






HDFS介绍
HDFS块(默认128M)
当然块大小在默认配置文件hdfs-default.xml中有相关配置,我们可以在hdfs-site.xml中进行重置
<property>
<name>dfs.blocksize</name>
<value>134217728</valme>
<description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写):k,m,g,t,p,e 以重新指定大小(例如128k,512m,
1g等)</description>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1048576</value>
<description>以字节为单位的最小块大小,由Namenode在创建时强制执行时间。这可以防止意外创建带有小块的文件降低性能
</description)
</property>
<property>
<name>dfs.namenode.fs-limits.max-blocks-per-file</name>
<value>1048576x</value>
<description>每个文件的最大块数,由写入时的Namenode执行。这可以防止创建降低性能的超大文件</description>
</property>
<!--确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
HDFS 体系结构

1、HDFS进程之NameNode
1、namenode进程只有一个(HA高可用除外)
2、管理HDFS的命名空间,并以fsimage和edit进行持久化保存。
3、在内存中维护数据块的映射信息
4、实施副本冗余策略
5、处理客户端的访问请求
2、HDFS进程之DataNode
1、存储真正的数据(块进行存储)
2、执行数据块的读写操作
3、心跳机制(3秒)
3、HDFS进程之SecondaryNamennode
1、帮助NameNode合并fsimage和edits文件
2、不能实时同步,不能作为热备份节点
4、HDFS的Client接口
1、HDFS实际上提供了各种语言操作HDFS的接口。
2、与NameNode进行交互,获取文件的存储位置(读/写两种操作)
3、与DataNode进行交互,写入数据,或者读取数据
4、上传时分块进行存储,读取时分片进行读取
5、fsimage和edits
fsimage 会定时检查点的文件系统树和整棵树内部的所有文件和目录的元数据。在两段时间间隔内,会将客户端所有操作信息添加到edits日志文件中
edits 客户端的所有更新操作(如打开、关闭、创建、删除、重命名等)

5.1、fsimage
命名空间镜像文件,它是文件系统元数据的一个完整的永久检查点,内部维护的是最近一次检查点的文件系统树和整棵树内部的所有文件和目录的元数据,如修改时间,访问时间,访问权限,副本数据,块大小,文件的块列表信息等等。
fsimage默认存储两份,是最近的两次检查点。
可使用XML格式查看fsimage文件:
