







【0】README
0.1)本文文字描述转自 core java volume 2 , 旨在理解 XML——文档类型定义(DTD-Document Type Definition) 的基础知识;
0.2) for source code, please visit https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter2/ParseXMLTest.java
0.3) 为什么使用 DTD: 参见 http://blog.csdn.net/pacosonswjtu/article/details/50588471
【1】DTD相关
1)提供DTD的方式有多种,可以将其纳入到 XML文档中:
<?xml version="1.0">
<!DOCTYPE configuration [
<!ELEMENT configuration ...>
more rules
...
]>2)正如你所看到的,这些规则被纳入到了 DOCTYPE声明中, 该代码块使用 […] 来限定其界限;文档类型必须匹配根元素的名字,比如 荔枝中的configuration;
3)在XML 文档内部使用 DTD 不是很普遍,因为DTD会使文件长度变得很长,把DTD存储在外面更具有意义; (干货——在XML 文档内部使用 DTD 不是很普遍,因为DTD会使文件长度变得很长,把DTD存储在外面,这也是引入SYSTEM声明的原因)
- 3.1)SYSTEM声明可以用来实现这个目标,你可以指定一个包含DTD的URL,如:
<!DOCTYPE configuration SYSTEM "config.dtd">
或者:
<!DOCTYPE configuration SYSTEM "http://myserver.com/config.dtd">- Warning)
- w1)如果你使用 的是 DTD 的相对URL(比如 config.dtd),那么要给解析器一个 File 或 URL 对象,而不是 InputStream;(干货——如果使用相对URL定位DTD)
- w2)如果必须从一个输入流来解析,请提供一个实体解析器;
4)最后,有一个来源于 SGML 的用于识别DTD的机制:
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2 //EN"
"http://java.sun.com/j2ee/dtds/web-app_2.2.dtd">Attention)
- A1)如果你使用的是DOM 解析器, 并且想支持 PUBLIC标识符,请调用 DocumentBuilder 类的 setEntityResolver 方法来安装 EntityResolver 接口的某个实现类的一个对象。该接口只有一个方法:resolveEntity;
- A2) 下面是一个典型实现的代码框架:
