







三、Kafka架构原理
3.1 整体架构图
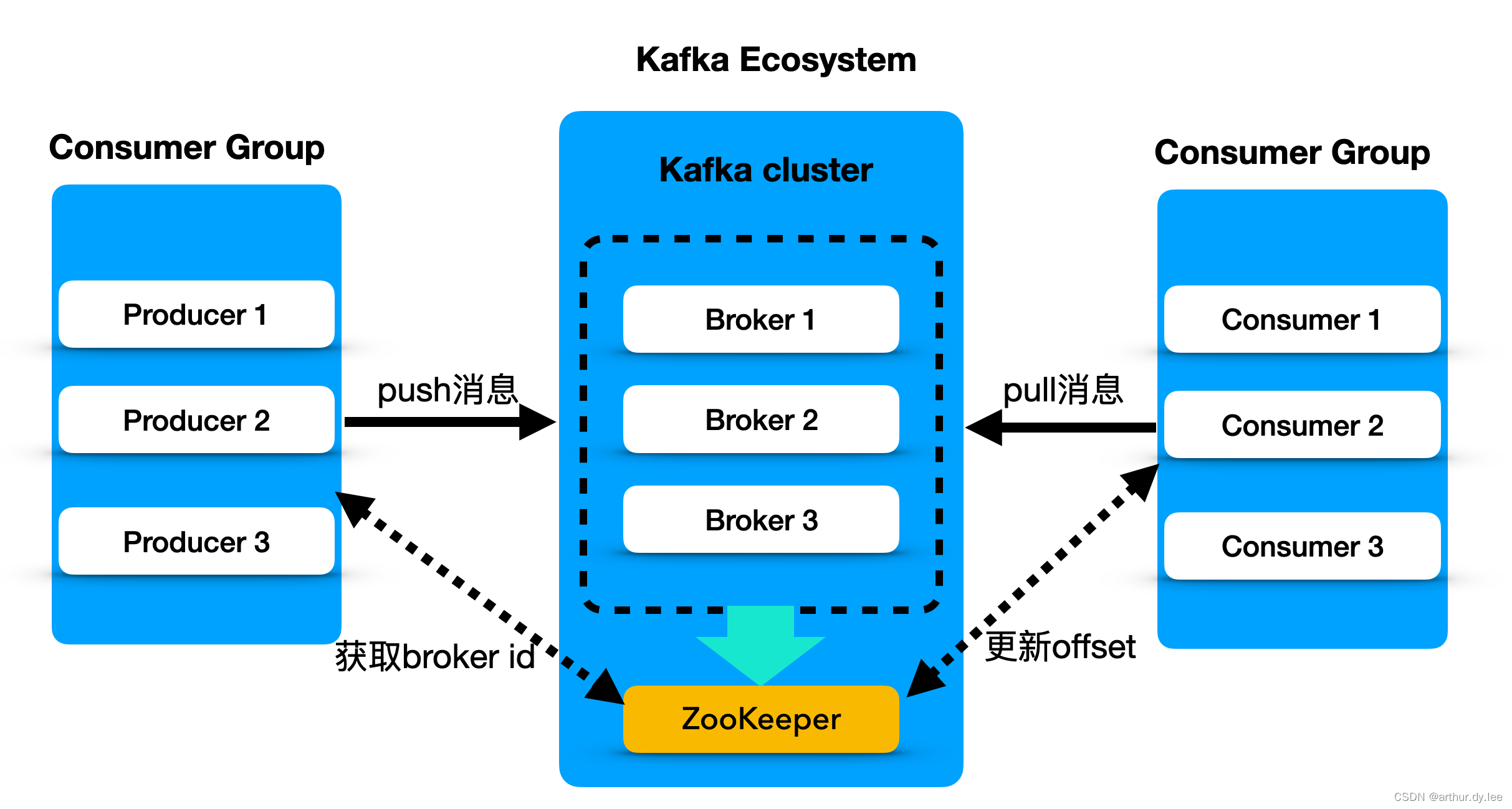
一个典型的kafka集群中包含若干个Producer,若干个Broker,若干个Consumer,以及一个zookeeper集群; kafka通过zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行Rebalance(负载均衡);Producer使用push模式将消息发布到Broker;Consumer使用pull模式从Broker中订阅并消费消息。
3.1.1 controller
Kafka的核心组件。它的主要作用是在Apache ZooKeeper的帮助下管理和协调整个Kafka集群。controller控制器是重度依赖ZooKeeper
Broker在启动时,会尝试去ZooKeeper中创建/controller节点。Kafka当前选举控制器的规则是:第一个成功创建/controller节点的Broker会被指定为控制器。
-
主题管理(创建、删除、增加分区)
-
分区重分配
-
Preferred领导者选举
Preferred领导者选举主要是Kafka为了避免部分Broker负载过重而提供的一种换Leader的方案
-
集群成员管理(新增Broker、Broker主动关闭、Broker宕机)
-
数据服务
向其他Broker提供数据服务。控制器上保存了最全的集群元数据信息,其他所有Broker会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
3.1.2 broker
kafka为每个主题维护了分布式的分区(partition)日志文件,每个partition在kafka存储层面是append log。任何发布到此partition的消息都会被追加到log文件的尾部,在分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,也就是我们的offset,offset是一个long型的数字,我们通过这个offset可以确定一条在该partition下的唯一消息。在partition下面是保证了有序性,但是在topic下面没有保证有序性。
3.1.3 zk
zk与Producer, Broker, Consumer的关系
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
- Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
- Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
- Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
Producer向zookeeper中注册watcher,了解topic的partition的消息,以动态了解运行情况,实现负载均衡。Zookeepr不管理producer,只是能够提供当前broker的相关信息。

每个Broker服务器在启动时,都会到Zookeeper上进行注册,即创建/brokers/ids/[0-N]的节点,然后写入IP,端口等信息,Broker创建的是临时节点,所有一旦Broker上线或者下线,对应Broker节点也就被删除了,因此我们可以通过zookeeper上Broker节点的变化来动态表征Broker服务器的可用性,Kafka的Topic也类似于这种方式。
Controller 的HA中zk起到的作用
在 broker 启动的时候,都会去尝试创建 /controller 这么一个临时节点,由于 zk 的本身机制,哪怕是并发的情况下,也只会有一个 broker 能够创建成功。因此创建成功的那个就会成为 controller,而其余的 broker 都会对这 controller 节点加上一个 Watcher,
一旦原有的 controller 出问题,临时节点被删除,那么其他 broker 都会感知到从而进行新一轮的竞争,谁先创建那么谁就是新的 controller。
当然,在这个重新选举的过程中,有一些需要 controller 参与的动作就无法进行,例如元数据更新等等。需要等到 controller 竞争成功并且就绪后才能继续进行,所以 controller 出问题对 kafka 集群的影响是不小的。
消费者注册
消费者服务器在初始化启动时加入消费者分组的步骤如下
注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id],完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
对 消费者分组 中的 消费者 的变化注册监听。每个 消费者 都需要关注所属 消费者分组 中其他消费者服务器的变化情况,即对/consumers/[group_id]/ids节点注册子节点变化的Watcher监听,一旦发现消费者新增或减少,就触发消费者的负载均衡。
对Broker服务器变化注册监听。消费者需要对/broker/ids/[0-N]中的节点进行监听,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者负载均衡。
进行消费者负载均衡。为了让同一个Topic下不同分区的消息尽量均衡地被多个 消费者 消费而进行 消费者 与 消息 分区分配的过程,通常,对于一个消费者分组,如果组内的消费者服务器发生变更或Broker服务器发生变更,会发出消费者负载均衡。
3.1.4 日志
日志可能是一种最简单的不能再简单的存储抽象,只能追加、按照时间完全有序(totally-ordered)的记录序列。日志看起来的样子:
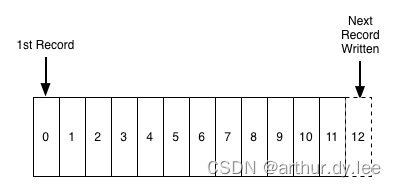
在日志的末尾添加记录,读取日志记录则从左到右。每一条记录都指定了一个唯一的顺序的日志记录编号。
日志记录的次序(ordering)定义了『时间』概念,因为位于左边的日志记录表示比右边的要早。日志记录编号可以看作是这条日志记录的『时间戳』。把次序直接看成是时间概念,刚开始你会觉得有点怪异,但是这样的做法有个便利的性质:解耦了时间和任一特定的物理时钟(physical clock )。引入分布式系统后,这会成为一个必不可少的性质。
日志和文件或数据表(table)并没有什么大的不同。文件是一系列字节,表是由一系列记录组成,而日志实际上只是一种按照时间顺序存储记录的数据表或文件。
3.1.4 Topic
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:
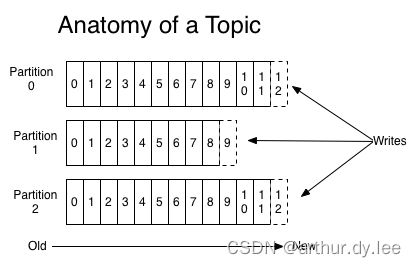
在Kafka中的每一条消息都有一个topic。一般来说在我们应用中产生不同类型的数据,都可以设置不同的主题。一个主题一般会有多个消息的订阅者,当生产者发布消息到某个主题时,订阅了这个主题的消费者都可以接收到生产者写入的新消息。
- 一个 Topic 是由多个队列组成的,被称为【Partition(分区)】。
- 生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。
- 消费者监听的是所有分区。
- 生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。
- 也可以配置 Topic,让同类型的消息都在同一个 Partition。例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)。这是为了提供消息的【有序性】。
- 消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的。
3.1.5 Partition
一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号
1.每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
2.每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
3.1.6 producer
生产者的发送消息方式有三种
- 同步发送。不管结果如何直接发送
- 同步发送。也可以称之后异步阻塞,因为使用的是future.get,发送并返回结果
- 异步发送并回调
