








前言
首先感谢各位看官的关注!!!
上文链接:(12条消息) 【python养成】:re模块正则表达式详解_嵌入式up的博客-CSDN博客
继上文我们讲解了正则表达式的基础知识,本文根据案例测试结果给大家看,大学根据测试结果可以更好的了解正则表达式的使用。本文参考科班书籍教程,以保证内容质量!
一、正则表达式
正则表达式是字符串处理的有力工具和技术,是使用某种预定义的模式去匹配一类具有共同特征的字符串,主要用于处理字符串,可以快速、准确地完成复杂的查找和替换等处理要求,在文本编辑与处理、大数据分析、网络爬虫的场合有重要用途!
正则表达式主要是使用 Python中的 re模块。
Python中字符串前⾯加上 r 表示原⽣字符串。
最简单的正则表达式是普通字符串,可以匹配自身
如果以"\"开头的元字符与转义字符相同,则需要使用"\\"或者原始字符串,在字符串前加上字符r或R。原始字符串可以减少用户的输入,主要用于正则表达式和文件路径字符串,如果字符串以一个"\"结束,则需要多写一个"\",以"\\"结束。
二、案例教程
Python 中字符串的前导
r代表原始字符串标识符,该字符串中的特殊符号不会被转义,适用于正则表达式中繁杂的特殊符号表示。print('\n') print(r'\n')运行结果示例:

'[pjc]ython' : 可以匹配'python'、'jython'、'cython'
import re #引用re模块 text = 'Python python pyythn jython cython abcd' a = re.findall('[pjc]ython',text) # findall:返回字符串中模式的所有匹配项组成的列表 print(a)运行结果示例:
'[a-zA-Z0-9]' :可以匹配一个任意大小写字母或数字
import re #引用re模块 text = '、、、abcd|||BBBB【【【000' a = re.findall('[a-zA-Z0-9]',text) # findall:返回字符串中模式的所有匹配项组成的列表 print(a)运行结果示例:
'[^abc]' :可以一个匹配任意除'a'、'b'、'c'之外的字符
import re #引用re模块 text = 'abcd000' # 反向字符集,匹配除abc之外的单个任何字符 a = re.findall('[^abc]', text) # findall:返回字符串中模式的所有匹配项组成的列表 print(a)运行结果示例:
'python|perl' 或 'p(ython|erl)':可以匹配'python'或'perl'
'[Pp]ython' :匹配 "Python" 或 "python"
import re #引用re模块 text = 'abcd000pythoncccperlPython' a = re.findall('python|perl', text) # findall:返回字符串中模式的所有匹配项组成的列表 b = re.findall('p(ython|erl)', text) # 以p开头在其中二选一 c = re.findall('[Pp]ython', text) # 匹配 "Python" 或 "python" print(a) print(b) # 为啥像print(a)显示 是因为print输出的第二轮的数据 第一轮是跟print(a)一模一样的 print(c)运行结果示例:

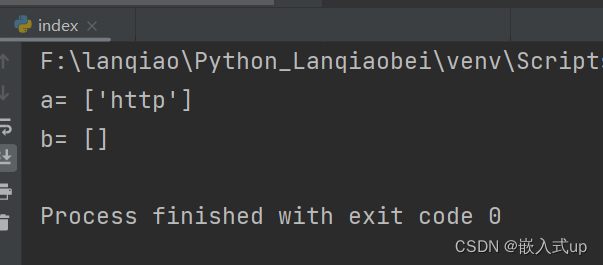
r'(http://)?(www\.)?python\.org' :只能匹配
" 'http://www.python/org'\n" " 'http://python.org'\n" " 'python.org'\n" " 'www.python.org'\n"运行结果示例:
'^http' :只能匹配所有以'http'开头的字符串
import re #引用re模块 text = 'http123;;;;' text1 = 'ddhttpfff' # '^http' :只能匹配所有以'http'开头的字符串 a = re.findall('^http', text) # findall:返回字符串中模式的所有匹配项组成的列表 b = re.findall('^http', text1) print("a=", a) print("b=", b)运行结果示例:
(pattern)* :允许模式重复0次或多次
(pattern)+ :允许模式重复1次或多次
(pattern){m,n} :允许模式重复m~n次
(pattern){,n} :允许模式最多重复n次,最少0次
(pattern){m,} :允许模式最少重复m次,不限制最多重复次数
{m,n}:匹配的模式串至少重复m次,最多重复n次,如果没有m则等同于m=0,没有n则等同于n为无穷大。如a{,5}等同于a{0,5}表示a最多重复5次,可以一次也不出现。{m,n}这种匹配修饰符是贪婪模式的重复匹配,即尽可能按最大值n进行重复匹配。import re #引用re模块 text = 'http1231;;1 1 1 1;;' # '^http' :只能匹配所有以'http'开头的字符串 a = re.findall('(1)*', text) # findall:返回字符串中模式的所有匹配项组成的列表 b = re.findall('(1)+', text) ''' {m,n}:匹配的模式串至少重复m次,最多重复n次,如果没有m则等同于m=0,没有n则等同于n为无穷大。 如a{,5}等同于a{0,5}表示a最多重复5次,可以一次也不出现。 {m,n}这种匹配修饰符是贪婪模式的重复匹配,即尽可能按最大值n进行重复匹配。''' c = re.findall('(1){0,3}', text) print("a=", a) print("b=", b) print("c=", c)运行结果示例:

'(a|b)*c' :匹配多个(包含0个)a或b,后面紧跟一个字母c。
import re #引用re模块 text = 'acbc;;1 1 1 1;;' a = re.findall('(a|b)*c', text) # findall:返回字符串中模式的所有匹配项组成的列表 print("a=", a)运行结果示例:

'ab{1,}' :等价于'ab+',匹配以字母a开头后面带1个至多个字母b的字符串。
import re #引用re模块 text = 'abababbbb;;1 1 1 1;;' a = re.findall('ab{1,}', text) # findall:返回字符串中模式的所有匹配项组成的列表 print("a=", a)运行结果示例:

'^[a-zA-Z]{1}([a-zA-Z0-9._]){4,19}$' :匹配长度为5-20的字符串,必须以字母开头并且可带字母、数字、“_”、“.”的字符串。
运行结果示例:
注:a= ['c'] 是因为寻找成功,最后判断到最后一个字符串 c 遍历
'^(\w){6,20}$' :匹配长度为6-20的字符串,可以包含字母、数字、下划线。
运行结果示例:

















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











