







本人在学习数据结构KMP算法这节内容时,也是花费了好长时间才弄懂,期间一直是懵的很呐!不知道大家有没有这么个感觉,好像有点明白KMP算法的思想,但是再面对那几行简短的代码是还是有点不知其所以然的感觉。所以呢,我就想给大家讲解一下KMP算法的思想及代码的实现过程,让大家少走弯路,早日豁然开朗。
简单模式匹配(BF算法)想必大家都应该很清楚吧,但是这种算法效率比较低,给大家举个例子。先定义两个字符串S、T,然后我们来看看简单模式匹配的匹配过程。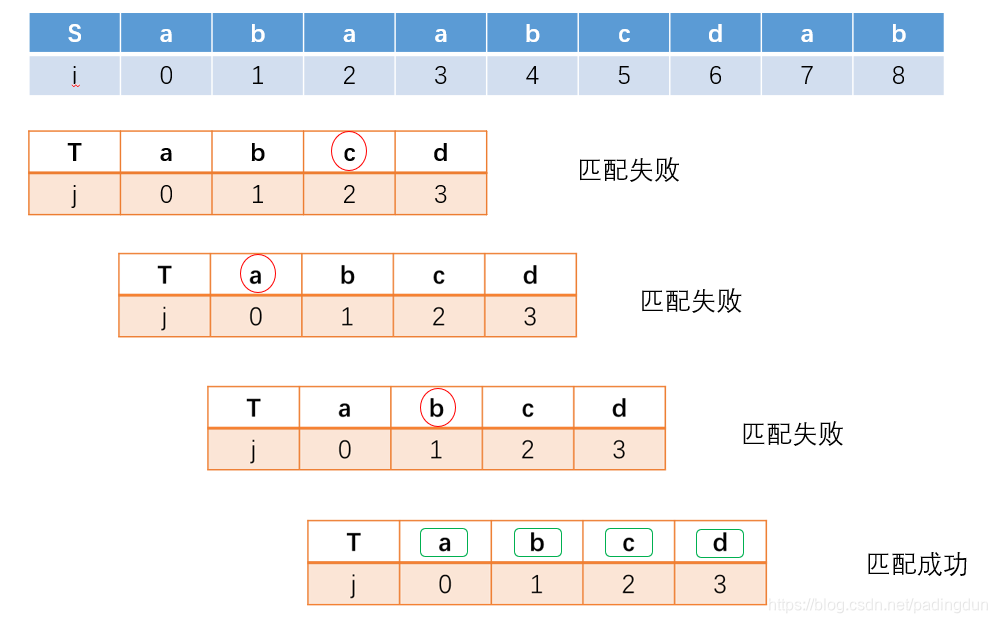 只要匹配失败,则S串的下一位元素与T串的元素重新一位一位的匹配。
只要匹配失败,则S串的下一位元素与T串的元素重新一位一位的匹配。
那我们能不能根据模式串中的元素得到一些信息从而来减少一些不必要的匹配操作呢?答案是肯定的,我们可以引入KMP算法来解决这个问题,KMP算法的关键就是如何获取NEXT数组,上面的例子不够典型,下面我就举几个例子来说明如何求得NEXT数组。先定义两个字符串S、T(这个例子是看的一个博主写的,觉得比较典型,就搬过来了,嘻嘻),如果按照简单模式匹配,那么其匹配过程如下: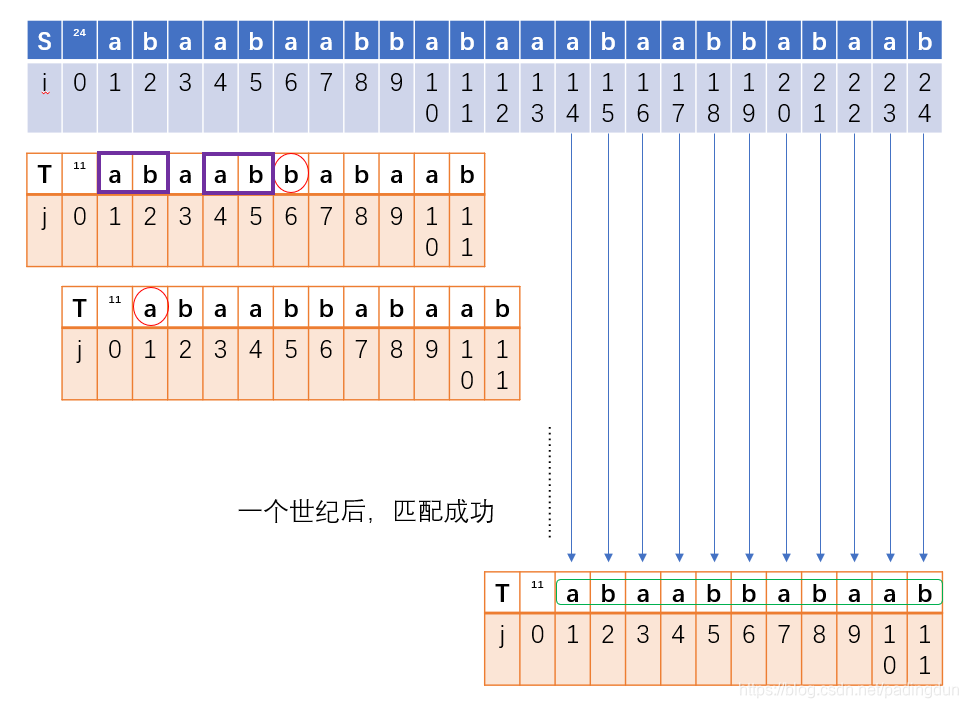
