







【0】README
0.1) 本文描述转自 core java volume 2, 旨在理解 java流与文件——文本输入输出 的相关知识;
0.2) 在保存数据时,可以选择是二进制还是文本格式; 在存储文本字符串时, 需要考虑字符编码方式。
0.3) OutputStreamWriter 和 InputStreamReader
- 0.3.1)OutputStreamWriter 类:将使用选定的字符编码方式, 把Unicode 字符流转换为 字节流;
- 0.3.2)InputStreamReader 类:将包含字节的输入流转换为 可以产生Unicode码元的读入器;
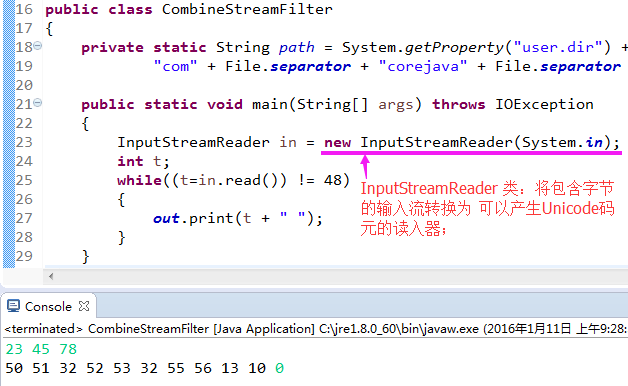
0.4)看个荔枝: 让一个输入读入器从控制台或文件中读入信息
- 0.4.1) InputStreamReader in = new InputStreamReader(System.in);
- 0.4.2) InputStreamReader in = new InputStreamReader(new FileInputStream(“a.dat”), “ISO8859_5”);
【1】如何写出文本输出
1.1)文本输出,使用 PrintWriter(打印写出器): 这个类拥有以文本格式打印字符串和数字的方法, 它甚至还有一个将PrintWriter 链接到 FileWriter 的便捷方法, 如下:
PrintWriter out = new PrintWriter("a.txt");
等价于:
PrintWriter out = new PrintWriter(new FileWriter("a.txt"));- 1.1.1)为了输出到打印写出器,需要使用 print, println, printf 方法;
- 1.1.2)看个荔枝:
String name = "nihao";
double salary = 123;
out.print(name);
out.print(" ");
out.print(salary);
它将把下面的字符 nihao , 123 输出到写出器;之后这些字符会被转换成字节并最终写入 a.txt 中;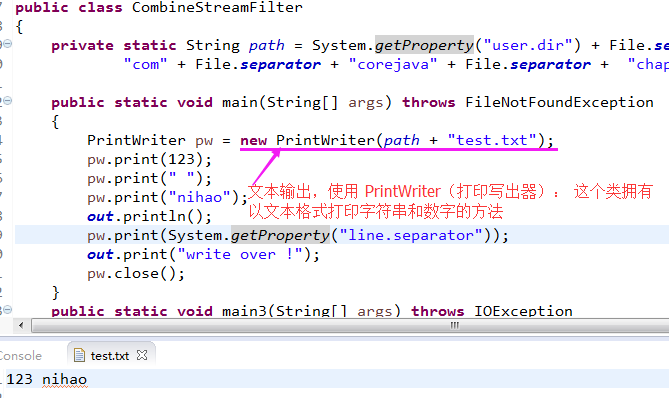
- 1.1.3)行结束符: println 方法添加行结束符(windows 是 “\r\n”, unix是 “\n”),通过调用System.getProperty(“line.separator”) 来获得字符串;
