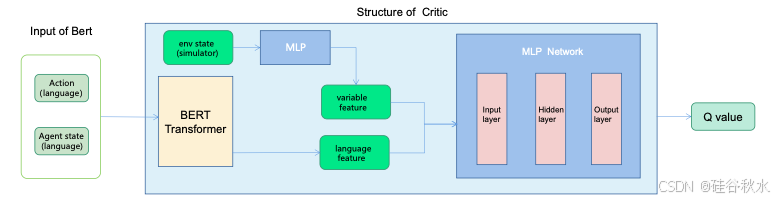
评论家学习从数据集中估计状态-动作对的价值函数。状态包括环境状态和智体状态,其中环境状态包含模拟器的变量,智体状态用语言描述。动作也用语言描述。采用预先训练的 BERT Transformer 模型来提取智体状态和动作的语言特征。然后,将输出特征与环境状态特征连接到一些 MLP 层,预测 Q-值。评论家网络的结构如图所示:
如下算法 1 是 Critic regression:评论家回归

如下算法 2 是ReAd-S:具有局部优势的顺序个体规划细化

如下算法 3 是 ReAd-J:具有联合优势的联合规划细化

如图所示是提示和细化的概述。对于每个时间步 t,LLM 规划器都会获得历史记录,其中包含状态、动作和优势,并被提示生成具有最高优势的规划。预先训练的评论家用于评估生成的动作 ait 得分 SReAd(ait)。如果 SReAd(ait) < ε,这个失败的规划用作一个提示,并要求 LLM 规划器细化策略,直到 SReAd(ait) > ε。(细化的)动作用于与环境交互,LLM 规划器在下一步中进行处理。

RoCoBench 由桌面操作环境中的 6 个多机器人协作任务组成,通常涉及 LLM 在语义上易于理解和推理的交互式目标。这些任务涵盖了一系列需要机器人进行通信和协调行为的协作场景。机器人接收观察并从高级动作集中选择一个动作,该动作集包括跨多个任务的各种功能,例如等待、移动、扫动、抓取和放下。高级动作的执行随后被转换为用于操作的低级动作。与主要关注具有固定难度级别的任务的 RoCoBench 相比,本文选择三个任务来丰富基准的复杂性并创建新的 DV-RoCoBench,其中每个任务都针对实验量身定制 4-5 个难度级别:
- Sweep Floor 扫地。两个机械臂需要协同工作,将桌子上的所有立方体扫入垃圾箱。目标是扫除具有给定颜色的立方体。根据总体立方体数量和目标立方体建立 5 个难度级别。LLM 规划器在更困难的环境中更有可能产生事实幻觉。
- Make Sandwich 做三明治。两个机械臂需要堆叠配料,根据食谱制作三明治。每个手臂的操作范围有限,需要智体之间的合作。根据食谱的长度建立 4 个难度级别。
- Sort Cubes 分类立方体。需要三个在其操作范围内的机械臂来协调并将立方体放在桌子上的目标位置。根据立方体与其目标位置之间的距离建立 5 个不同的难度级别。
Overcooked-AI [8] 是一个全合作的多智体基准环境,基于广受欢迎的视频游戏 Overcooked。在这个环境中,智体需要尽快送汤。每道汤都需要在锅中放入最多 3 种配料,等待汤煮熟,然后让智体拿起汤并送上来。该环境由 5 种不同的厨房场景组成,涵盖从低层运动协调挑战到高层策略协调挑战。在实验中,选择两个代表性场景:Cramped Room 狭窄房间 和 Forced Coordination 强制协调,并将制作汤的配料数量设置为 2,烹饪的时间步长设置为 2。为了能够计算成功率,将 DV-RoCoBench 中每集的最大环境步骤数设置为 15,将狭窄房间中的最大环境步骤数设置为 20,将强制协调中的最大环境步骤数设置为 25。除了方块分类之外所有任务(扫地、做三明治、Cramped Room 和 Forced Coordination)每步重规划的最大轮数都设置为 10,其他都设置为 15。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