从匹配过程中我们可以看出第一次匹配失配的位置是在第六位元素(字符串第零位元素为字符串的长度),在第一次匹配的过程中,我们发现模式串前五个元素与目标串前五个元素一一匹配,同时前五个元素存在重复部分,即前缀和后缀都为ab(从第一位元素算起为前缀,是绝对的,后缀要从该元素前一位算起,是相对的),为了减少一些不必要的匹配,我们希望下一次匹配可以从S串的第四位开始重新匹配:
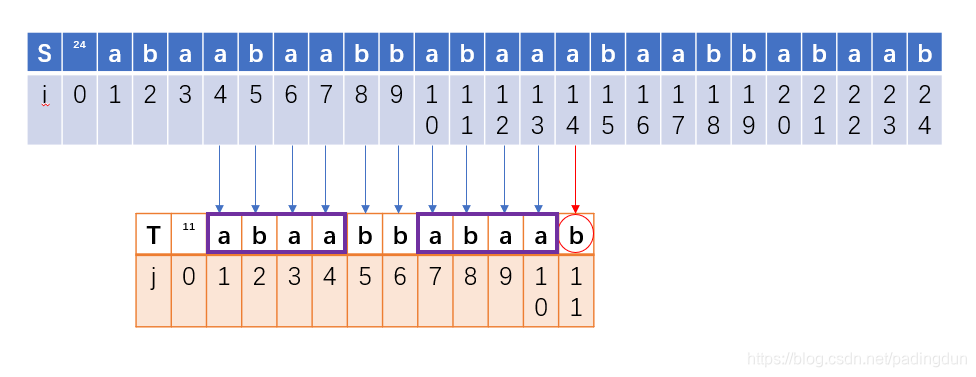
在第二次匹配过程中,我们发现失配位置在第十一位元素,那么我们就希望下一次匹配在这个位置:
那么下下次匹配我们就希望在这个位置:
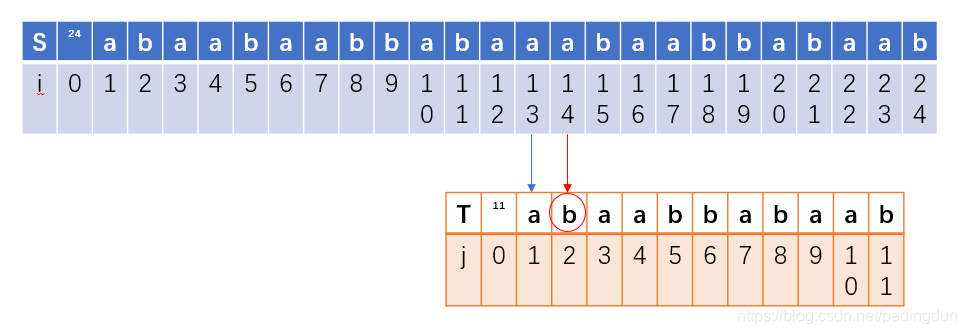
由于第二位元素失配前只有元素a,因此下次匹配只需要下移一位即可,即:
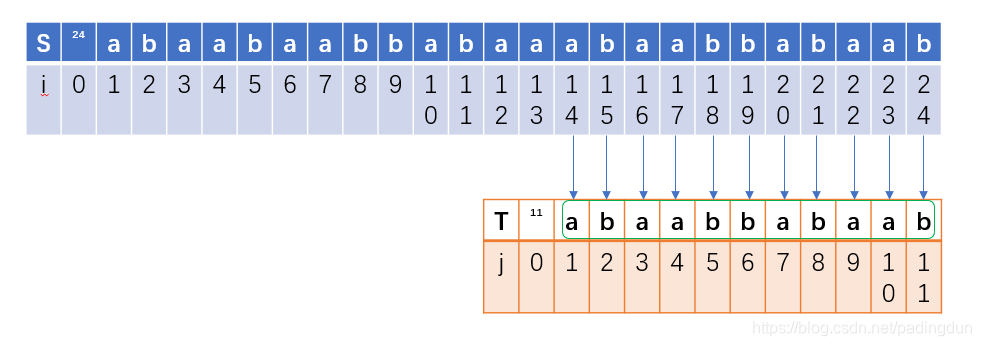