1.2)自动冲刷模式(干货——是否开启自动冲刷模式)
- 1.2.1)如果写出器设置为 自动冲刷模式, 只要println 被调用, 则缓冲区的所有字符都会被发送到他们的目的地;
- 1.2.2)该模式默认是禁用的, 通过 PrintWriter(Writer out, Boolean autoFlush) 来开启或禁用自动冲刷机制;
Attention)
- A1) PrintStream 可构建读入器和写出器, 而 System.out 不是读入器和 写出器;
- A2)为了与已有代码兼容,System.in, System.out, System.err仍旧是流而不是读入器或写出器;
【2】如何读入文本输入
2.1)以二进制格式写出数据, 用 DataOutputStream;
2.2) 以文本格式写出数据, 用 PrintWriter;
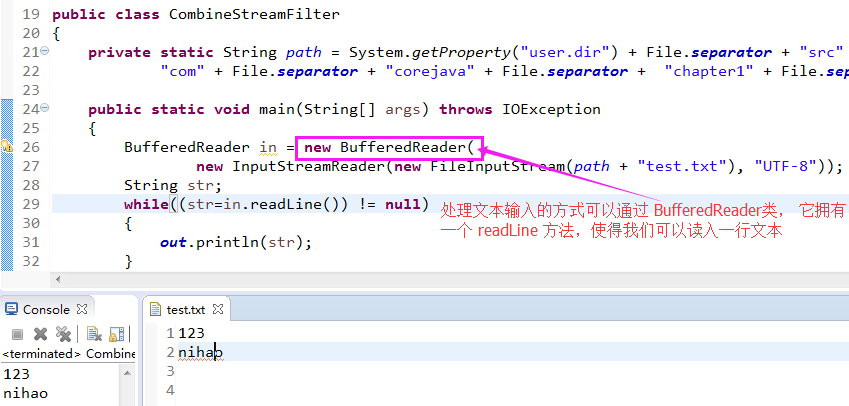
2.3)处理文本输入的方式可以通过 BufferedReader类, 它拥有一个 readLine 方法,使得我们可以读入一行文本;
- 2.3.1)将 带缓冲区的读入器和输入源组合起来:
BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(“a.txt”), “UTF-8”));
2.4)然而 , BufferedReader 没有任何用于读入数字的方法, 建议使用 Scanner 来读入文本输入;
【3】以文本格式存储对象
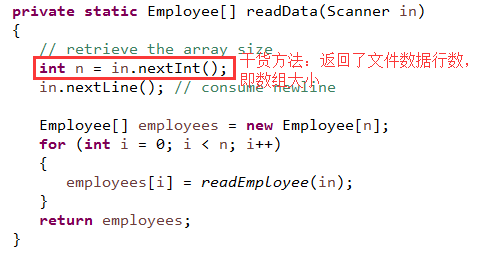
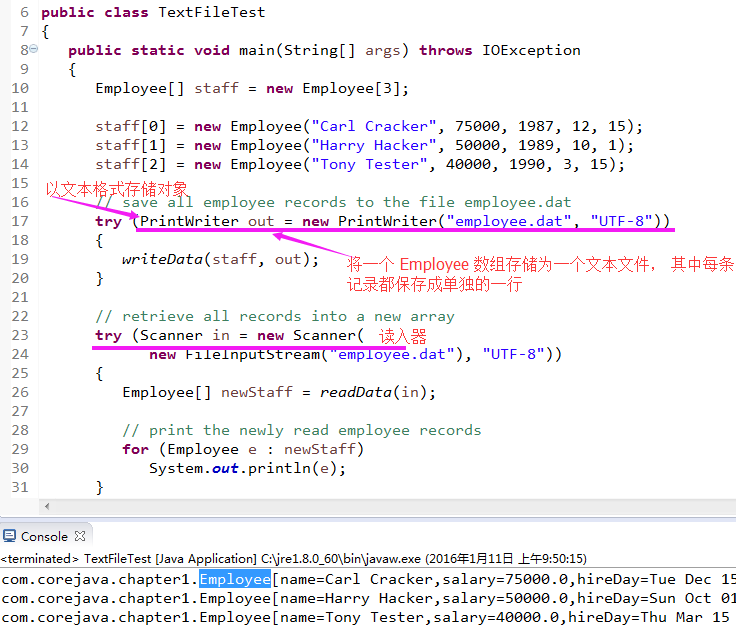
3.1)看个荔枝: 将一个 Employee 数组存储为一个文本文件, 其中每条记录都保存成单独的一行, 字段间用分隔符隔开(如,竖线 | , 或冒号 : 作为分隔符);
(https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter1/TextFileTest.java)
【4】字符集
4.1)在 java SE 1.4中引入的 java.nio 包用到了 Charset 类统一了对字符集的转换(注意,s是小写的);
4.2)字符集建立了两字节 Unicode码元序列与使用本地字符编码方式的字节序列间的映射;
- 4.2.1)ISO-8859-1: 是最流行的字符编码方式之一, 这是一种对 Unicode前 256个字符进行单字节编码的方式;