消费传递保障
-
最多一次
-
至少一次
-
正好一次
Kafka 分别通过 幂等性(Idempotence)和事务(Transaction)这两种机制实现了 精确一次(exactly once)语义。更多详见3.5
produce分区策略
- DefaultPartitioner 默认分区策略
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略
- UniformStickyPartitioner 纯粹的粘性分区策略
- UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配。
- RoundRobinPartitioner 分区策略
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
- 与key无关
粘性分区
Kafka2.4版本之后,支持粘性分区。Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 这个Batch可能包含多条消息,然后再将Batch打包发送。消息的发送必须要等到Batch满了或者linger.ms时间到了,才会发送。
linger.ms,默认是0ms,当达到这个时间后,kafka producer就会立刻向broker发送数据。batch.size,默认是16kb,当产生的消息数达到这个大小后,就会立即向broker发送数据。
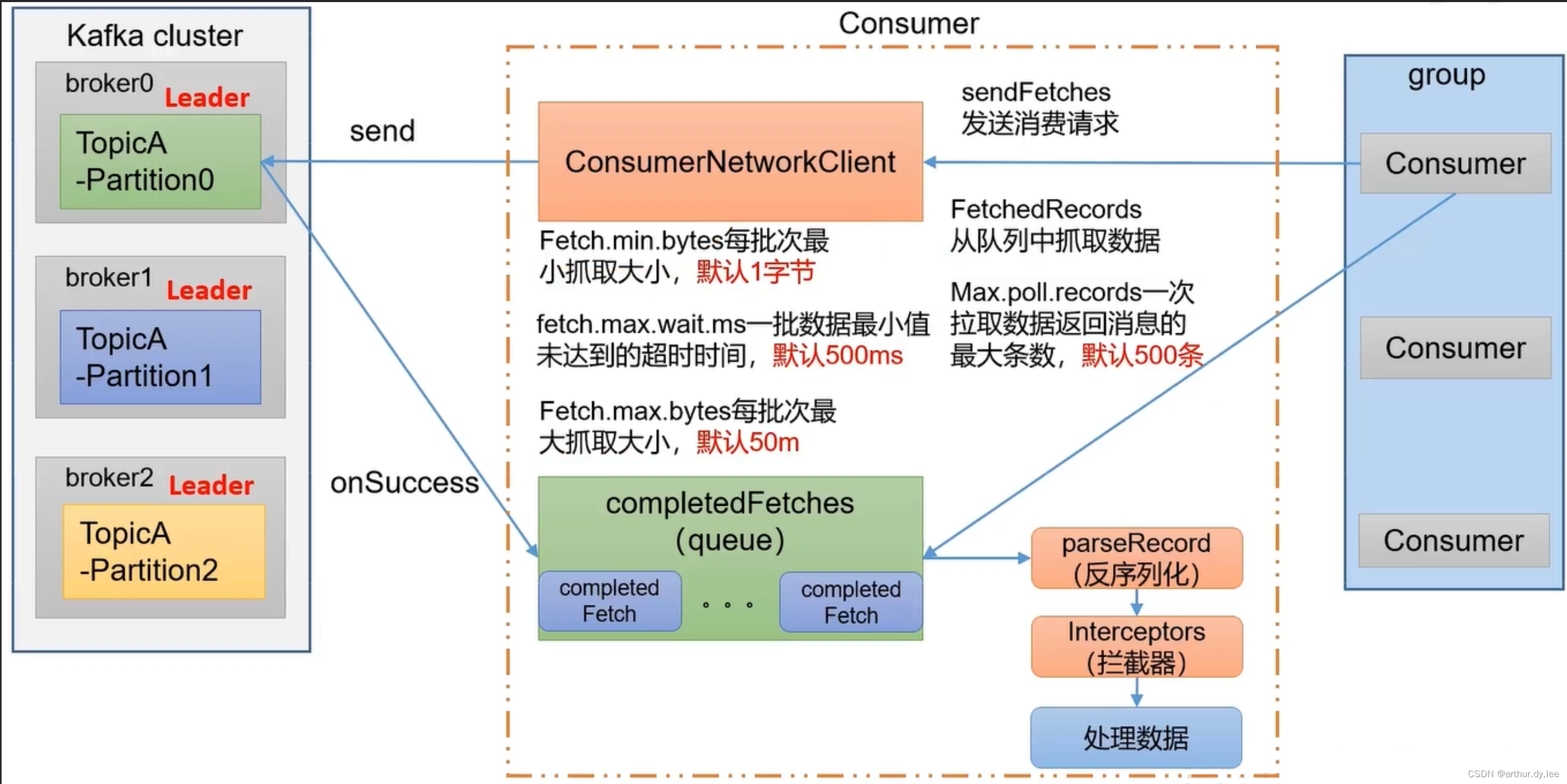
3.1.7 Consumer
Kafka采取拉取模型(poll),由自己控制消费速度,以及消费的进度,消费者可以按照任意的偏移量进行消费。比如消费者可以消费已经消费过的消息进行重新处理,或者消费最近的消息等等。
每个Consumer只能对应一个ConsumerGroup.
消费者组中的消费者实例个数不能超过分区的数量。否则会出现部分消费者闲置的情况发生。
consumer分区策略
- RoundRobinAssignor. 针对所有topic分区。它是采用轮询分区策略,是把所有的partition和所有的consumer列举出来,然后按照hashcode进行排序,最后再通过轮询算法来分配partition给每个消费者。
- RangeAssignor. RangeAssignor作用域为每个Topic。对于每一个Topic,将该Topic的所有可用partitions和订阅该Topic的所有consumers展开(字典排序),然后将partitions数量除以consumers数量,算数除的结果分别分配给订阅该Topic的consumers,算数除的余数分配给前一个或者前几个consumers。
- StickyAssignor. StickyAssignor有两个目标:首先,尽可能保证分区分配均衡(即分配给consumers的分区数最大相差为1);其次,当发生分区重分配时,尽可能多的保留现有的分配结果。当然,第一个目标的优先级高于第二个目标。
- CooperativeStickyAssignor. 上述三种分区分配策略均是基于eager协议,Kafka2.4.0开始引入CooperativeStickyAssignor策略。CooperativeStickyAssignor与之前的StickyAssignor虽然都是维持原来的分区分配方案,最大的区别是:StickyAssignor仍然是基于eager协议,分区重分配时候,都需要consumers先放弃当前持有的分区,重新加入consumer group;而CooperativeStickyAssignor基于cooperative协议,该协议将原来的一次全局分区重平衡,改成多次小规模分区重平衡。
kafka2.4版本支持:一个是kafka支持从follower副本读取数据,当然这个功能并不是为了提供读取性能。kafka存在多个数据中心,不同数据中心存在于不同的机房,当其中一个数据中心需要向另一个数据中心同步数据的时候,由于只能从leader replica消费数据,那么它不得不进行跨机房获取数据,而这些流量带宽通常是比较昂贵的(尤其是云服务器)。即无法利用本地性来减少昂贵的跨机房流量。
所以kafka推出这一个功能,就是帮助类似这种场景,节约流量资源。
再平衡触发三种情况
- consumer group中的新增或删除某个consumer,导致其所消费的分区需要分配到组内其他的consumer上;
- consumer订阅的topic发生变化,比如订阅的topic采用的是正则表达式的形式,如
test-*此时如果有一个新建了一个topictest-user,那么这个topic的所有分区也是会自动分配给当前的consumer的,此时就会发生再平衡; - consumer所订阅的topic发生了新增分区的行为,那么新增的分区就会分配给当前的consumer,此时就会触发再平衡。
3.1.8 消费者组
Consumer Grep (CG): 消费者组,有多个consumer组成,形成一个消费者组的条件是所有的消费者的groupid相同
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
- 如果向消费者组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置不会接收任何消息
kafka默认的分区策略是:一个分区只能由一个组内消费者消费。但自定义的分区策略可以打破这一限制!
因为所有的消息者都会提交它自身的offset到__comsumer_offsets中,后提交的offset会覆盖前面提交的offset,所以会引起重复消费和丢消息。例:consumer1提交了分区tp0的offset为10,consumer2提交了同一分区tp0的offset为12,如果consumer1重启,则会丢消息;如果consumer2提交的同一分区tp0的offset为8,则cosumer重启后会重复消费。
要实现真正的组内广播,需要自己保存每个消费者的offset,可以考虑通过保存本地文件、redis、数据库等试实现。
消费者组消费进度监控都怎么实现?
既然消费进度这么重要,我们应该怎么监控它呢?简单来说,有3种方法。
-
使用Kafka自带的命令行工具kafka-consumer-groups脚本。
-
使用Kafka Java Consumer API编程。
-
使用Kafka自带的JMX监控指标。
records-lag-max和records-lead-min,它们分别表示此消费者在测试窗口时间内曾经达到的最大的Lag值和最小的Lead值。这里的Lead值是指消费者最新消费消息的位移与分区当前第一条消息位移的差值。很显然,Lag和Lead是一体的两个方面:Lag越大的话,Lead就越小,反之也是同理。
一旦你监测到Lead越来越小,甚至是快接近于0了,你就一定要小心了,这可能预示着消费者端要丢消息了。为什么?我们知道Kafka的消息是有留存时间设置的,默认是1周,也就是说Kafka默认删除1周前的数据。倘若你的消费者程序足够慢,慢到它要消费的数据快被Kafka删除了,这时你就必须立即处理,否则一定会出现消息被删除,从而导致消费者程序重新调整位移值的情形。
3.1.9 消费者事务
如果想完成consumer端的精准一次性消费,那么需要 kafka消费端将消费过程和提交offset过程做原子绑定。 此时我们需要将kafka的offset保存到支持事务的自定义介质如MySQL中。
3.1.10 Coordinator
coordinator专门为 Consumer Group 服务,负责Group Rebalance 以及提供消费者组的注册、成员管理记录等元数据管理操作。
每个consumer group都会选择一个broker作为自己的coordinator,他是负责监控这个消费组里的各个消费者的心跳,以及判断是否宕机,然后开启rebalance。Kafka总会把你的各个消费组均匀分配给各个Broker作为coordinator来进行管理的。
3.1.11 Kraft
替代zk
由于 zk 的实现机制,无法承受大量的并发写操作,因此 zk 只能适用于中小集群的元数据管理,这也是为什么 kafka 要去 zk 的原因之一。
其他的原因的话,主要是考虑到运维成本方面,在强依赖 zk 的场景下,运维人员在使用 kafka 的时候不得不部署维护 zk 集群,因此会增加一定的运维难度和成本。
3.2 网络模型
kafka为什么没有选用netty作为底层的通讯基础?