hdfs oiv -i【fsimage xxxxxxx】-o 【目标文件路径(xml文件)】-p XML
## 案例如下:
hdfs oiv -i fsimage_00000000052 -o ~/fs52.xml -p XML
5.2、edits(日志文件)
集群正常运行时,客户端的所有更新操作(如打开、关闭、创建、删除、重命名等)除了在内存中维护外,还会被写到edit日志文件中,而不是直接写入fsimage映像文件。
因为对于分布式文件系统而言,fsimage映像文件通常都很庞大,如果客户端所有的更新操作都直接往fsimage文件中添加,那么系统的性能一定越来越差。相对而言,edit日志文件通常都要远远小于fsimage,一个edit日志文件最大64M,更新操作写入到EditLog是非常高效的。
那么edit日志文件里存储的到底是什么信息呢,我们可以将edit日志文件转成xm1文件格式,进行查看。
##查看editlog文件的方式:
hdfs oev -i【edits_inprogress_xxx】-o【目标文件路径(xml文件)】-p XML
6、DataNode与NameNode通信(心跳机制)
1、hdfs是master/slave结构,master包括namenode和resourcemanager,slave包括datanode和nodemanager
2、master启动时会开启一个IPC服务,等待slave连接
3、slave启动后,会主动连接IPC服务,并且每隔3秒链接一次,这个时间是可以调整的,设置heartbeat,这个每隔一段时间连接一次的机制,称为心跳机制。slave通过心跳给master汇报自己信息,master通过心跳下达命令。
4、namenode通过心跳得知datanode状态。Resourcemanager通过心跳得知nodemanager状态
5、当master长时间没有收到slave信息时,就认为slave挂掉了。
注意: 超长时间计算结果:默认为10分钟30秒
在hdfs-site.xml文件中进行相关配置
1、属性:dfs.namenode.heartbeat.recheck-interval 的默认值为5分钟 #Recheck的时间单位为毫秒
2、属性:dfs.heartbedt.interval 的默认值时3秒 #heartbeat的时间单位为秒
计算公式:2*recheck+10*heartbeat
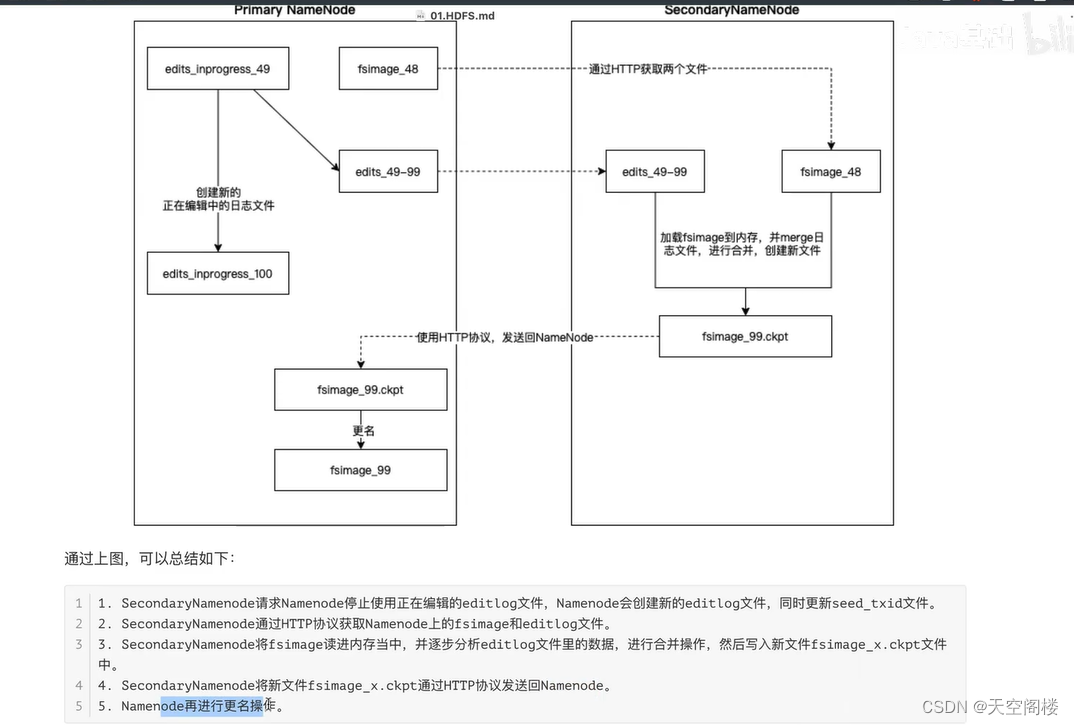
7、SecondaryNamenode工作机制(检查点机制)
SecondaryNamenode 是HDFs集群中的重要组成部分,它可以辅助Namenode进行fsimage和editlog的合并工作,减小editlog文件大小,以便缩短下次Namenode的重启时间,能尽快退出安全模式。两个文件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-site.xml配置文件进行修改的
以下为默认配置(hdfs-default.xml)