class MyEntityResolver implements EntityResolver
{
public InputSource resolveEntity(String publicId, String systemId)
{
if(publicId.equals(a known Id))
return new InputSource(DTD data);
else
retunr null;
}
}
你可以从 InputStream, Reader 或字符串构建输入源;5) 现在你知道了 解析器怎样定位 DTD了,下面,看看不同类型的规则:
5.1)ELEMENT 规则:用于指定某个 元素可以拥有什么样的子元素;可以指定一个正则表达式,如下表所示: (干货——ELEMENT 规则和正则表达式结合起来)
5.2) 下面是一些简单而典型的荔枝。 下面的规则声明了 menu 元素包含0个或多个item 元素:

<!ELEMENT font (name, size)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT size (#PCDATA)>Attention)
- A1) PCDATA = parsed char data, 表示已解析的字符数据; (干货——PCDATA定义 not CDATA 定义)
A2)数据是已解析的,因为 解析器通过寻找表示一个新标签起始的 < 字符或 表示一个实体起始的 & 字符, 而解释了这些文本字符串;
5.4) 元素的规格说明可以包含 嵌套的和复制的正则表达式, 如, 下面是一个描述了本书中每一章的结构的规则: (干货——元素的规格说明可以包含 嵌套的和复制的正则表达式)
<!ELEMENT chapter (intro,(heading,(para|image|table|noe)+)+)>
每章都以简洁开头, 其后是一个或多个小节, 每个小节有一个标题和一个或多个段落,图片,表格或说明构成;- 5.5)有一种常见的case 是: 不能把规则定义得像你希望的那样灵活。当一个元素可以包含文本时,那么就只有两种合法的cases:
- case1)要么元素只包含文本, 比如
<!ELEMENT name (#PCDATA)>; - case2)要么元素只包含任意顺序的文本和标签的组合, 比如
<!ELEMENT para (#PCDATA|em|strong|code)*>;
- case1)要么元素只包含文本, 比如
- 5.6)指定其他包含 #PCDATA 规则的类型都是不合法的。如,以下规则是非法的:
<!ELEMENT captionedImage (image, #PCDATA)> , 必须重写一个规则,以引入另一个 caption 元素或 允许 使用 image 元素或文本的组合;- 5.6.1)这种限制简化了XML 解析器在解析混合式内容(标签和文本的混合)时的工作。因为在允许混合式内容时难免失控, 所以最好在设计 dtd时, 让其中所有的元素要么包含 其中元素,要么只包含文本;