作者的回复其实很简单:
1.出于性能的考虑
2.最初依赖太多外部的包,导致包膨胀。后期考虑不再依赖太多外部的资源,所以虽然苦逼的踩了很多坑但是结果还是很爽的
Kafka网络层采用的是Reactor模式,是一种基于事件驱动的模式。
Reacor模式是一种事件驱动机制,他逆转了事件处理的流程,不再是主动地等事件就绪,而是它提前注册好的回调函数,当有对应事件发生时就调用回调函数。 由陈硕所述,Reactor即为非阻塞IO + IO复用。它的核心思想就是利用IO复用技术来监听套接字上的读写事件,一旦某个fd上发生相应事件,就反过来处理该套接字上的回调函数。
3.2.1 reactor模型
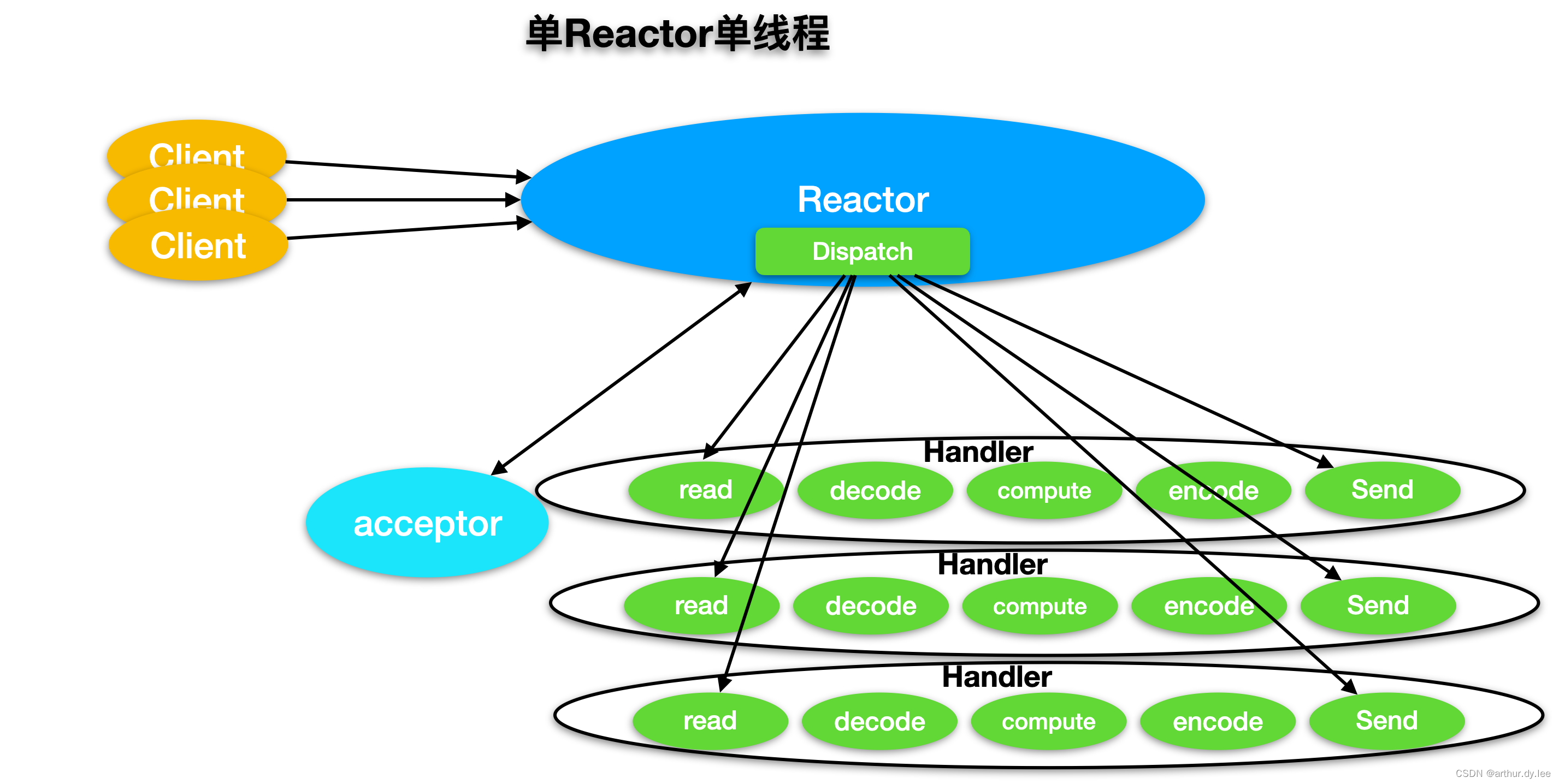
1. 单Reactor单线程
1)可以实现通过一个阻塞对象监听多个链接请求
2)Reactor对象通过select监听客户端请求事件,通过dispatch进行分发
3)如果是建立链接请求,则由Acceptor通过accept处理链接请求,然后创建一个Handler对象处理完成链接后的各种事件
4)如果不是链接请求,则由Reactor分发调用链接对应的Handler来处理
5)Handler会完成Read->业务处理->send的完整业务流程
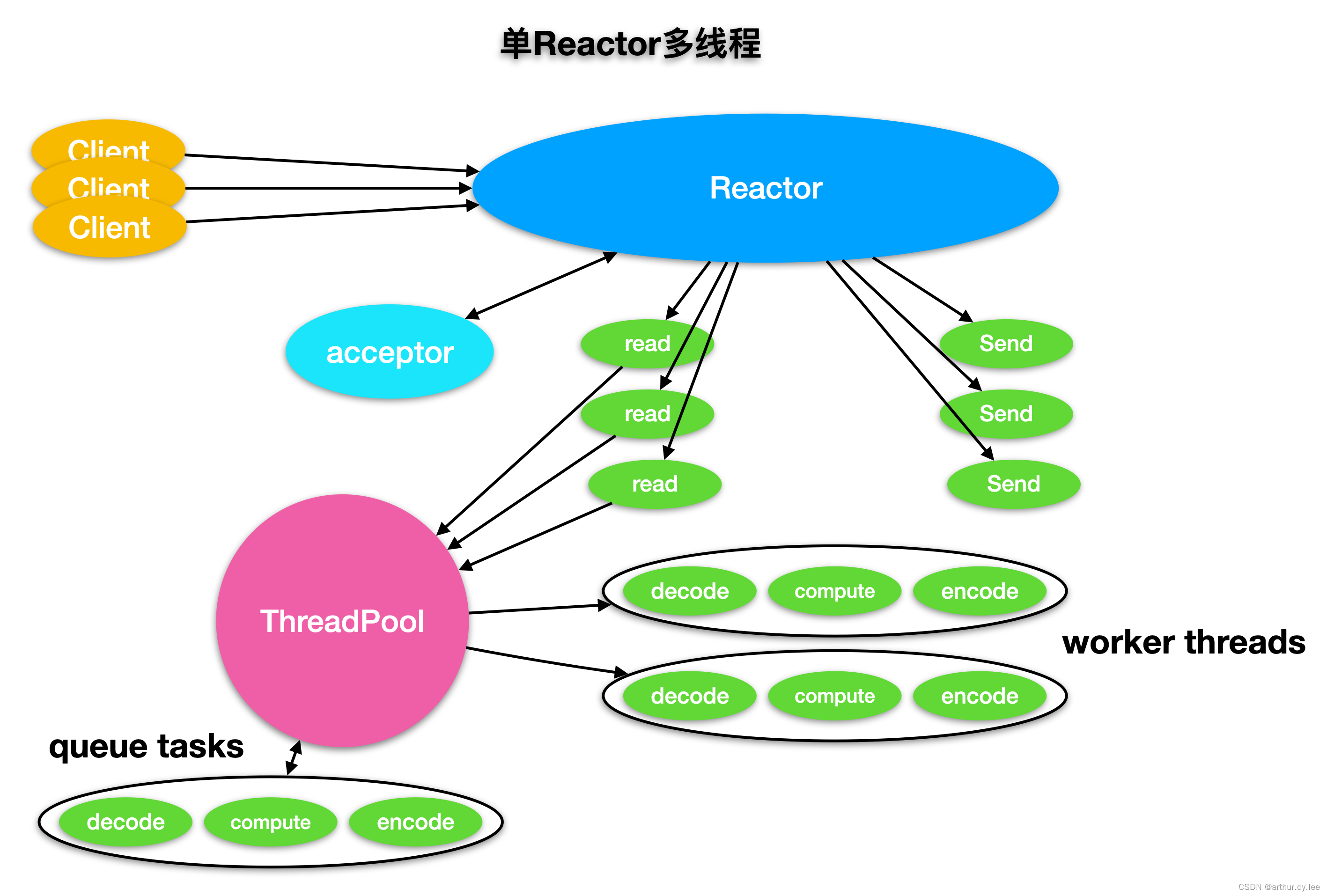
2. 单Reactor多线程
1)Reactor对象通过select监听客户端请求事件,收到事件后,通过dispatch分发
2)如果是建立链接请求,则由Acceptor通过accept处理链接请求,然后创建一个Handler对象处理完成链接后的各种事件
3)如果不是链接请求,则由Reactor分发调用链接对应的Handler来处理
4)Handler只负责事件响应不做具体业务处理
5)通过read读取数据后,分发到worker线程池处理,处理完成后返回给Handler,Handler收到后,通过send将结果返回给client
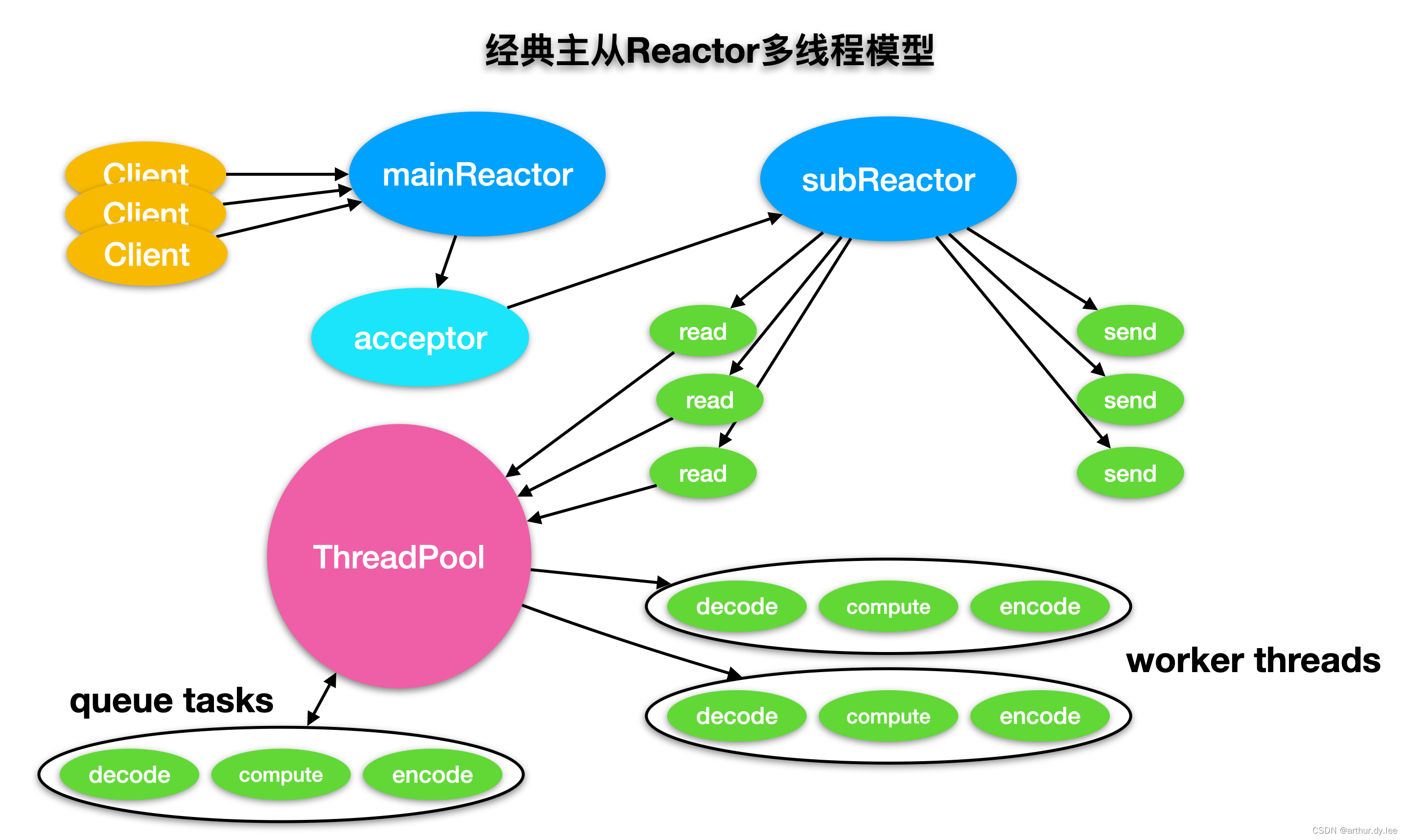
3. 主从Reactor多线程
1)Reactor主线程MainReactor对象通过select监听链接事件,通过Acceptor处理
2)当Acceptor处理链接事件后,MainReactor将链接分配给SubReactor
3)SubReactor将链接加入到队列进行监听,并创建Handler进行事件处理
4)当有新事件发生时,SubReactor就会调用对应的Handler处理
5)Handler通过read读取数据,分发到worker线程池处理,处理完成后返回给Handler,Handler收到后,通过send将结果返回给client
6)Reactor主线程可以对应多个Reactor子线程
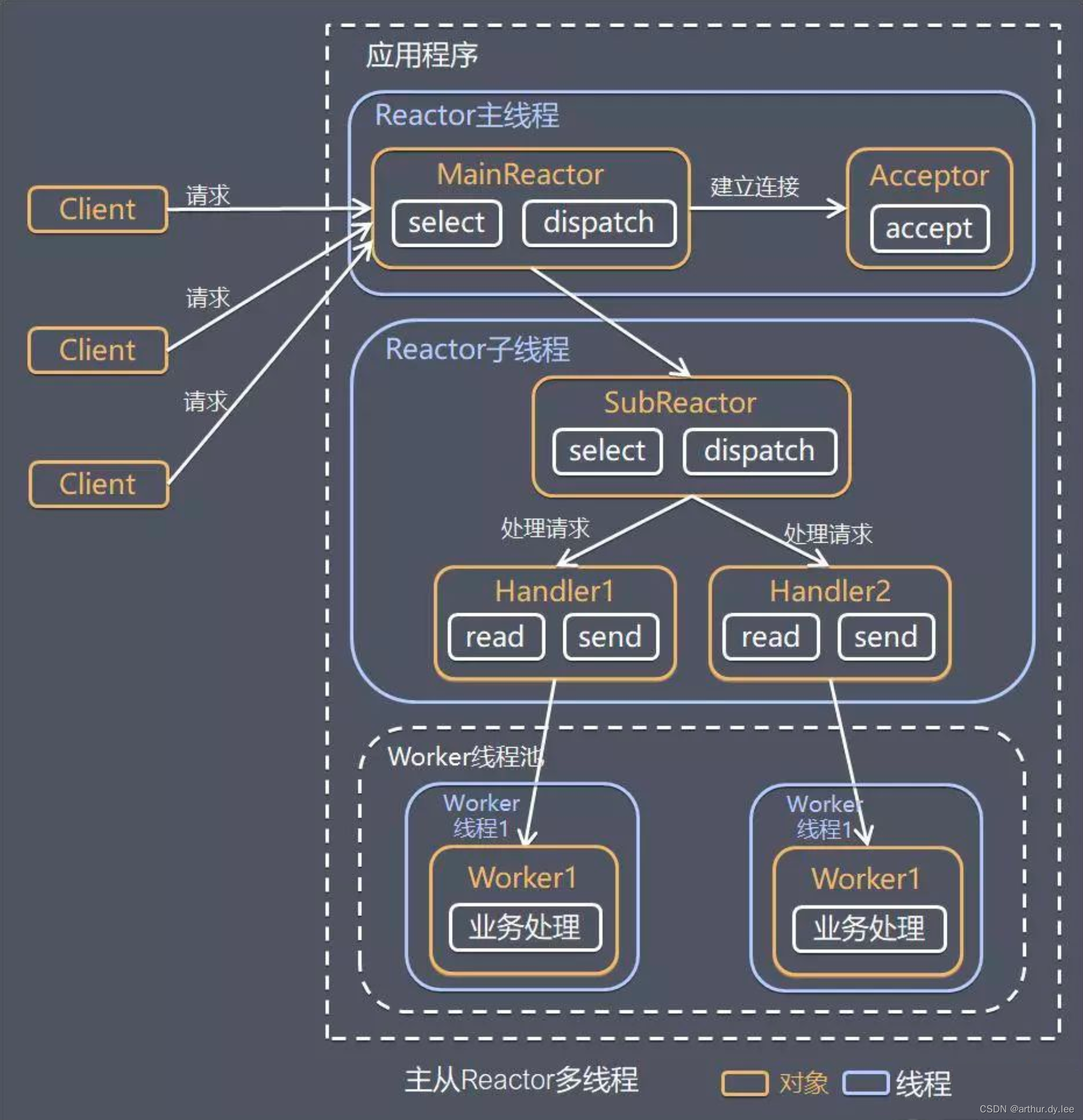
更详细的版本:
- Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件;
- Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理;
- SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件;