这就是KMP算法的思想,如何实现就要利用NEXT数组,从上面的例子我们可以看出,匹配的过程主要是通过模式串的元素的前后缀来实现的,因此,获取NEXT数组只需要关注模式串。上例中NEXT数组值为:
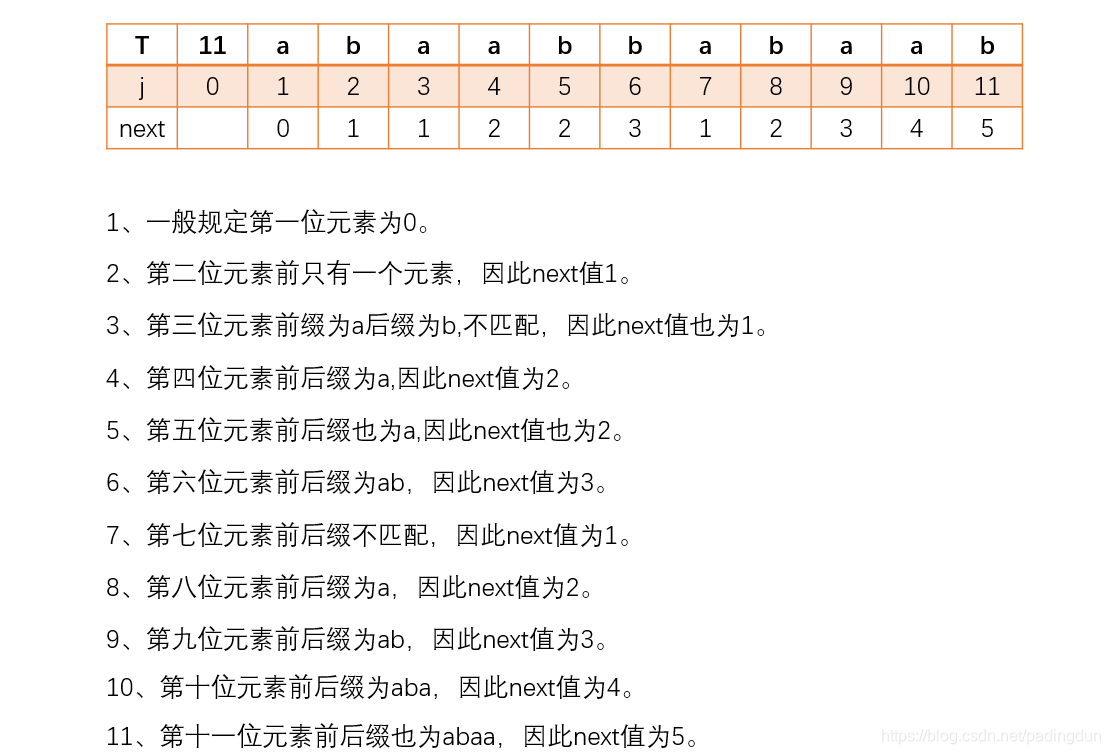
再举一个:
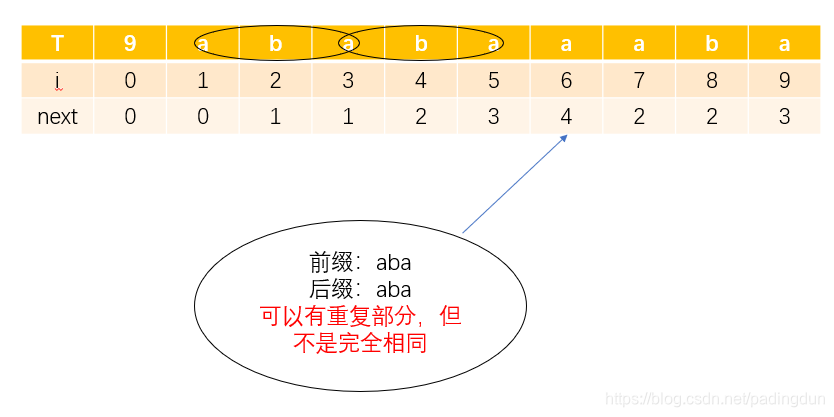
下面就来介绍一下代码的实现过程,首先讲解一下获取NEXT数组的函数:
void get_next(String T,int *next)
{
int x=0;
int y=1;
next[1]=0;
while(y<T[0])
{
if(x==0||T[x]==T[y])//前缀等于后缀
{
x++;
y++;
next[y]=x;
}
else //失配,前缀回溯
{
x=next[x];//前缀绝对,后缀相对
}
}
}
失配情况下的回溯问题比较难以理解,大家可以根据例子自己多推算几遍。然后就来讲解一下如何利用NEXT数组进行KMP算法的代码实现过程:
int KMP(String S,String T,int pos)