- 4.2.2)aliases方法: 它可以返回由别名构成的 Set对象:
Set<String> aliases = cset.aliases();
for(String alias : aliases)
out.println(alias);- 4.2.3)字符集的大小写是不敏感的;
- 4.2.4)调用静态的 forName 方法:获得一个 Charset, 只需要传递一个官方名字或别名;
Charset charset = Charset.forName("ISO-8859-1");- 4.2.5)静态方法 availableCharsets: 确定在某个特定实现中哪些字符集是可用的:
Map<String, Charset> charsets = Charset.availableCharsets();
for(String name : charsets.keSet())
out.println(name);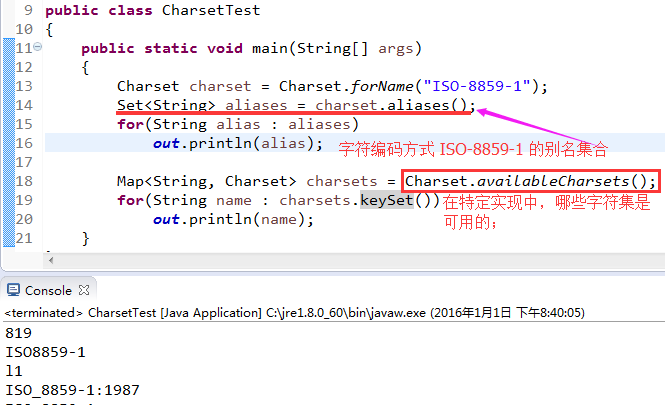
4.3)本地编码方式模式不能表示所有的Unicode字符,如果某个字符不能表示, 它将被转换为 ?;(干货——为什么出现 ? 的原因)
- 4.3.1)编码字符串:一旦有了字符集,就可以使用它在包含Unicode码元的 java 字符串 和 编码而成的字节序列间进行转换, 下面是如何编码java 字符串的代码的:
String str = ...;
ByteBuffer buffer = cset.encode(str);
byte[] bytes = buffer.array();- 4.3.2)解码字符串: 需要字节缓冲区。使用 ByteBuffer数组的静态方法wrap 可以将一个字节数组转换为一个字节缓冲区。 decode 方法的结果是 CharBuffer, 调用它的 toString() 方法将获得一个字符串;
Byte[] bytes = ...;
ByteBuffer buffer = ByteBuffer.wrap(bytes, offset, length);
CharBuffer cbuf = cset.decode(buffer);
String str = buffer.toString();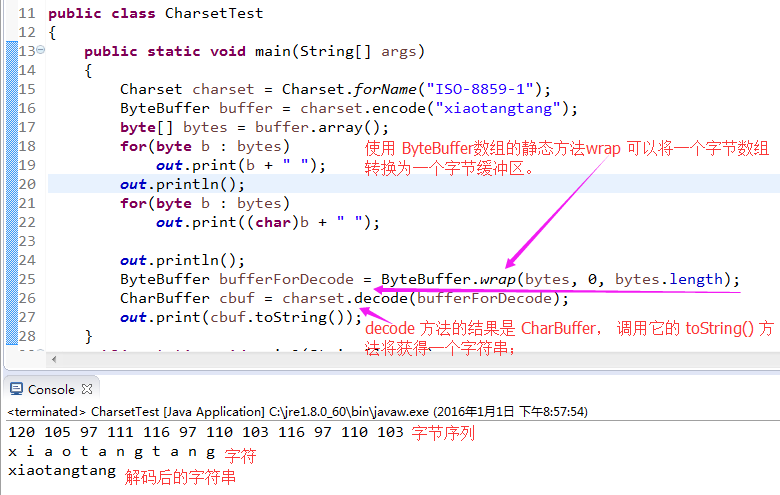














 3690
3690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









