






hadoop集群配置
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
一、Linux系统安装
centOS7、hadoop-3.3.6、jdk-8u411-linux-x64
linux系统安装
yum install vim
1、 firewall命令
systemctl status firewalld #查看防火墙状态
systemctl start firewalld.service #打开防火墙
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙
二、JDK&&Hadoop安装
1、解压jdk&&hadoop
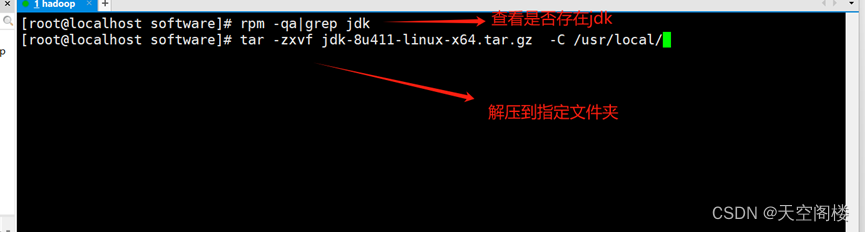
2、增加环境变量 (vim /etc/profile)

3、重新加载使其生效 (source /etc/profile)
三、准备环境
1、确保防火墙是关闭状态
2、确保NAT模式和静态IP的确定 (192.168.XXX.XXX)
3、确保/etc/hosts文件里,ip和hostname的映射关系

4、确保免密登陆localhost有效
ssh-keygen -t rsa #生成公钥和私钥
ssh-copy-id 主机名 #将公钥和私钥copy到对应主机
#(每个主机都需要进行此操作,包含自身)
5、保证集群之间时间一致
6、jdk和hadoop的环境变量配置
四、修改hadoop的配置文件并启动集群
1、修改配置文件
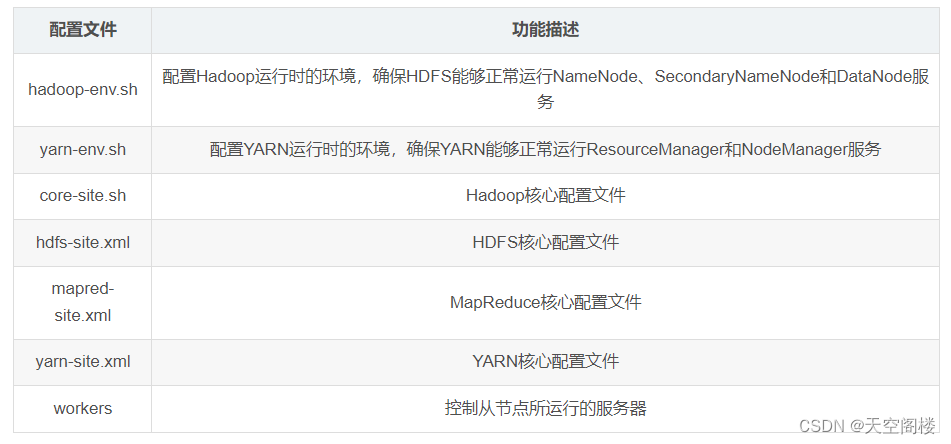
1.1、core-site.xml
<configuration>
<!--设置namenode节点-->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.4.0/tmp</value>
</property>
<!-- 指定通过Web UI访问HDFS的用户root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 允许任何服务器的root用户可以向Hadoop提交任务 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 允许任何用户组的root用户可以向Hadoop提交任务 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 指定HDFS中被删除文件的存活时长为1440秒 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
1.2、hdfs-site.xml
<configuration>
<!-- 副本数量(默认3防止数据丢失) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
</configuration>
1.3、hadoop-env.sh (hadoop运行配置)
export JAVA_HOME=/usr/local/jdk1.8.0_411
#Hadoop3中,需要添加郊下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
1.4、works(haoop1和2中叫 slaves)
hadoop01
hadoop02
hadoop03
1.5、在hadoop1进行配置后通过远程copy直接发送给hadoop2和hadoop3:包含 profile文件,hadoop、jdk
# -r 递归向下 (同步环境变量后重新加载环境变量)
scp -r /usr/local/hadoop-3.3.6 root@hadoop02:/usr/local
scp -r /usr/local/hadoop-3.3.6 root@hadoop03:/usr/local
scp -r /usr/local/jdk1.8.0_411 root@hadoop02:/usr/local
scp -r /usr/local/jdk1.8.0_411 root@hadoop03:/usr/local
scp /etc/profile root@hadoop02:/etc
scp /etc/profile root@hadoop03:/etc
2、启动集群
2.1、格式化集群
注意事项:
我们在core-site.xm1中配置过hadoop.tmp.dir的路径,在集群格式化的时候需要保证在这个路径不存在!如果之前存在数据。先将其删除(rm -rf 文件名称(其中-r向下递归 -f直接删除)),再进行格式化
hdfs namenode -format
2.2 启动集群
启动集群后可通过jps命令查看正在运行JAVA相关进程信息
start-dfs.sh #启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh #停IHDFS所有进程(NameNode、SecondaryNameNode、DataNode)
# hdfs --daemon start 单独启动一个进程
hdfs --daemon start namenode #只开启NameNode
hdfs --daemon start secondarynamenode #只开启SecondaryNameNode
hdfs --daemon start datanode #只开启DataNode
# hdfs --daemon stop 单独停止一个进程
hdfs --daemon stop namenode #只停止上NameNode
hdfs --daemon stop secondarynamenode #只停止上SecondaryNameNode
hdfs --daemon stop datanode #只停止上DataNode
#hdfs--workers --daemon start 启动所有的指定进程
hdfs --workers --daemon start datanode #开启所有节点上的DataNode
#hdfs--workers --daemon stop 停止所有的指定进程
hdfs --workers --daemon stop datanode #停止所有节点上的DataNode
2.3 多节点进程查看脚本
#1、创建脚本
vim /usr/local/hadoop-script.sh
#2、增加如下内容
#!/bin/bash
HOSTS=( hadoop01 hadoop02 hadoop03 )
for HOST in ${HOSTS[*]}
do
echo "---$HOST---"
ssh -T $HOST << DELIMITER
jps | grep -iv jps # 过滤jps节点
exit
DELIMITER
done
#3、授权并将文件软链接到usr/bin,或者将文件添加到环境变量中
sudo chmod 777
ln -s /usr/local/hadoop-script.sh /usr/bin
#4、执行查看所有节点下的java相关进程
[root@hadoop01 local]# hadoop-script.sh
---hadoop01---
12721 DataNode
12600 NameNode
---hadoop02---
2379 DataNode
2447 SecondaryNameNode
---hadoop03---
11644 DataNode















 7287
7287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