{
int i=pos; //从S串第pos位元素与T串第一位元素开始匹配
int j=1;
while(i<=S[0]&&j<=T[0]) //匹配在字符串长度范围内
{
if(j==0||S[i]==T[j]) //当前匹配成功,则继续一一比较
{
i++; //判断j==0原因:若在第一个元素就发生失配,此时next[1]=0
j++;
}
else //当前匹配失败,则有NEXT数组指引相应元素去匹配
{
j=next[j];
}
//如:S:abababcababc
// T:ababaaaba (next:011234223)
//若在第六位元素发生失配,此时i=j=6,j=next[6]=4
//则由T串第四位元素与S串第六位元素开始匹配,即:
//S:abababcababc
//T: ababaaaba
}
if(j>T[0]) //匹配完成
{
return i-T[0];
}
else //匹配失败
{
return 0;
}
}
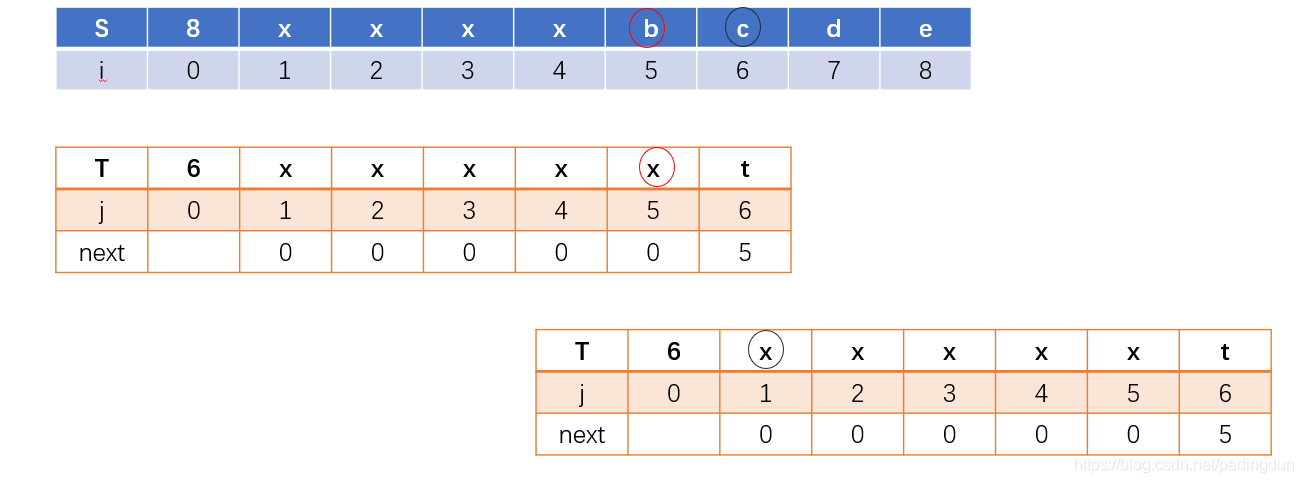
