






论文标题
GAMC: An Unsupervised Method for Fake News Detection Using Graph Autoencoder with Masking GAMC:一种基于图自编码器和掩码的无监督假新闻检测方法
论文链接
GAMC: An Unsupervised Method for Fake News Detection Using Graph Autoencoder with Masking论文下载
论文作者
Shu Yin, Peican Zhu, Lianwei Wu, Chao Gao, Zhen Wang
内容简介
随着社交媒体的兴起,假新闻的传播已成为一个重大问题,可能误导公众认知并影响社会稳定。尽管深度学习方法(如CNN、RNN和基于Transformer的模型如BERT)在假新闻检测中取得了一定进展,但它们主要关注内容而忽视了新闻传播过程中的社会背景。为了解决这一问题,本文提出了一种名为GAMC的无监督假新闻检测方法,利用图自编码器与掩码和对比学习相结合。GAMC通过对原始新闻传播图进行数据增强,生成增强图并进行编码和重建,最终通过复合损失函数来优化模型。实验结果表明,GAMC在真实数据集上优于现有的无监督方法,展示了其在假新闻检测中的有效性。

分点关键点
- GAMC方法概述
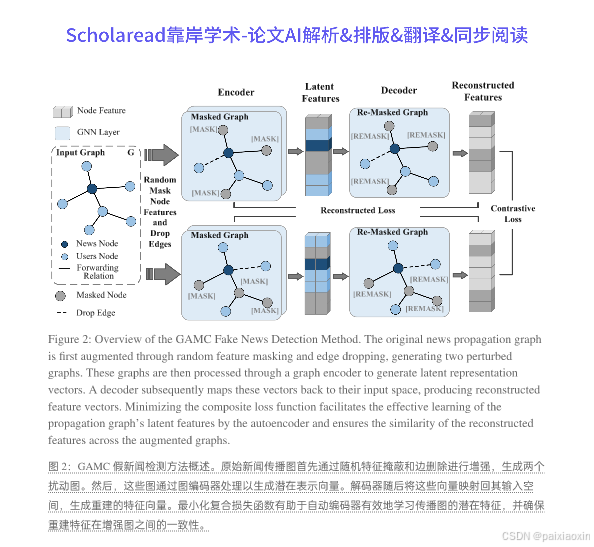
- GAMC是一种无监督的假新闻检测技术,结合了图自编码器、掩码和对比学习。该方法通过利用新闻传播的上下文和内容作为自监督信号,减少了对标记数据集的依赖。
-
数据增强策略
- GAMC首先对原始新闻传播图进行数据增强,包括随机节点特征掩蔽和边删除。这些增强图用于后续的特征重建和对比任务,确保模型在复杂传播模式下的有效性。
-
图编码与解码
- 使用图同构网络(GIN)对增强图进行编码,生成潜在表示向量。解码器将这些潜在表示映射回输入空间,生成重建特征矩阵,以便进行假新闻分类。
-
复合损失函数
- GAMC设计了一个复合损失函数,包括重构损失和对比损失。重构损失确保重建特征矩阵与原始特征矩阵的相似性,而对比损失则最小化来自同一传播图的两个重建图之间的差异。

- 实验验证
- 在真实数据集上的实验表明,GAMC优于现有的无监督假新闻检测方法,验证了其有效性和鲁棒性。
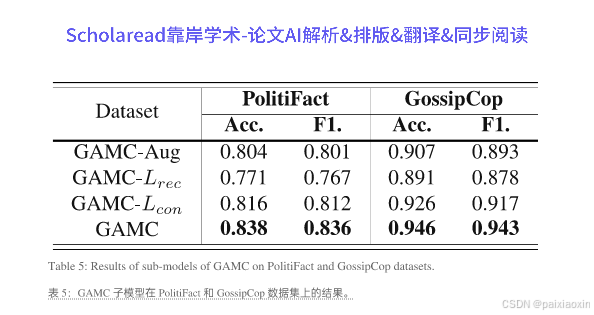
- 在真实数据集上的实验表明,GAMC优于现有的无监督假新闻检测方法,验证了其有效性和鲁棒性。
论文代码
代码链接:https://github.com/cgaocomp/GAMC
中文关键词
- 假新闻检测
- 无监督学习
- 图自编码器
- 数据增强
- 复合损失函数
- 社会背景
AAAI论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