- 当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应;
- Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
- Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
- Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
总结
三种模式用生活案例来理解
1)单Reactor单线程,前台接待员和服务员是同一个人,全程为顾客服务
2)单Reactor多线程,1个前台接待员,多个服务员,接待员只负责接待
3)主从Reactor多线程,多个前台接待员,多个服务员
3.2.2 kafka reactor模型
kafka是基于主从Reactor多线程进行设计的。Acceptor是一个继承于AbstractServerThread的线程类,Acceptor的主要目的是监听并且接收Client的请求,同时,建立数据传输通道(SocketChannel),然后通过轮询的方式交给一个Processor处理。这里还有一个块通道(BlockingChannel),用于连接Processor和Handler。
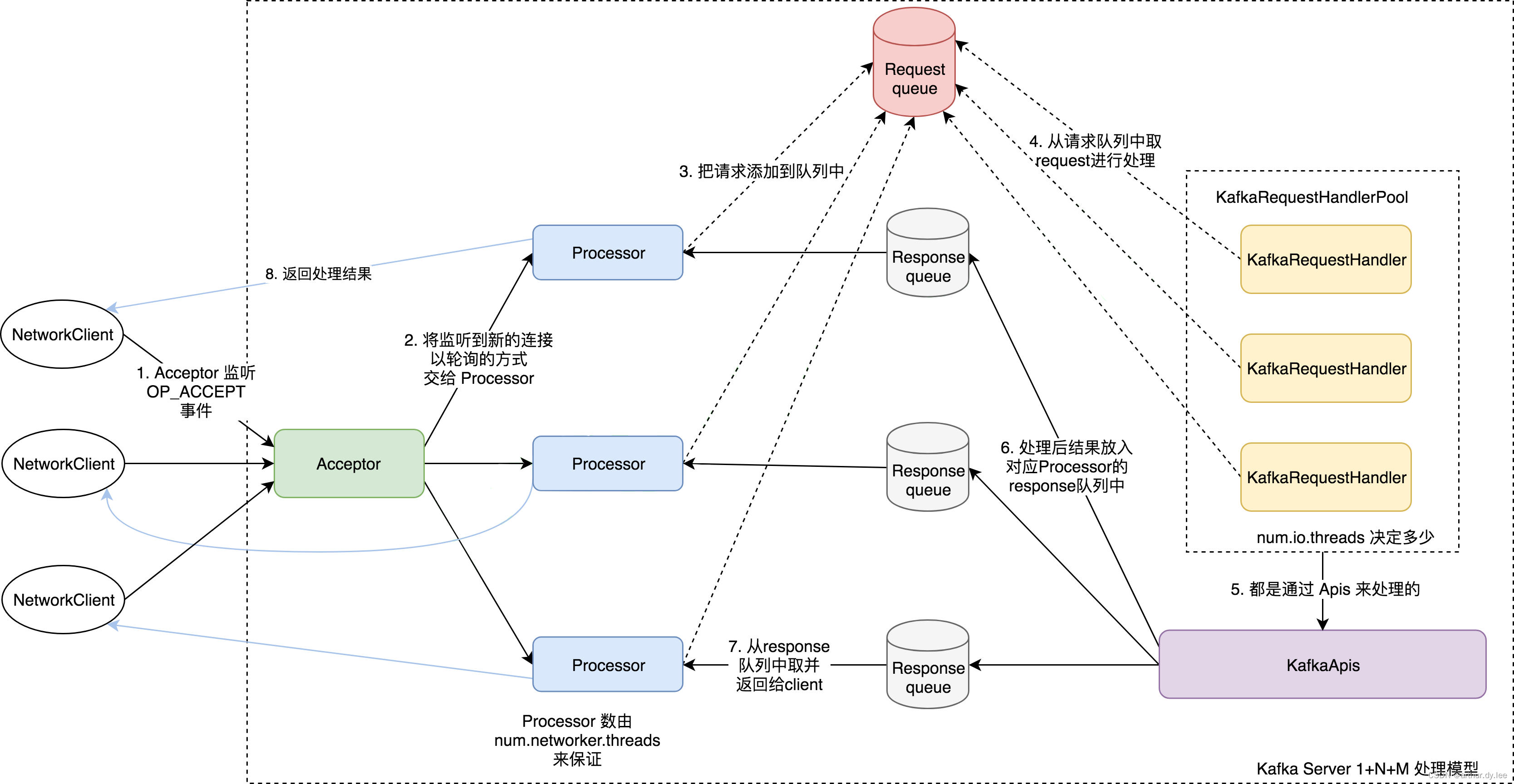
MainReactor(Acceptor)只负责监听OP_ACCEPT事件, 监听到之后把SocketChannel 传递给 SubReactor(Processor), 每个Processor都有自己的Selector。SubReactor会监听并处理其他的事件,并最终把具体的请求传递给KafkaRequestHandlerPool。

IO线程池处中的线程才是执行请求逻辑的线程。Broker端参数num.io.threads控制了这个线程池中的线程数。目前该参数默认值是8,表示每台Broker启动后自动创建8个IO线程处理请求。
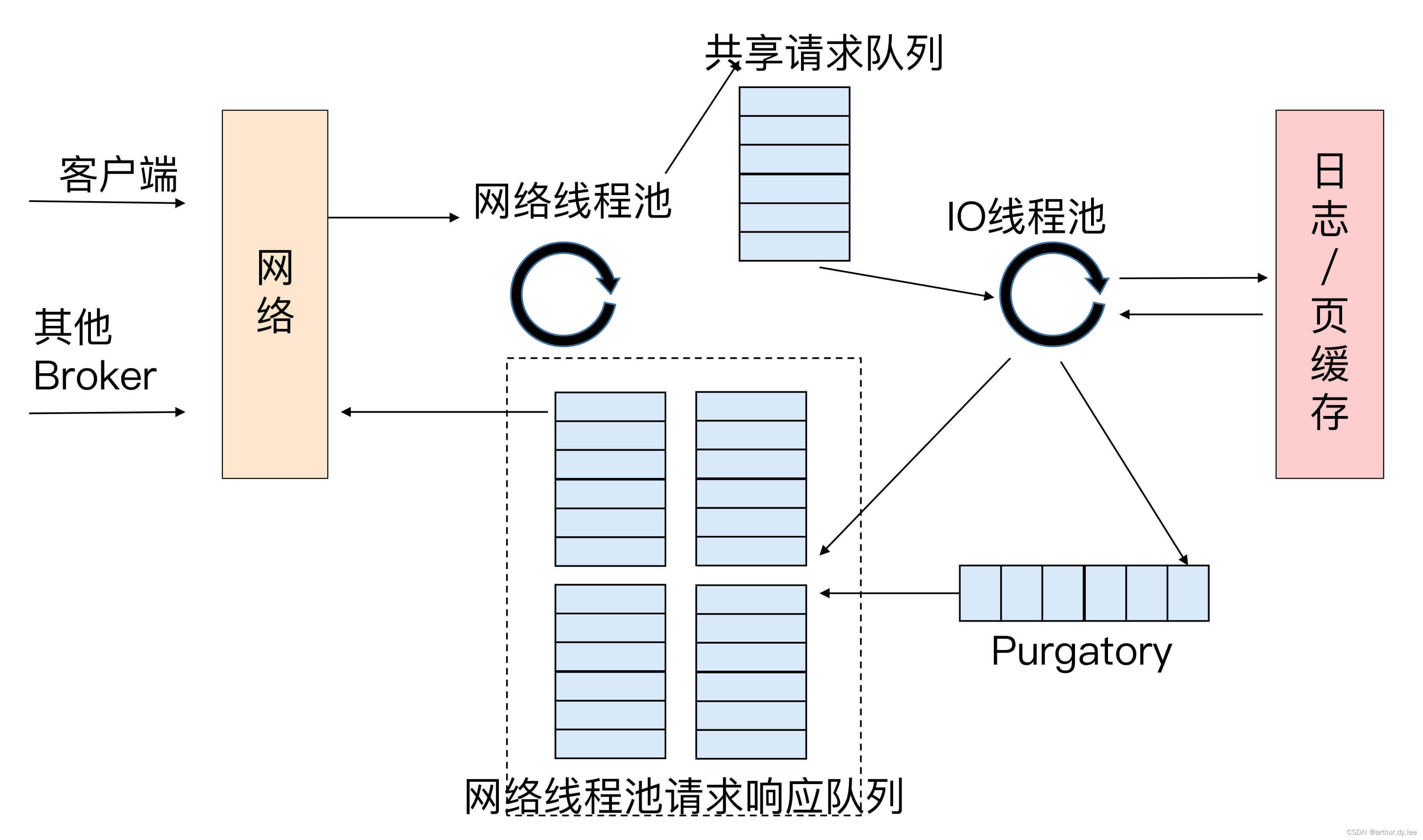
请求队列和响应队列的差别:请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的。这么设计的原因就在于,Dispatcher只是用于请求分发而不负责响应回传,因此只能让每个网络线程自己发送Response给客户端,所以这些Response也就没必要放在一个公共的地方。
图中有一个叫Purgatory的组件,这是Kafka中著名的“炼狱”组件。它是用来缓存延时请求(Delayed Request)的。所谓延时请求,就是那些一时未满足条件不能立刻处理的请求。比如设置了acks=all的PRODUCE请求,一旦设置了acks=all,那么该请求就必须等待ISR中所有副本都接收了消息后才能返回,此时处理该请求的IO线程就必须等待其他Broker的写入结果。
控制类请求和数据类请求分离
社区于2.3版本把PRODUCE和FETCH这类请求称为数据类请求,把LeaderAndIsr、StopReplica这类请求称为控制类请求。为什么要分开呢?因为控制类请求有这样一种能力:它可以直接令数据类请求失效!