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>两次检查点间隔的秒数,默认是1个小时</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>txid(事务)执行的次数达到100w次,也执行checkpoint</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>60秒一检查txid的(事务)执行次数</description>
</property>
HDFS 高级操作
1、磁盘检测
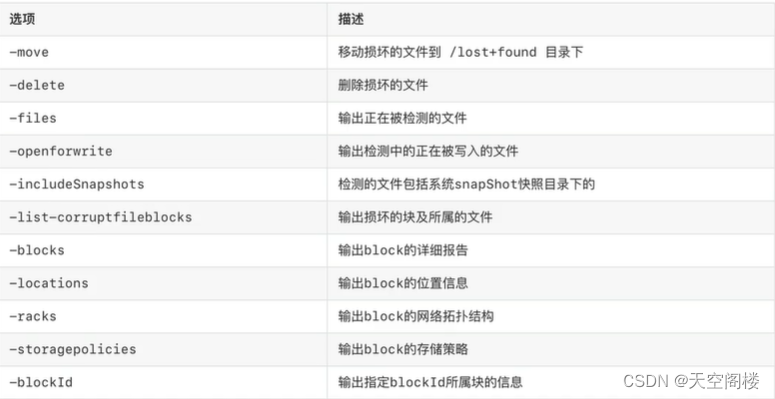
使用命令 fsck 进行磁盘检测
hdfs dfs -mkdir /test #创建test文件夹
hdfs dfs -put /home/software/hadoop-3.3.6.tar.gz /test #上传文件
hdfs dfs -put /home/software/jdk-8u411-linux-x64.tar.gz /test #上传文件
hdfs fsck /test #检测test文件夹下文件是否完整
hdfs fsck /test -files #检测完成性并输出文件信息
hdfs fsck /test -files -blocks #检测完成性并输出文件&块信息
hdfs fsck /test -files -blocks -locations #检测完成性并输出文件&块信息&存储信息
hdfs fsck /test -files -blocks -list-corruptfileblocks #检测文件中损坏的块信息
2、动态上线(扩容)
动态增加datanode节点实现扩容
2.1、准备工作
1、设置 IP 地址为 192.168.80.104
2、设置 hostname为hadoop04
3、设置防火墙关闭
4、设置时间同步
5、安装 JDK 并设置 JDK 的环境变量 (可以直接从已有节点拷贝)
6、安装好 Hadoop 并设置 Hadoop 的环境变量 # hadoop必须通过安装进行,不要通过copy
2.2、在hadoop01节点进行修改操作,添加对hadoop04的host映射,并同步给每一个节点
#1、编辑 hadoop01 节点上的 /etc/hosts 文件,添加映射
192.168.80.104 hadoop04
# 2、分发给其他的节点
scp /etc/hosts hadoop02:/etc
scp /etc/hosts hadoop03:/etc
scp /etc/hosts hadoop04:/etc
2.3、设置hadoop01到hadoop04节点的免密登录
#将 hadoop01节点生成的公钥拷贝到 hadoop04节点
ssh-copy-id hadoop04
2.4、修改 hadoop01节点上的 Hadoop 配置文件中的 workers 文件,添加 hadoop04
# 编辑 workers 文件
vim /usr/local/hadoop-3.3.6/etc/hadoop/workers