5.7) 还可以指定描述合法的元素属性的规则, 通用语法为: (干货——还可以指定描述合法的元素属性的规则)
<!ATTLIST element attribute type default>5.7.1)下面是两个典型的属性规格说明:
<!ATTLIST font style (plain|bold|italic|bold-italic) "plain">
<!ATTLIST size unit CDATA #IMPLIED>对上述规格的分析(Analysis):
- A1)第一个规格说明: 描述了font元素的style 属性, 它有4个合法的属性值, 默认值是 plain;
- A2)第二个规则说明: 表示 size 元素的unit 属性 可以包含任意字符数据序列;
5.8) 表2-2 显示了合法的属性类型, 表2-3 显示了属性默认值 的语法: (干货——CDATA定义)
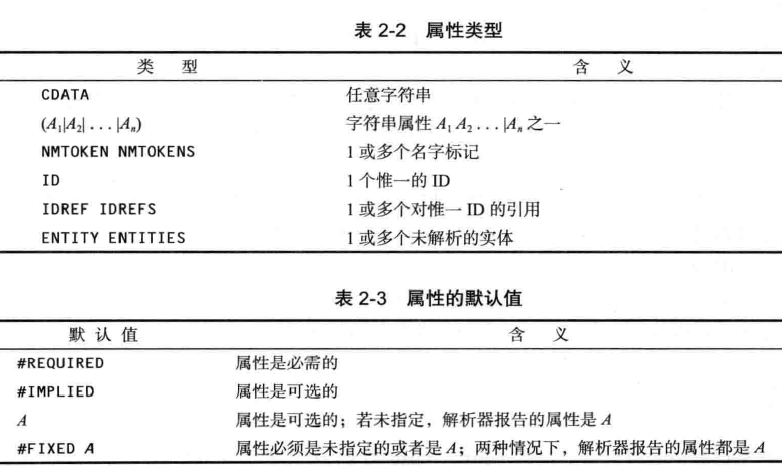
Attention)
- A1)一般情况下,我们推荐用元素而非属性来描述数据;
- A2)属性有一个不可否认的优点: 那就是解析器能够校验取值是否合法,
6)CDATA属性值的处理与你前面看到的处理 #PCDATA有着微妙的差别: 并且与 < ![CDATA[...]]> 部分没有多大关系。 属性值首先被规范化, 也就是说, 解析器要处理对字符和实体的引用, 并且要用空格来替换空白字符;
- 6.1)NMTOKEN(即名字标记)与 CDATA相似: 但是大多数非字母数字字符和内部的空白字符是不允许使用的, 而且解析器会删除起始和结尾的空白字符。NMTOKENS 是一个以空白字符分隔的名字标记列表;
- 6.2) 属性类型介绍:
- 6.2.1)ID: ID 结构是有用的, ID 是在文档中唯一的名字标记,解析器会检查其唯一性;
- 6.2.2)IDREF: IDREF 是对同一个文档中 已存在的ID的应用;解析器也会对它进行检查;
- 6.2.3)IDREFS: IDREFS 是以空白字符分割的 ID 引用的列表;
- 6.3)ENTITY 属性值: 将引用一个 “未解析的外部实体”, 这是从 SGML将那里沿用下来的, 在实际应用中很少见;
- 6.4)DTD 也可以定义实体,或定义解析过程中被替换的缩写。 (干货——DTD 也可以定义实体, 而其他地方的文本可以包含对这个实体的引用)
- 6.4.1)看个荔枝:
<!ENTITY back.label "Back">
其他地方的文本可以包含对这个实体的引用,如: <menuitem label = "&back.label; "/>7)Conclusion: 这样,我们就结束了对 DTD 的介绍了。你已经知道如何 使用 DTD了;你可以配置你的解析器以充分利用他们; (干货——如何配置XML解析器)