如何实现呢?社区完全拷贝了这张图中的一套组件,实现了两类请求的分离。也就是说,Kafka Broker启动后,会在后台分别创建两套网络线程池和IO线程池的组合,它们分别处理数据类请求和控制类请求。至于所用的Socket端口,自然是使用不同的端口了,你需要提供不同的listeners配置,显式地指定哪套端口用于处理哪类请求。
3.2.4 关键类
SocketServer
这个类是网络通信的核心类,它持有这Acceptor和 Processor对象。
AbstractServerThread
AbstractServerThread是Acceptor线程和Processor线程的抽象基类,它定义了一个抽象方法wakeup() ,主要是用来唤醒Acceptor 线程和 Processor 对应的Selector的, 当然还有一些共用方法
Acceptor 和 Processor
Acceptor 线程类:继承自AbstractServerThread, 这是接收和创建外部 TCP 连接的线程。每个 SocketServer 实例一般会创建一个 Acceptor 线程(如果listeners配置了多个就会创建多个Acceptor)。它的唯一目的就是创建连接,并将接收到的 SocketChannel(SocketChannel通道用于传输数据) 传递给下游的 Processor 线程处理,Processor主要是处理连接之后的事情,例如读写I/O。
- 监听
OP_ACCEPT事件,不断循环获取已经accept的连接 - 判断每个ip的连接数是否超过quota限制
- 通过round-robin的方式,选择
Processor,放入Processor对应的newConnections缓存中
Processor 线程类:这是处理单个TCP 连接上所有请求的处理线程。每个Acceptor 实例创建若干个(num.network.threads)Processor 线程。Processor 线程负责将接收到的 SocketChannel(SocketChannel通道用于传输数据。), 注册读写事件,当数据传送过来的时候,会立即读取Request数据,通过解析之后, 然后将其添加到 RequestChannel 的 requestQueue 队列上,同时还负责将 Response 返还给 Request 发送方。
-
configureNewConnections(): 处理新建的连接,监听OP_READ事件,等待读取数据 -
poll()
- 真正读取数据,并放入接收缓存队列
stagedReceives,缓存所有channel的请求 - 拿出每个channel的第一个请求,解析协议头部,放入
completedReceives缓存中 - 如果channel写出ready,则进行write,将response返回给客户端
- 真正读取数据,并放入接收缓存队列
-
processCompletedReceives():将请求解析为Request并放入requestQueue缓存
KafkaApis
负责处理broker支持的各种通信协议,如PRODUCE/FETCH/LIST_OFFSETS/LEADER_AND_ISR/HEARTBEAT等
KafkaRequestHandlerPool
负责接收消息,处理SocketServer接收的请求,并构建response返回给SocketServer。此处重要监控指标:RequestHandlerAvgIdlePercent
- 从
requestQueue中拿去request,并根据协议头,选择对应的KafkaApi进行处理 - 使用回调,将处理完成的response通过
KafkaChannel放入当前channel对应的Processor的responseQueue中
Acceptor 和 Processor的关系
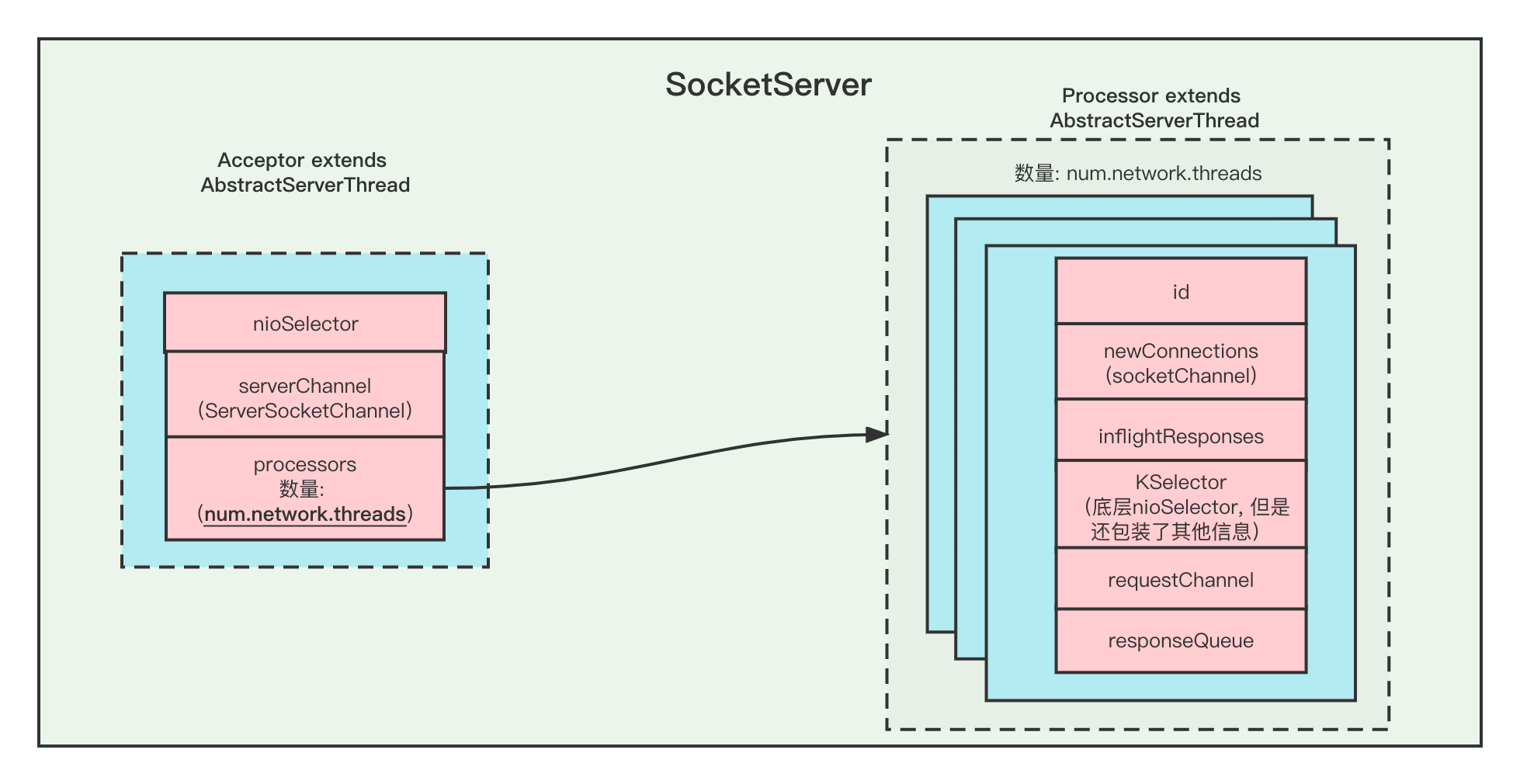
- 这两个类都是 AbstractServerThead的实现类,超类是
Runnable可运行的。 - 每个Acceptor持有
num.network.threads个 Processor 线程, 假如配置了多个listeners,那么总共Processor线程数是listeners*num.network.threads. - Acceptor 创建的是ServerSocketChannel通道,这个通道是用来监听新进来的TCP链接的通道,
通过serverSocketChannel.accept()方法可以拿到SocketChannel通道用于传输数据。 - 每个Processor 线程都有一个唯一的id,并且通过Acceptor拿到的SocketChannel会被暂时放入到
newConnections队列中 - 每个Processor 都创建了自己的Selector
- Processor会不断的从自身的
newConnections队列里面获取新SocketChannel,并注册读写事件,如果有数据传输过来,则会读取数据,并解析成Request请求。
3.2.4 通信流程
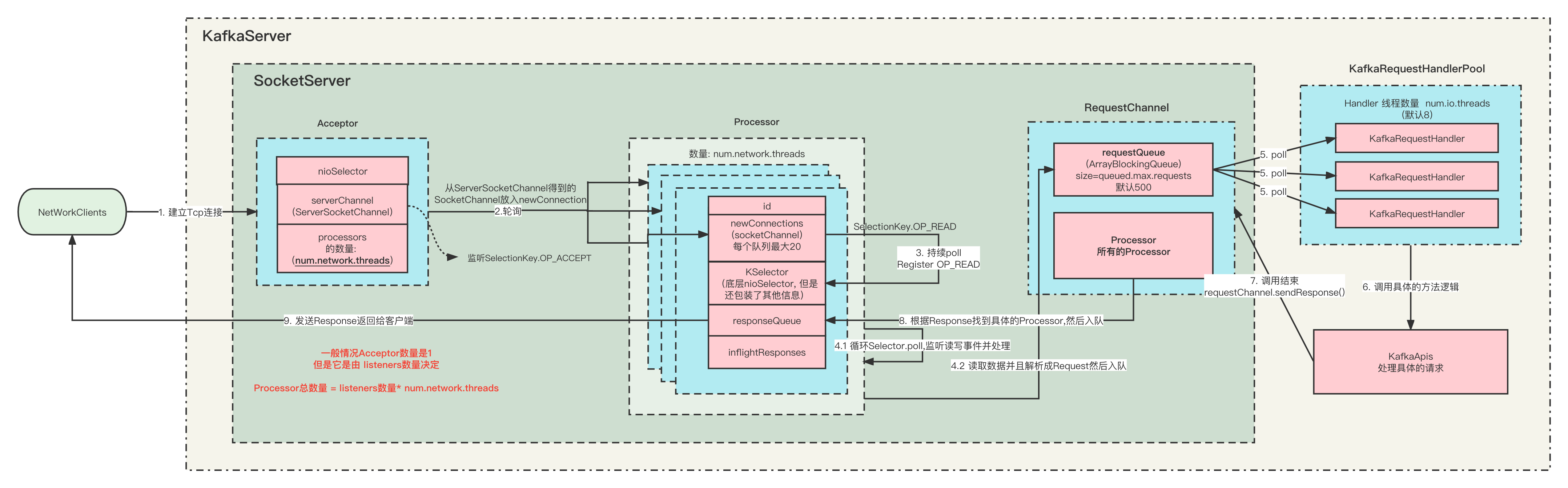
- KafkaServer启动的时候,会根据
listeners的配置来初始化对应的实例。 - 一个
listeners对应一个Acceptor,一个Acceptor持有若干个(num.network.threads)Processor实例。 - Acceptor 中的nioSelector注册的是ServerSocketChannel通道,并监听OP_ACCEPT事件,它只负责 TCP 创建和连接,不包含读写数据。