#添加hadoop04
2.5、将编辑之后的 workers 文件分发到 hadoop02和 hadoop03节点
cd /usr/local/hadoop-3.3.6/etc/hadoop
scp workers hadoop02:$PwD
scp workers hadoop03:$PWD
2.6、将 hadoop01节点的 Hadoop 的配置文件直接拷贝到 hadoop04节点
cd /usr/local/hadoop-3.3.6/
scp -r etc hadoop04:$PwD
2.7、在 hadoop04节点启动 DataNode
hdfs --daemon start namenode
3、动态下线
节点的动态下线比起动态上线来说。稍微麻烦一些。因为动态下线的时候需要提前将数据移动到其他节点才可以。Hadoop 虽然提供了动态下线的功能,但是有一个前提条件就是需要再在hdfs-site.xml文件中配置属性: dfs.hosts.exclude。这个属性的值需要指向一个文件,也就是需要下线的文件。也就是一个黑名单,在这个文件中的机器,会被 NameNode 移除集群。
但是这个hdfs-site.xml文件修改之后是需要重启集群才生效的。因此在生产环境中,我们需要提前将这个属性配置好,因为生产环境中的集群是不允许随意的关闭、重启的。在我们学习阶段就简单很多了,我们直接修改这个文件,然后重启集群即可。
3.1、修改 hadoop01 节点的 hdfs-site.xml 文件
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop-3.3.6/etc/hadoop/exclude</value>
</property>
3.2、创建这个 exclude 文件
#这个文件是一个黑名单文件,为了操作起来方便、合理,我们将它放在 Hadoop 的配置文件目录中
touch /usr/local/hadoop-3.3.6/etc/hadoop/exclude
3.3、重启HDFS集群
stop-dfs.sh
start-dfs.sh
3.4、.动态下线过程
3.4.1 将需要下线的节点,添加到exclude文件中
vim /usr/local/hadoop-3.3.6/etc/hadoop/exclude
#添加hadoop04
注意事项:下线之后的节点数量、不能少于副本数量。例如副本因子为 3、在线的节点数量是小于等于 3 的,此时是无法下线的,如果需要下线的话,需要修改副本数之后再下线。
3.4.2、刷新节点(需要在 NameNode 节点操作)
hdfs dfsadmin -refreshNodes
3.4.3、WebUI可查看节点状态
此时hadoop04节点状态会变为Decommissioning。当节点数据被copy到其他节点后,节点状态会修改为Decommissioned
3.4.4、退役完成,此时我们就可以放心的停止 hadoop04节点上的服务了1
hdfs --daemon stop namenode
