







 一致性Hash算法用于解决服务器集群中数据缓存的问题,提供良好的容错性和扩展性。当添加或移除服务器时,只需要重新定位少数数据,避免大规模迁移。通过引入虚拟节点机制,可以解决因服务器数量少导致的数据分布不均问题,实现负载均衡。
一致性Hash算法用于解决服务器集群中数据缓存的问题,提供良好的容错性和扩展性。当添加或移除服务器时,只需要重新定位少数数据,避免大规模迁移。通过引入虚拟节点机制,可以解决因服务器数量少导致的数据分布不均问题,实现负载均衡。
基本场景
工程师常使用服务器集群来设计和实现数据缓存,以下是常见的策略:
1、无论是添加、查询、还是删除数据,都先将数据id通过海西函数转换成一个哈希值,记为key。
2、如果目前机器有N台,则计算key%N的值,这个值就是该数据所属的机器编号,无论是添加、删除还是查询操作,都只在这台机器上进行。
存在问题
上面场景中的缓存策略的潜在问题是如果增加或删除机器时(N变化)代价会很高,所有的数据不得不根据id重新计算一遍哈希值,并将哈希值对新的机器数进行取模操作,然后进行大规模的数据迁移。
一致性Hash算法
为了解决上面的问题,可以采用一致性哈希算法,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
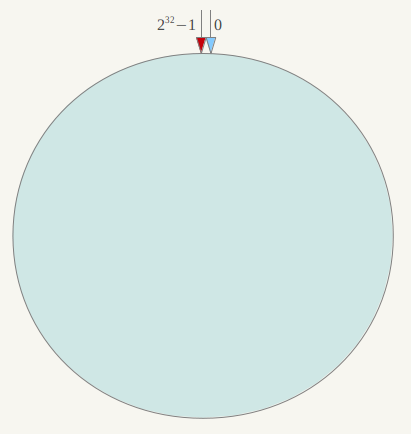
整个空间按顺时针方向组织。0和232-1<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7129
7129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