- 当Acceptor监听到新的连接之后,就会通过调用
socketChannel = serverSocketChannel.accept()拿到SocketChannel,然后把SocketChannel保存在Processor里面的newConnection队列中。 那么具体保存在哪个Processor中呢?当然是轮询分配了,确保负载均衡嘛。当然每个Processor的newConnection队列最大只有20,并且是代码写死的。如果一个Processor满了,则会寻找下一个存放,如果所有的都满了,那么就会阻塞。一个Acceptor的所有Processor最大能够并发处理的请求是20 * num.network.threads。 - Processor会持续的从自己的
newConnection中poll数据,拿到SocketChannel之后,就把它注册到自己的Selector中,并且监听事件 OP_READ。 如果newConnection是空的话,poll的超时时间是 300ms。 - 监听到有新的事件,比较READ,则会读取数据,并且解析成Request, 把Request放入到 RequestChannel中的
requestQueue阻塞队列中。所有的待处理请求都是临时放在这里面。这个队列也有最大值queued.max.requests(默认500),超过这个大小就会阻塞。 - KafkaRequestHandlerPool中创建了很多(
num.io.threads(默认8))的KafkaRequestHandler,用来处理Request, 他们都会一直从RequestChannel中的requestQueue队列中poll新的Request,来进行处理。 - 处理Request的具体逻辑是KafkaApis里面。当Request处理完毕之后,会调用requestChannel.sendResponse()返回Response。
- 当然,请求Request和返回Response必须是一一对应的, 你这个请求是哪个Processor监听到的,则需要哪个Processor返回, 他们通过id来标识。
- Response也不是里面返回的,而是先放到Processor中的ResponseQueue队列中,然后慢慢返回给客户端。
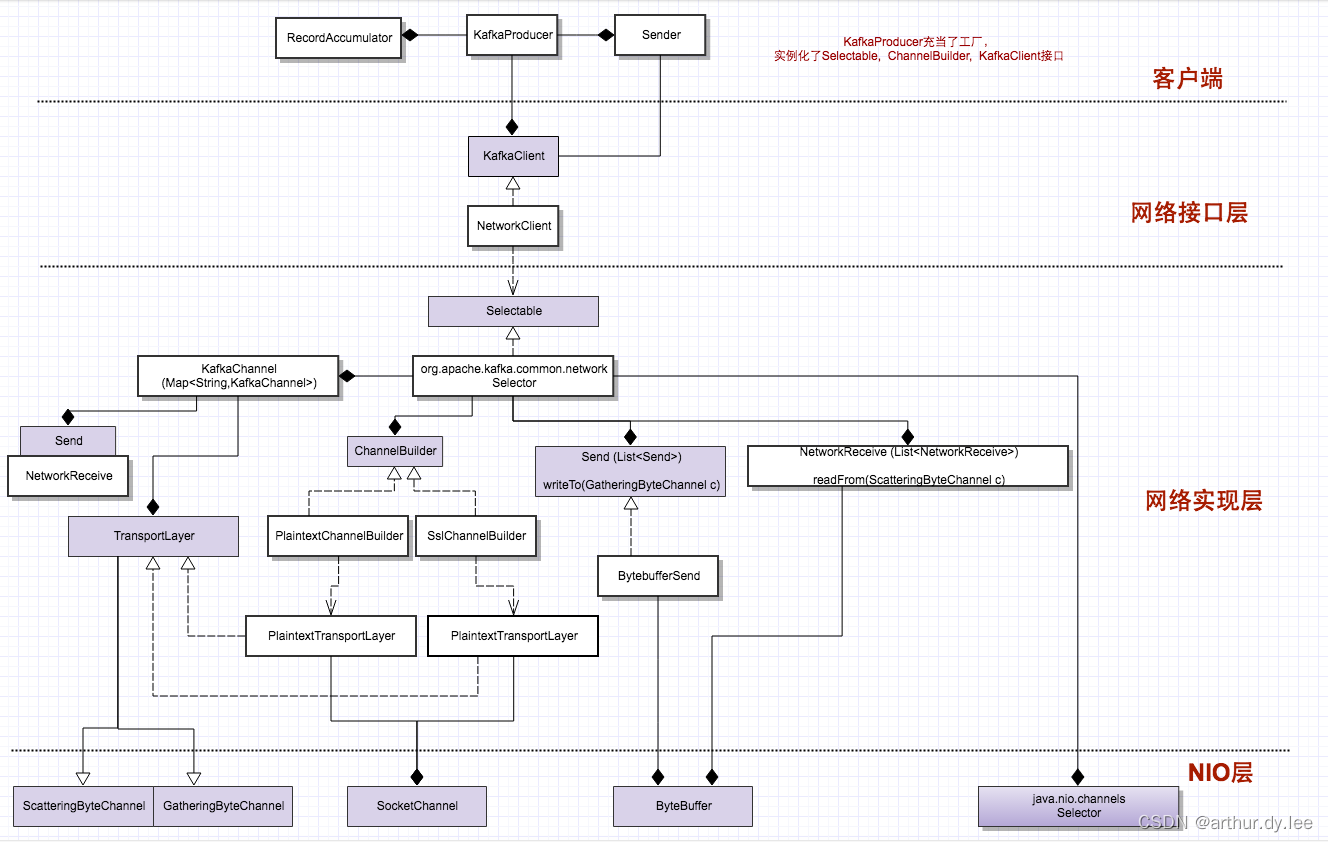
3.3 存储模型和文件系统
消息的可靠性由多副本机制来保障,而不是由同步刷盘这种严重影响性能的行为来保障。
国内部分银行在使用kafka时就会设置副本数为5。同时,如果能够在分配分区副本的时候引入机架信息(broker.rack参数),那么还要应对机架整体宕机的风险。
3.3.1 副本同步
我们知道,kafka每个topic的partition会有N个副本,kafka通过多副本机制实现故障自动转移,当kafka集群中一个broker失效情况下,会在N个副本中重新选出一个broker作为leader提供服务,从而做到高可用。N个副本中,其中一个为leader,其他的都为follower,leader处理partition的所有读写请求,follower会定期地复制leader上的数据。
所谓同步,必须满足两个条件:
- 副本节点必须能与zookeeper保持会话(心跳机制)
- 副本能复制leader上的所有写操作,并且不能落后太多(卡主或滞后的副本控制由replica.lag.time.max.ms配置)

默认情况下,Kafka topic的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常应用中将其值(由broker的参数offsets.topic.replication.factor指定)大小设定为1。所有的副本(replicas)统称为AR (Assigned Replicas)。ISR是AR的一个子集,由leader维护ISR列表,follower从Leader同步数据有一些延迟,任意一个超过阈值都会把follower踢出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放到OSR中。AR = ISR + OSR
3.3.1.1 高水位
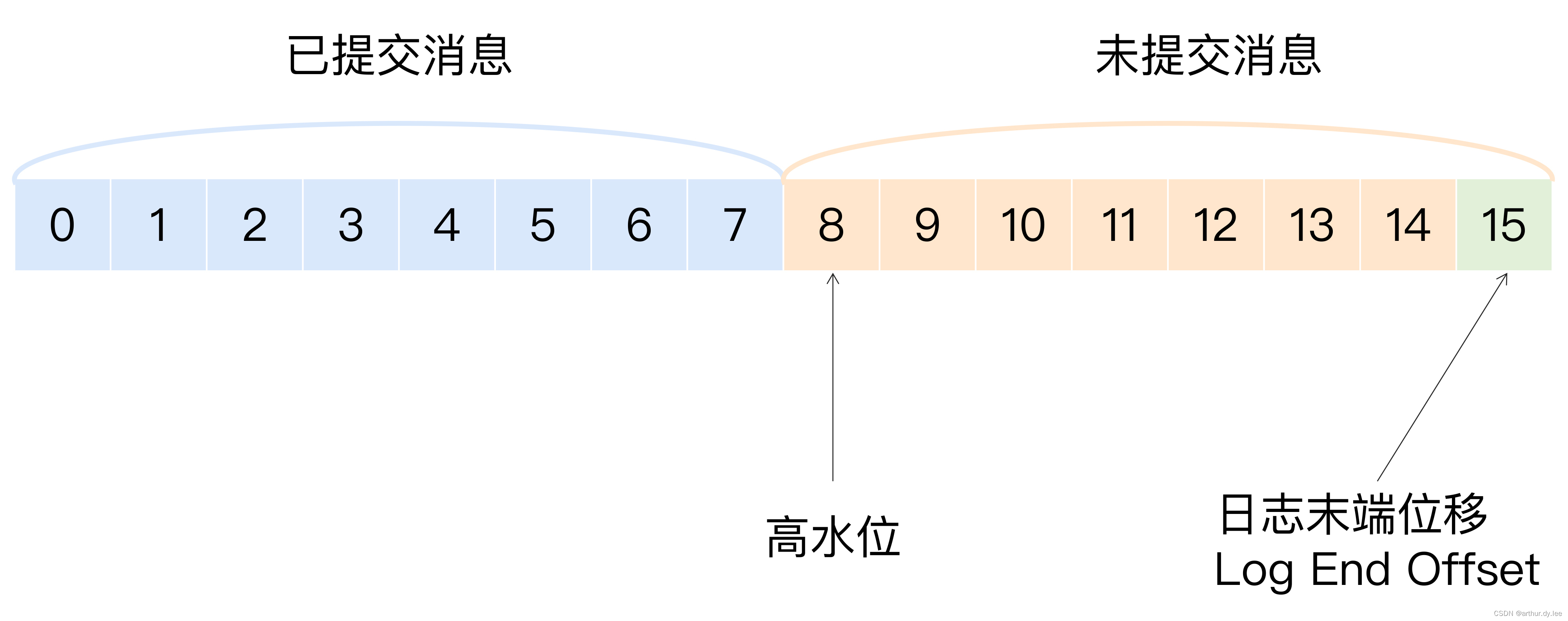
HW(HighWatermark)俗称高水位,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。
在分区高水位以下的消息被认为是已提交消息,反之就是未提交消息。
另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立即消费,leader会等待该消息被所有ISR中的replicas都同步后,才更新HW,此时消息才能被consumer消费,这样就保证了如果Leader所在的broker失效,该消息仍可从新选举的leader中获取。对于来自内部的broker的读取请求,没有HW的限制。
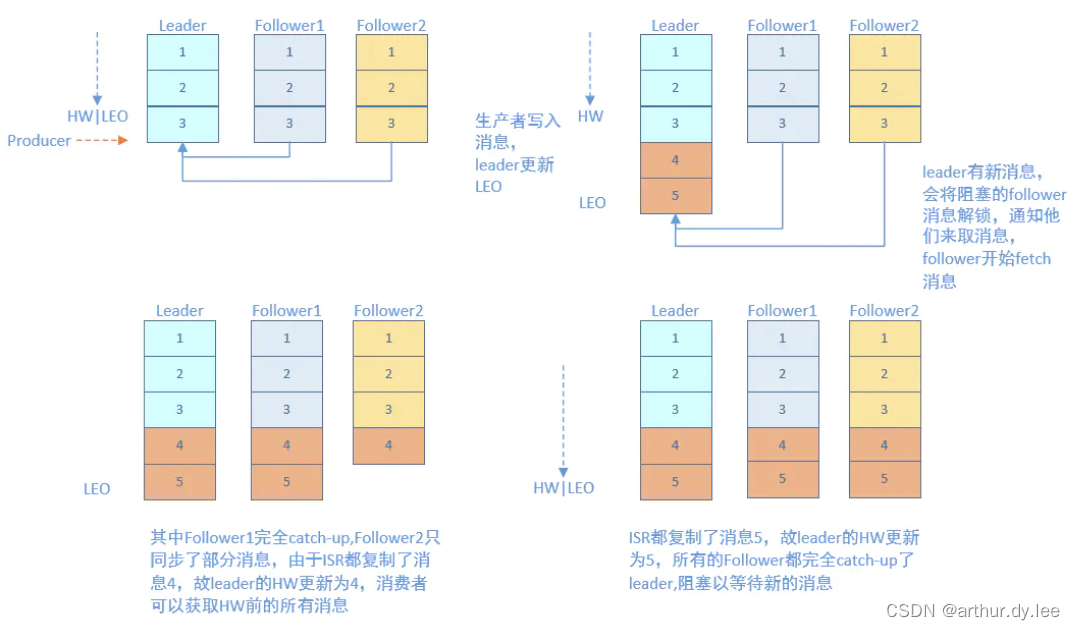
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制,而是基于ISR的动态复制方案。
基于ISR的动态复制指的是ISR是由Leader动态维护的,如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。而Kafka这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率,实现了可用性与数据一致性的动态平衡(也可以称作可调整一致性)
