







论文标题
Mixture of Experts for Audio-Visual Learning 视听学习的专家混合模型
论文链接
Mixture of Experts for Audio-Visual Learning论文下载
论文作者
Ying Cheng, Yang Li, Junjie He, Rui Feng
内容简介
本文提出了一种新的视听学习方法——视听专家混合模型(AVMoE),旨在通过灵活地将适配器注入预训练模型来实现参数高效的迁移学习。AVMoE引入了单模态和跨模态适配器作为多个专家,分别专注于模内和模间信息,并采用轻量级路由器根据每个任务的具体需求动态分配每个专家的权重。通过在多个视听任务(如音频-视觉事件定位、音频-视觉视频解析、音频-视觉分割和音频-视觉问答)上进行广泛实验,结果表明AVMoE在性能上优于现有方法,并且在模态信息缺失的情况下也能有效应对挑战场景。
分点关键点
-
AVMoE框架
- AVMoE通过引入单模态适配器和跨模态适配器,分别处理模内和模间信息。该框架利用轻量级路由器动态分配适配器的权重,以适应不同任务的需求,从而提高模型的灵活性和效率。
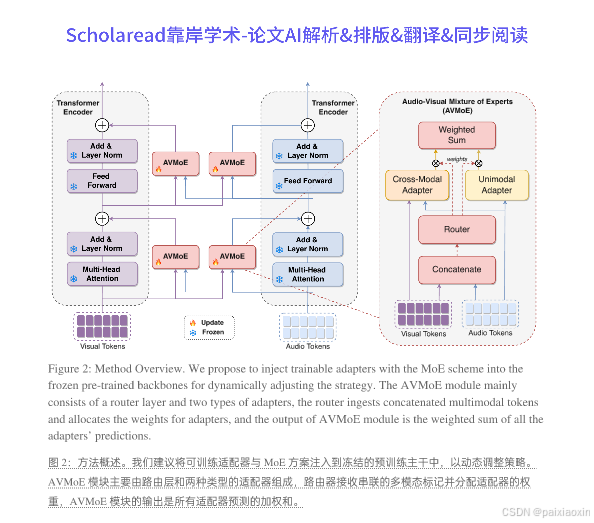
- AVMoE通过引入单模态适配器和跨模态适配器,分别处理模内和模间信息。该框架利用轻量级路由器动态分配适配器的权重,以适应不同任务的需求,从而提高模型的灵活性和效率。
-
参数高效的迁移学习
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