3.4.5、其他的节点的数据如果不均衡的话,使用 balancer 命令平衡一下即可
hdfs balancer
注:
如果这个节点下线之后,从此就不再使用了。我们可以修改 workers 文件,从中删除掉这个节点(修改后将该文件同步至其他集群中)。再修改 exclude 文件,将其从中删除即可。
4、分布式文件拷贝
distcp 其实是两个单词的缩写拼接而成的:Distributed Copy,即分布式拷贝。
可以实现将一个分布式集群的数据拷贝到另外的一个分布式集群!distcp命令的拷贝过程本质依然是MapReduce的任务,使用 MapReduce 实现文件分发、错误处理和恢复、报告生成。以文件或目录的列表作为 MapTask 的输入,每个MapTask 都会拷贝原文件列表中指定路径下的文件。
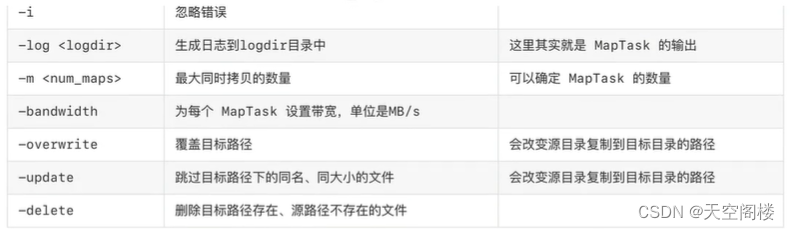
使用 distcp 命令做分布式拷贝有如下优点:
1、可以使用 bandwidth 参数为每一个 MapTasK 限流,控制 MapTask 并发数量以控制整个拷贝任务的带宽。防止出现拷贝任务将带宽占满,影响其他的业务。
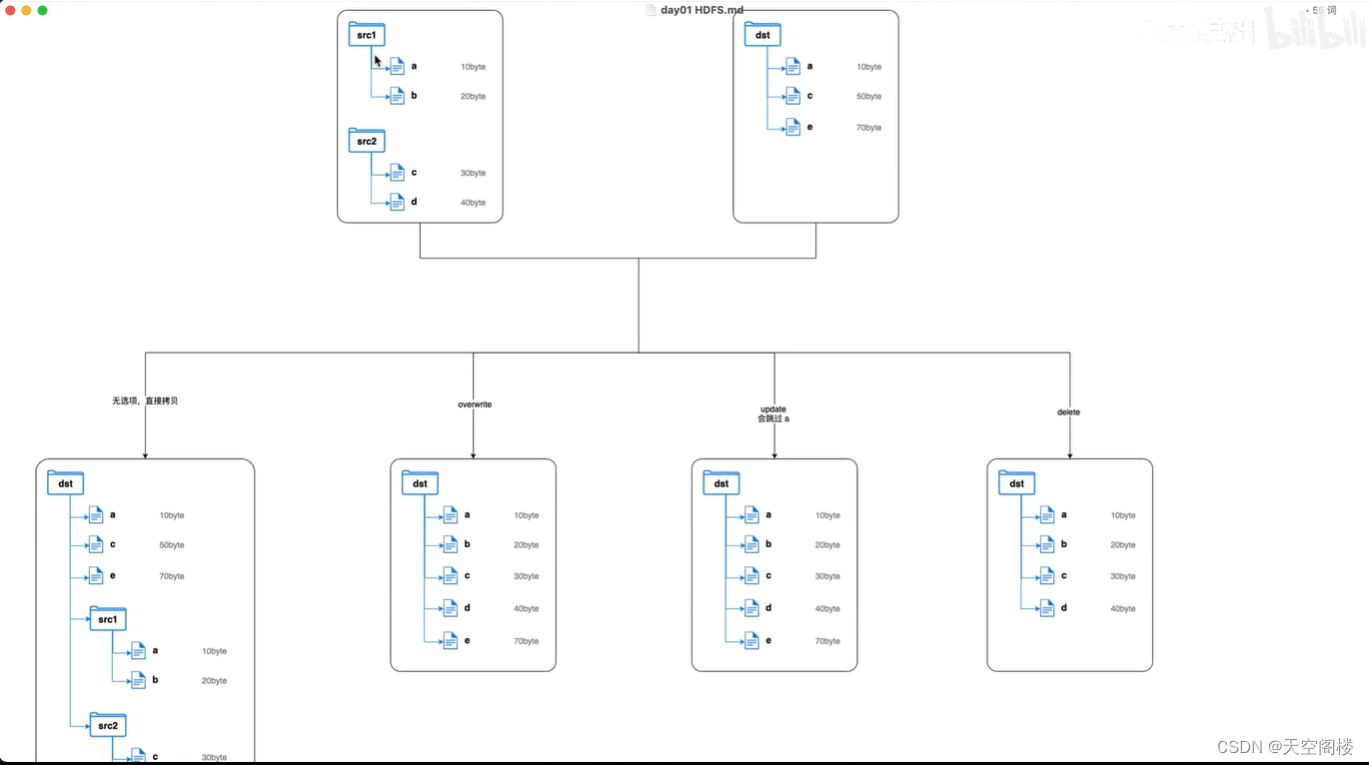
2、支持多种拷贝模式:
2.1、overwrite:覆盖写,无条件覆盖目标文件
2.2、update:增量写,如果目标文件的名称和大小与源文件不同,则覆盖;如果目标文件的名称和大小与源文件相同,则跳过
2.3、delete:删除写,删除目标路径存在而原路径中不存在的文件。
注意
当使用overwrite、update、delete进行distcp时,此操作不会将原路径中的文件夹进行拷贝,只拷贝其中的文件
4.1、distcp的使用
4.1.1、distcp 最基础的使用,就是直接在两个集群之间进行文件的拷贝
hadoop distcp hdfs://namenode01:9820/src hdfs://namenode02:9820/dst
4.1.2、多数据源目录
在拷贝的时候,也可以指定多个源路径
hadoop distcp hdfs://namenode01:9820/src1 hdfs://namenode01:9820/src2 hdfs://namenode02:9820/dst
如果需要拷贝的源路径比较多,不方便直接写到命令中的,也可以将其做成文件
1.在 HDFS 上创建一个文件,用来存储源路径
例如在 hdfs://namenode01:9820/distcp/src 文件中书写
hdfs://namenode01:9820/src1
hdfs://namenode01:9820/src2
hdfs://namenode01:9820/src3
2.执行拷贝操作
hadoop distcp-f hdfs://namenode01:9820/distcp/src hdfs://namenode02:9820/dst
4.2、常用属性















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