高水位的作用主要有2个:
- 定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
- 帮助Kafka完成副本同步。
3.3.1.2 Leader Epoch
Follower副本的高水位更新需要一轮额外的拉取请求才能实现,Leader副本高水位更新和Follower副本高水位更新在时间上是存在错配的。这种错配是很多“数据丢失”或“数据不一致”问题的根源。基于此,社区在0.11版本正式引入了Leader Epoch概念。
Leader Epoch,我们大致可以认为是Leader版本。它由两部分数据组成。
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的Leader被认为是过期Leader,不能再行使Leader权力。
- 起始位移(Start Offset)。Leader副本在该Epoch值上写入的首条消息的位移。
3.3.1.3 LSO(Log Stable Offset)
注意,上面没有讨论Kafka事务,因为事务机制会影响消费者所能看到的消息的范围,它不只是简单依赖高水位来判断。它依靠一个名为LSO(Log Stable Offset)的位移值来判断事务型消费者的可见性。
3.3.2 ISR
Kafka 动态维护了一个同步状态的备份的集合 (a set of in-sync replicas), 简称 ISR ,在这个集合中的节点都是和 leader 保持高度一致的,只有这个集合的成员才 有资格被选举为 leader,一条消息必须被这个集合 所有 节点读取并追加到日志中了,这条消息才能视为提交。这个 ISR 集合发生变化会在 ZooKeeper 持久化,正因为如此,这个集合中的任何一个节点都有资格被选为 leader 。这对于 Kafka 使用模型中, 有很多分区和并确保主从关系是很重要的。因为 ISR 模型和 f+1 副本,一个 Kafka topic 冗余 f 个节点故障而不会丢失任何已经提交的消息。
我们认为对于希望处理的大多数场景这种策略是合理的。在实际中,为了冗余 f 节点故障,大多数投票和 ISR 都会在提交消息前确认相同数量的备份被收到(例如在一次故障生存之后,大多数的 quorum 需要三个备份节点和一次确认,ISR 只需要两个备份节点和一次确认),多数投票方法的一个优点是提交时能避免最慢的服务器。但是,我们认为通过允许客户端选择是否阻塞消息提交来改善,和所需的备份数较低而产生的额外的吞吐量和磁盘空间是值得的。
Kafka 采取了一种稍微不同的方法来选择它的投票集。 Kafka 不是用大多数投票选择 leader 。
如果选择写入时候需要保证一定数量的副本写入成功,读取时需要保证读取一定数量的副本,读取和写入之间有重叠。这样的读写机制称为 Quorum。quorum 算法更常用于共享集群配置(如 ZooKeeper )
大多数投票的缺点是,多数的节点挂掉让你不能选择 leader。要冗余单点故障需要三份数据,并且要冗余两个故障需要五份的数据。根据我们的经验,在一个系统中,仅仅靠冗余来避免单点故障是不够的,但是每写5次,对磁盘空间需求是5倍, 吞吐量下降到 1/5,这对于处理海量数据问题是不切实际的。这可能是为什么 quorum 算法更常用于共享集群配置(如 ZooKeeper ), 而不适用于原始数据存储的原因,例如 HDFS 中 namenode 的高可用是建立在 基于投票的元数据 ,这种代价高昂的存储方式不适用数据本身。
另一个重要的设计区别是,Kafka 不要求崩溃的节点恢复所有的数据,在这种空间中的复制算法经常依赖于存在 “稳定存储”,在没有违反潜在的一致性的情况下,出现任何故障再恢复情况下都不会丢失。 这个假设有两个主要的问题。首先,我们在持久性数据系统的实际操作中观察到的最常见的问题是磁盘错误,并且它们通常不能保证数据的完整性。其次,即使磁盘错误不是问题,我们也不希望在每次写入时都要求使用 fsync 来保证一致性, 因为这会使性能降低两到三个数量级。我们的协议能确保备份节点重新加入ISR 之前,即使它挂时没有新的数据, 它也必须完整再一次同步数据。
消息从生产者写入kafka,首先写入副本leader,然后follower副本同步leader的消息。同步消息落后的副本会被踢出ISR,所以ISR的概念是,能追赶上leader的所有副本。
replica.lag.time.max.ms参数:如果副本落后超过这个时间就判定为落后了,直到它回来。消息复制分为异步和同步,ISR是动态的,有进有出。
Broker端参数replica.lag.time.max.ms参数值。这个参数的含义是Follower副本能够落后Leader副本的最长时间间隔,当前默认值是10秒。这就是说,只要一个Follower副本落后Leader副本的时间不连续超过10秒,那么Kafka就认为该Follower副本与Leader是同步的,即使此时Follower副本中保存的消息明显少于Leader副本中的消息。
3.3.3 segment文件存储
kafka的每个分区数据如果不加以控制就会无限堆积,所以kafka的分区存在分片机制即每超过1g就进行分片segement,每个分片单独具有一个log和一个index,log是实实在在存储数据的,index可以看着是log的索引。
1.segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,分别表示为segment索引文件、数据文件.