KMP算法还可以进一步优化,比如遇到下面这个例子时:
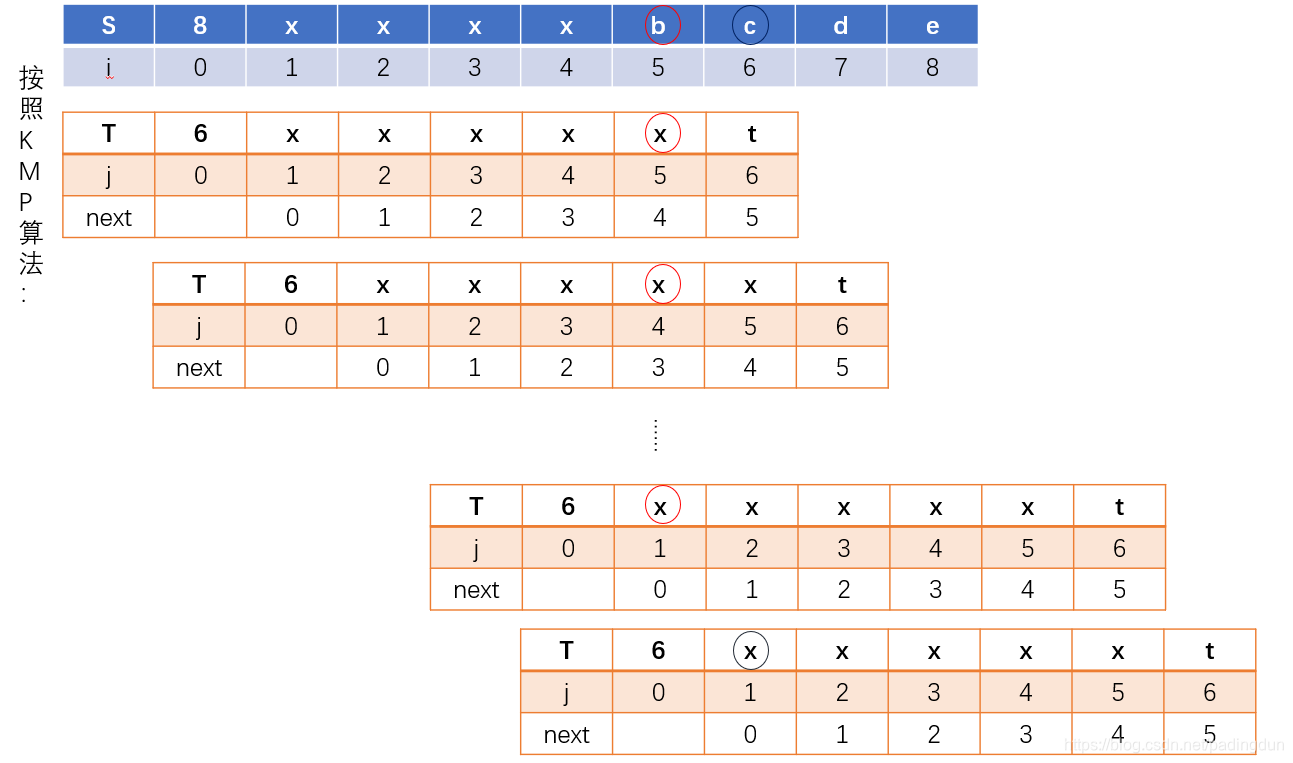
这种情况下,KMP算法的效率也比较低,T串第五位与S串第五位元素不匹配,S串前五位元素相等,因此自然也和第六位元素不匹配,为减少一些不必要的匹配,可在获取NEXT数组的函数中做出如下改进:
void get_next(String T,int *next)
{
int x=0;
int y=1;
next[1]=0;
while(y<T[0])
{
if(x==0||T[x]==T[y])//前缀等于后缀
{
x++;
y++;
if(T[x]!=T[y])//优化
{
next[y]=x;
}
else
{
next[y]=next[x];
}
}
else //失配,前缀回溯
{
x=next[x];//前缀绝对,后缀相对
}
}
}
此时:
最后博主希望你们:
看之前:

看完后:
















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









