







执行下面语句新建数据库Test及表Salary:
CREATE DATABASE Test
go
use test
Create Table Salary
(
HrName varchar(50),
Monthly varchar(50),
Money money
)
insert into Salary(HrName,Monthly,[Money])
select '张三','一月','3000'
union all
select '张三','二月','3200'
union all
select '张三','三月','3500'
union all
select '李四','一月','3800'
union all
select '李四','二月','4200'
union all
select '李四','三月','3900'
union all
select '张三','一月','2000'然后我们把这放到一边先了解一下什么是将列的值,旋转为列
表1:
列 列a 列b 列c
值 列1 1 12
值 列2 2 22
值 列3 3 32
我们把列a的值旋转为列
列 列1 列2 列3
这样我们得到数据类型一样的三列,那么值应该怎么填呢?我们把表1中列1那一行的其它值看为它的值,那么列1的值可以也只能从列b或列c取,我们这里从列b取,当然,如果列b的数据类型和列a不一样的话那么就要转换.其它列同样取值,那么旋转后的表为:
表2:
列 列1 列2 列3
值 1 2 3
不理解没关系,我们下面还有示例:
我们前面新建的表为:

然后通过执行语句:
select * from dbo.Salary
pivot (sum([Money]) for Monthly in (一月,二月,三月)) as b
解释:
执行顺序是:先对整个表Salary进行旋转,再根据要输出的列输出到结果
select * from dbo.Salary //由于旋转后,没有列Monthly,Money,所以如果输出它们会出错
sum([Money]) //这里必须用聚合函数来转换,而不能用格式转换的(因为有多个值可取),money就是新表中被旧表取值的列,
这里注意一下,列的行数是先确定的(去掉其它列的重复行,例如上表,就是去掉hrhome列的重复行后得到两行),然后根据被取值在旧表中那一行的其它列的值来确定被取值的在新表中的位置,位置相同的就聚合一下,例如:一月的值,有3000,3800,2000,第一个hrname=李三所以在新表第二行,第二个hrname=李四所以在新表第一行,第三个hrname=李三所以在新表第二行,因为第一二个在同一位置所以聚合一下就是5000了.
未填值前的新表:
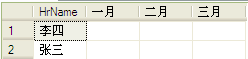
Monthly in (一月,二月,三月) //monthly就是要旋转的列,用for表示money的值给Monthly in (一月,二月,三月),这里in指示给其中这三个,也说明这三个值转换为列
as b //b,随便填
结果为:

UNPIVOT:将列,旋转为列的值,然后重新填充数据
执行下面语句新建表Salary2:
use test
Create Table Salary2
(
HrName varchar(50),
一月 money,
二月 money,
三月 money
)
insert into Salary2(HrName,一月,二月,三月)
select '李四','3800','4200','3900'
union all
select '张三','5000','3200','3500'
这张表就是前面旋转得到的:
执行语句:
use test
select * from Salary2
unpivot([money] for monthly in (一月,二月,三月)) as unpvt
解释:
注意:要转换为值的列必须是同样数据类型的,一月,二月,三月都是money数据类型
指明了,被填值的新列(对pivot来说是被取值列)Money,列旋转为值后的列名(对pivot来说是要旋转的列)monthly,及要转换为值的列(对pivot来说是要转换为列的值)一月,二月,三月
其实,是pivot的逆过程,要注意:新列的行数是与要旋转列的所有值(除null)个数相同,例如该表,就是6行.
结果为:
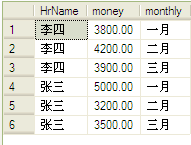
补充:pivot是两列被旋转,unpivot是旋转为两列
UNPIVOT 并不完全是 PIVOT 的逆操作。PIVOT 会执行一次聚合,从而将多个可能的行合并为输出中的单个行。而 UNPIVOT 不会重现原始表值表达式的结果,因为行已经被合并了。另外,UNPIVOT 的输入中的空值不会显示在输出中,而在执行 PIVOT 操作之前,输入中可能有原始的空值。















 2666
2666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