index全部映射到memory直接操作,避免segment file被交换到磁盘增加IO操作次数。

2.segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
00000000000000368769.index:假设这个消息中有N条消息,第3条消息在index文件中对应的是497,也就是说在log文件中,第3条消息的偏移量为497。

满足以下条件,就会切分日志文件,产生一个新的segment文件:
- segment的默认大小是1073741824 bytes(1G),这个参数可以由 log.segment.bytes设置
- 当消息的最大的时间戳和当前系统时间戳的差值较大,也会创建一个新的Segment,有一个默认参数
,168 个小时(一周):log.roll.hours=168 | log.roll.ms 如果服务器上此写入的消息是一周之前的,旧的Segment旧不写了,重新创建一个新的Segment。 - 当offset索引文件或者timestamp索引文件达到了一定的大小,默认是10M:log.index.size.max.bytes 。也就是索引文件写满了,数据文件也要跟着拆分。
3.3.4 page cache
Kafka 对消息的存储和缓存严重依赖于文件系统。人们对于“磁盘速度慢”具有普遍印象,事实上,磁盘的速度比人们预期的要慢的多,也快得多,这取决于人们使用磁盘的方式。
使用6个7200rpm、SATA接口、RAID-5的磁盘阵列在JBOD配置下的顺序写入的性能约为600MB/秒,但随机写入的性能仅约为100k/秒,相差6000倍以上。
线性的读取和写入是磁盘使用模式中最有规律的,并且由操作系统进行了大量的优化。
- read-ahead 是以大的 data block 为单位预先读取数据
- write-behind 是将多个小型的逻辑写合并成一次大型的物理磁盘写入
Kafka重度依赖底层OS提供的page cache功能。当上层有写操作时,OS只是将数据写入到page cache,同时标记page属性为dirty。当读操作发生时,先从page cache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
实际上page cache是把尽可能多的空闲内存都当做磁盘缓存来使用,同时如果有其它进程申请内存,回收page cache的代价又很小,所以现代的OS都支持page cache。使用page cache功能同时可以避免在JVM内部缓存数据,JVM为我们提供了强大的GC功能,同时也引入了一些问题不适用与Kafka的设计。如果在heap內管理缓存,JVM的GC线程会频繁扫描heap空间,带来不必要的开销。如果heap过大,执行一次Full GC对系统的可用性来说将会是极大的挑战。此外所有在JVM內的对象都不免带有一个Object Overhead(对象数量足够多时,不可小觑此部分内存占用),内存的有效空间利用率会因此降低。所有In-Process Cache在OS中都有一份同样的page cache。所以通过将缓存只放在page cache,可以至少让可用缓存空间翻倍。如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的page cache依然可以继续使用。
3.3.5 日志刷盘
没有fsync系统调用强制刷盘类似rocket的同步异步刷盘机制,个人感觉两个原因那,
一:如果应用程序每写入1次数据,都调用一次fsync,那性能损耗就很大,所以一般都会 在性能和可靠性之间进行权衡。因为对应一个应用来说,虽然应用挂了,只要操作系统 不挂,数据就不会丢。
二:kafka是多副本的,当你配置了同步复制之后。多个副本的数据都在page cache里 面,出现多个副本同时挂掉的概率比1个副本挂掉,概率就小很多了。
但是可配合配置实现“同步”
-
日志数量。当达到下面的消息数量时,会将数据flush到日志文件中。默认10000。
log.flush.interval.messages=10000
-
周期性的刷盘。当达到下面的时间(ms)时,执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。默认3000ms。
log.flush.interval.ms=1000
log.flush.scheduler.interval.ms = 3000
log.flush.interval.ms如果没有设置,则使用log.flush.scheduler.interval.ms
注意:定时任务里只会根据时间策略进行判断是否刷盘,根据大小判断是在append追加日志时进行的判断
broker写数据以及同步的一个过程。broker写数据只写到PageCache中,而pageCache位于内存。这部分数据在断电后是会丢失的。pageCache的数据通过linux的flusher程序进行刷盘。刷盘触发条件有三:
- 可用内存低于阀值
- 主动调用sync或fsync函数
- dirty data时间达到阀值。dirty是pagecache的一个标识位,当有数据写入到pageCache时,pagecache被标注为dirty,数据刷盘以后,dirty标志清除。
Kafka没有提供同步刷盘的方式。同步刷盘在RocketMQ中有实现,实现原理是将异步刷盘的流程进行阻塞,等待响应,类似ajax的callback或者是java的future。下面是一段rocketmq的源码。
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
service.putRequest(request);
boolean flushOK = request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout()); // 刷盘
也就是说,理论上,要完全让kafka保证单个broker不丢失消息是做不到的,只能通过调整刷盘机制的参数缓解该情况。比如,减少刷盘间隔,减少刷盘数据量大小。时间越短,性能越差,可靠性越好(尽可能可靠)。这是一个选择题。
为了解决该问题,kafka通过producer和broker协同处理单个broker丢失参数的情况。一旦producer发现broker消息丢失,即可自动进行retry。除非retry次数超过阀值(可配置),消息才会丢失。此时需要生产者客户端手动处理该情况。那么producer是如何检测到数据丢失的呢?是通过ack机制,类似于http的三次握手的方式。
官方对于参数acks的解释
- acks=0,producer不等待broker的响应,效率最高,但是消息很可能会丢。
- acks=1,leader broker收到消息后,不等待其他follower的响应,即返回ack。也可以理解为ack数为1。此时,如果follower还没有收到leader同步的消息leader就挂了,那么消息会丢失。按照上图中的例子,如果leader收到消息,成功写入PageCache后,会返回ack,此时producer认为消息发送成功。但此时,按照上图,数据还没有被同步到follower。如果此时leader断电,数据会丢失。
- acks=-1,leader broker收到消息后,挂起,等待所有ISR列表中的follower返回结果后,再返回ack。-1等效与all。这种配置下,只有leader写入数据到pagecache是不会返回ack的,还需要所有的ISR返回“成功”才会触发ack。如果此时断电,producer可以知道消息没有被发送成功,将会重新发送。如果在follower收到数据以后,成功返回ack,leader断电,数据将存在于原来的follower中。在重新选举以后,新的leader会持有该部分数据。数据从leader同步到follower,需要2步:
- 数据从pageCache被刷盘到disk。因为只有disk中的数据才能被同步到replica。
- 数据同步到replica,并且replica成功将数据写入PageCache。在producer得到ack后,哪怕是所有机器都停电,数据也至少会存在于leader的磁盘内。
上面第三点提到了ISR的列表的follower,需要配合另一个参数才能更好的保证ack的有效性。ISR是Broker维护的一个“可靠的follower列表”,in-sync Replica列表,broker的配置包含一个参数:min.insync.replicas。该参数表示ISR中最少的副本数。如果不设置该值,ISR中的follower列表可能为空。此时相当于acks=1。
3.4 高可用模型及幂等
3.4.1 committed log
Kafka 使用完全不同的方式解决消息丢失问题。Kafka的 topic 被分割成了一组完全有序的 partition,其中每一个 partition 在任意给定的时间内只能被每个订阅了这个 topic 的 consumer 组中的一个 consumer 消费。这意味着 partition 中 每一个 consumer 的位置仅仅是一个数字,即下一条要消费的消息的offset。这使得被消费的消息的状态信息相当少,每个 partition 只需要一个数字。这个状态信息还可以作为周期性的 checkpoint。这以非常低的代价实现了和消息确认机制等同的效果。
发布消息时,我们会有一个消息的概念被“committed”到 log 中。 一旦消息被提交,只要有一个 broker 备份了该消息写入的 partition,并且保持“alive”状态,该消息就不会丢失。
3.4.2 ISR
如3.3.2所示
3.4.3 一旦分区上的所有备份节点都挂了,怎么去保证数据不会丢失
一旦分区上的所有备份节点都挂了,怎么去保证数据不会丢失,这里有两种实现的方法
1.等待一个 ISR 的副本重新恢复正常服务,并选择这个副本作为领 leader (它有极大可能拥有全部数据)。
2.选择第一个重新恢复正常服务的副本(不一定是 ISR 中的)作为leader。
kafka 默认选择第二种策略,当所有的 ISR 副本都挂掉时,会选择一个可能不同步的备份作为 leader ,可以配置属性 unclean.leader.election.enable 禁用此策略,那么就会使用第 一种策略即停机时间优于不同步。
这种困境不只有 Kafka 遇到,它存在于任何 quorum-based 规则中。例如,在大多数投票算法当中,如果大多数服务器永久性的挂了,那么您要么选择丢失100%的数据,要么违背数据的一致性选择一个存活的服务器作为数据可信的来源。
默认情况下,当 acks = all 时,只要 ISR 副本同步完成,就会返回消息已经写入。
3.5 如何实现exactly-once
在分布式系统中一般有三种处理语义:
- at-least-once:
至少一次,有可能会有多次。如果producer收到来自ack的确认,则表示该消息已经写入到Kafka了,此时刚好是一次,也就是我们后面的exactly-once。但是如果producer超时或收到错误,并且request.required.acks配置的不是-1,则会重试发送消息,客户端会认为该消息未写入Kafka。如果broker在发送Ack之前失败,但在消息成功写入Kafka之后,这一次重试将会导致我们的消息会被写入两次,所以消息就不止一次地传递给最终consumer,如果consumer处理逻辑没有保证幂等的话就会得到不正确的结果。
在这种语义中会出现乱序,也就是当第一次ack失败准备重试的时候,但是第二消息已经发送过去了,这个时候会出现单分区中乱序的现象,我们需要设置Prouducer的参数max.in.flight.requests.per.connection,flight.requests是Producer端用来保存发送请求且没有响应的队列,保证Producer端未响应的请求个数为1。 - at-most-once:
如果在ack超时或返回错误时producer不重试,也就是我们讲request.required.acks=-1,则该消息可能最终没有写入kafka,所以consumer不会接收消息。 - exactly-once:
刚好一次,即使producer重试发送消息,消息也会保证最多一次地传递给consumer。该语义是最理想的,也是最难实现的。在0.10之前并不能保证exactly-once,需要使用consumer自带的幂等性保证。0.11.0使用事务保证了
Kafka 分别通过 幂等性(Idempotence)和事务(Transaction)这两种机制实现了 精确一次(exactly once)语义。
3.5.1 幂等
幂等这个词原是数学领域中的概念,指的是某些操作或函数能够被执行多次,但每次得到的结果都是不变的。
在 Kafka 中,Producer 默认不是幂等性的,但我们可以创建幂等性 Producer。它其实是 0.11.0.0 版本引入的新功能。指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture),或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,向 Broker 申请一个 ProducerID,作为每个Producer会话的唯一标识,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
Broker端也会维护一个维度为<PID,Topic,Partition>序号,并且每次Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号(即最后一次Commit的消息的序号)大一,则Broker会接受它,否则将其丢弃:
- 如果消息序号比Broker维护的序号大一以上,说明中间有数据尚未写入,也即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
- 如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
上述设计解决了0.11.0.0之前版本中的两个问题:
- Broker保存消息后,发送ACK前宕机,Producer认为消息未发送成功并重试,造成数据重复;
- 前一条消息发送失败,后一条消息发送成功,前一条消息重试后成功,造成数据乱序。
实现比较简单,同样的限制也比较大:
- 首先,它只能保证单分区上的幂等性。即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。因为 SequenceNumber 是以 Topic + Partition 为单位单调递增的,如果一条消息被发送到了多个分区必然会分配到不同的 SequenceNumber ,导致重复问题。
- 其次,它只能实现单会话上的幂等性。不能实现跨会话的幂等性。当你重启 Producer 进程之后,这种幂等性保证就丧失了。重启 Producer 后会分配一个新的 ProducerID,相当于之前保存的 SequenceNumber 就丢失了。
3.5.2 事务
Kafka 自 0.11 版本开始也提供了对事务的支持,目前主要是在 read committed 隔离级别上做事情。它能保证多条消息原子性地写入到目标分区,同时也能保证 Consumer 只能看到事务成功提交的消息。
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
设置事务型 Producer 的方法也很简单,满足两个要求即可:
-
和幂等性 Producer 一样,开启 enable.idempotence = true。
-
设置 Producer 端参数 transactional. id。最好为其设置一个有意义的名字。
为了保证新的 Producer 启动后,旧的具有相同 Transaction ID 的 Producer 失效,每次 Producer 通过 Transaction ID 拿到 PID 的同时,还会获取一个单调递增的 epoch。由于旧的 Producer 的 epoch 比新 Producer 的 epoch 小,Kafka 可以很容易识别出该 Producer 是老的 Producer 并拒绝其请求。
此外,你还需要在 Producer 代码中做一些调整,如这段代码所示:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
和普通 Producer 代码相比,事务型 Producer 的显著特点是调用了一些事务 API,如 initTransaction、beginTransaction、commitTransaction 和 abortTransaction,它们分别对应事务的初始化、事务开始、事务提交以及事务终止。
这段代码能够保证 Record1 和 Record2 被当作一个事务统一提交到 Kafka,要么它们全部提交成功,要么全部写入失败。
实际上即使写入失败,Kafka 也会把它们写入到底层的日志中,也就是说 Consumer 还是会看到这些消息。因此在 Consumer 端,读取事务型 Producer 发送的消息也是需要一些变更的。修改起来也很简单,设置 isolation.level 参数的值即可。当前这个参数有两个取值:
- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。
很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。 - read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。
当然了,它也能看到非事务型 Producer 写入的所有消息。
幂等性 Producer 和事务型 Producer 都是 Kafka 社区力图为 Kafka 实现精确一次处理语义所提供的工具,只是它们的作用范围是不同的。
- 幂等性 Producer 只能保证单分区、单会话上的消息幂等性;
- 而事务能够保证跨分区、跨会话间的幂等性。
比起幂等性 Producer,事务型 Producer 的性能要更差
参考:
Kafka:这次分享我只想把原理讲清楚
kafka中文网
关于OS Page Cache的简单介绍
《图解系统》笔记(一)
zookeeper和Kafka的关系
Kafka源码深度解析-序列4 -Producer -network层核心原理
Reactor模式介绍
Reactor模型
图解Kafka服务端网络模型]
Kafka 核心技术与实战
Kafka 核心源码解读















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