- C1)首先,通知文档生成工程打开验证特性:
factory.setValidating(true); - C2)这样, 该工厂生成的所有文档生成器都将根据DTD 来验证他们的输入。验证的最大好处是可以忽略元素内容的空白字符, 如,考虑如下代码:
<font>
<name>a</name>
<size>a</size>
</font>- C3)一个不进行验证的解析器会报告 font, name 和 size 元素之间的空白字符, 因为它无法知道 font 的子元素是:
(name, size) (#PCDATA, name, size) * 还是 ANY; - C4)一旦 DTD 指定了子元素是 (name, size), 解析器就知道他们之间的空白字符不是文本。调用下面的代码:
factory.setIgnoringElementContentWhitespace(true);(干货——将dtd绑定到xml后,必须进行设置setIgnoringElementContentWhitespace)
这样, 生成器就不会报告文本节点中的空白字符, 这意味着, 你可以依赖 font 节点只有2个子元素的事实。 - C5)你只需要 通过如下代码访问第一个和第二个元素:
Element e1 = (Element) children.item(0);
Element e1 = (Element) children.item(1);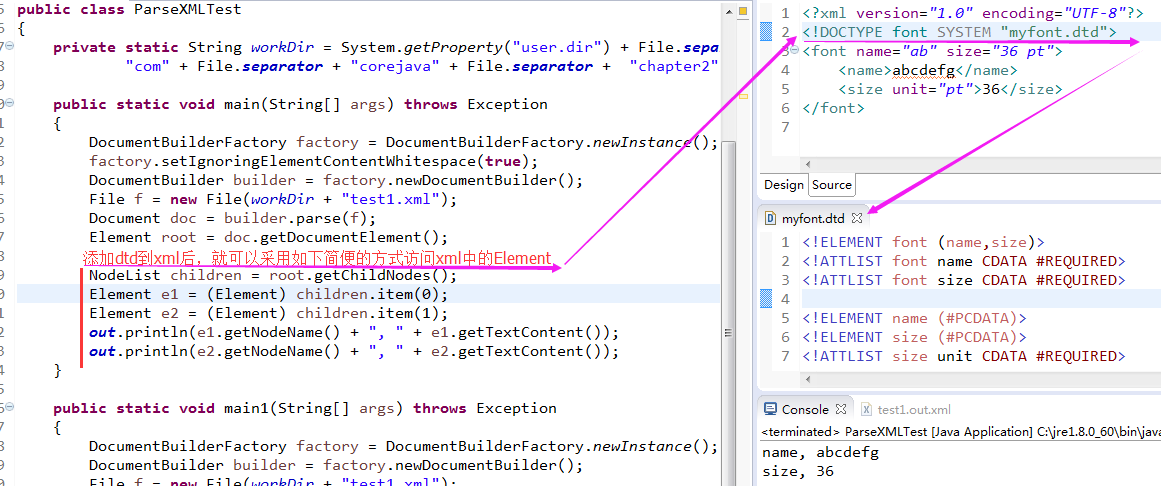
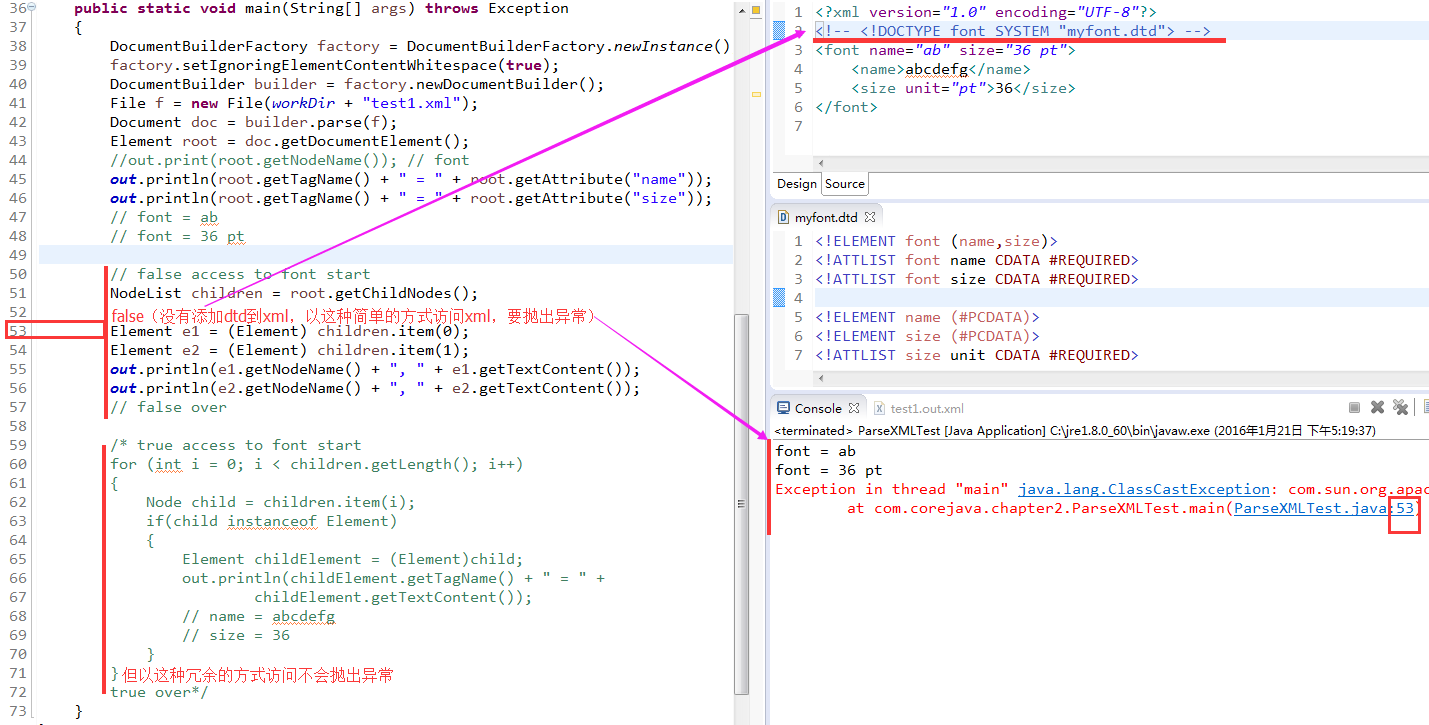
- C6)这就是 DTD 如此有用的原因。 (干货——这就是 DTD 如此有用的原因)
- C7) 当解析器报告错误的时候, 应用程序希望对该错误执行某些操作; (干货——当解析器报告错误的时候, 应用程序希望对该错误执行某些操作)
- C7.1)在验证时, 应该安装一个 错误处理器,这需要提供一个实现了 ErrorHandler 接口的对象,这个接口有3个方法:
void warning(SAXParseException exception)
void error(SAXParseException exception)
void fatalError(SAXParseException exception)
可以通过 DocumentBuilder 类的 setErrorHandler 方法来安装 错误处理器:
builder.setErrorHandler(handler);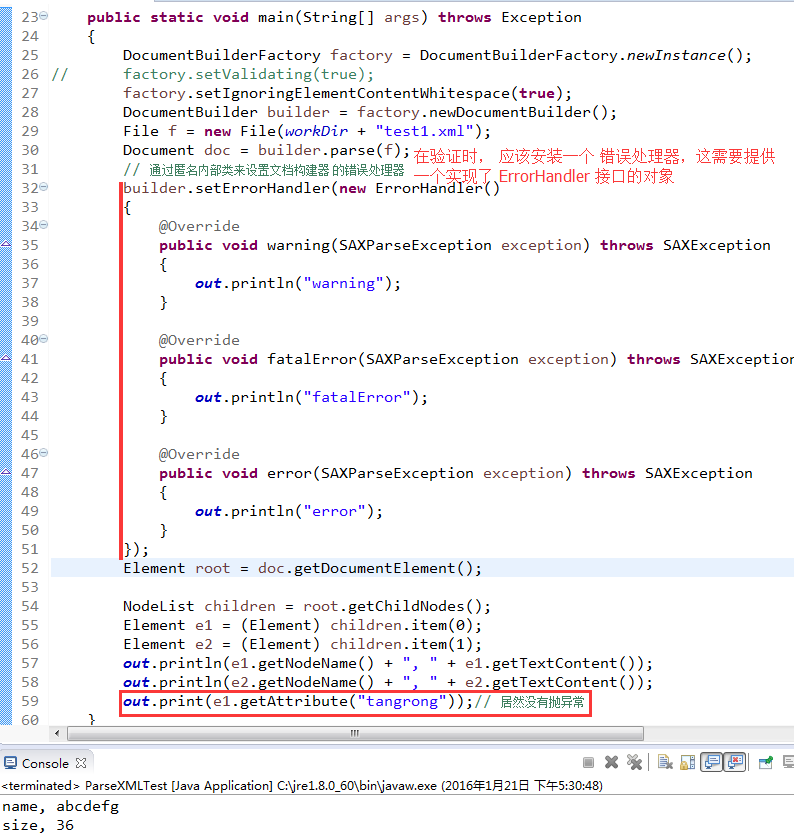














 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









