







 超级会员免费看
超级会员免费看
基于自适应特征匹配优化框架的假新闻检测 ICLR2024
摘要:本文提出一种基于为假新闻识别量身定制的显著属性的优化方法,跨越单模态和多模态数据源。通过利用从文本到视觉各种模态中固有的能力,全面理解假新闻的多面性。首先,该方法引入了一系列前所未有的特征,包括单词级、句子级和上下文特征。这种注入赋予它一种强大的能力,可以熟练地适应广泛的文本内容。随后,集成了一种基于模拟退火原理的以特征为中心的优化技术。这种方法使我们能够确定特征的最优融合,从而减轻由于文本和视觉组件共存而产生的潜在冲突和干扰。
1 介绍
本文的主要目标是提出用于假新闻检测的智能机制,这是维护信息的准确性和可靠性的关键一步。
事实上,确保多模态假新闻检测的精度,需要复杂的技术,例如,Sporfake模型擅长管理固有的噪声、模糊性和在处理多种数据类型时经常出现的不一致,从不同模态中提取的特征的一致性对齐,同时考虑了潜在的差异,带来了一个巨大的计算障碍。
针对这个挑战,本文提出了一种自适应特征匹配优化框架(Adaptive Feature Matching Optimization framework, AFMO),用于同时利用单模态和多模态资源进行假新闻检测。AFMO利用多种模态的力量,通过使用文本和视觉数据来构建潜在假新闻的整体描述。具体来说,利用不同的神经网络从不同的模态信息中提取特征表示。然后,利用离群点检测算法剔除特征异常的训练样本,从而提高训练模型的准确性和可靠性。此外,采用模拟退火算法明智地融合从不同模态提取的特征,从而优化模型的整体性能。
事实上,传统的假新闻检测方法可能会遇到视觉上显著的图像特征,这些特征模糊了关键的文本信息,导致对更广泛的上下文的理解不完整。为了解决这种模糊性,本文采用了一种以特征为中心的模拟退火算法,旨在通过策略性的特征选择来改善文本和视觉数据之间的潜在干扰。因此,AFMO的关键在于提高所提取特征的质量和判别能力,同时缓解跨模态干扰的影响。
2 相关工作
2.1 多模态假新闻检测
假新闻检测最早在文本领域单模态进行,神经网络的出现,提高了提取文本特征的效果,深度学习方法的不断丰富,文本领域假新闻检测的框架日渐成熟,精度也越来越高,但随着社交媒体领域的迅猛发展,新闻文章往往伴随着图像、视频等跨域内容一起发布,这进一步增加了假新闻检测的难度,因此,许多研究人员将重点转移到虚假新闻检测中包含图像,从而提出了多模态检测框架。
主要模型有:att-RNN、EANN、MVAE、MCAN等,(可以关注订阅假新闻检测专栏,都有论文解读)
2.2 模拟退火算法
模拟退火算法是一种通用的随机搜索技术,广泛应用于各种组合优化问题。它的适应性使其在各个领域都是宝贵的资产,包括VLSI设计、图像识别和神经网络计算领域的研究。该算法在聚类(Lee & Perkins, 2021)等任务中得到了显著应用,聚类是网络中最具影响力的节点(Jiang等人,2011)。此外,研究人员将模拟退火与其他方法相结合,以获得相对于单一方法的更高性能,特别是在特定领域。例如,遗传算法的模拟退火收敛性已被用于解决多类多维背包优化问题(孟等人,2019)。此外,模拟退火与海盐群算法(SSA)和遗传算法的融合被用于校准SSA内部的探索和开发之间的平衡(Kassaymeh等人,2022)。在退火算法在组合优化范围内被证明的有效性的鼓舞下,明智地将该算法集成到所提出的AFMO框架中,从而克服了协同吸收文本和视觉特征的挑战。
3 方法
3.1 模型概述
考虑一个包含N个样本的新闻数据集D,每个样本由新闻文本、新闻图像和相应的真假标签组成。所提出的AFMO主要利用新闻的文本和图像信息来推断其标签。本文采用的主要公式见表1。
表1:数学符号的描述

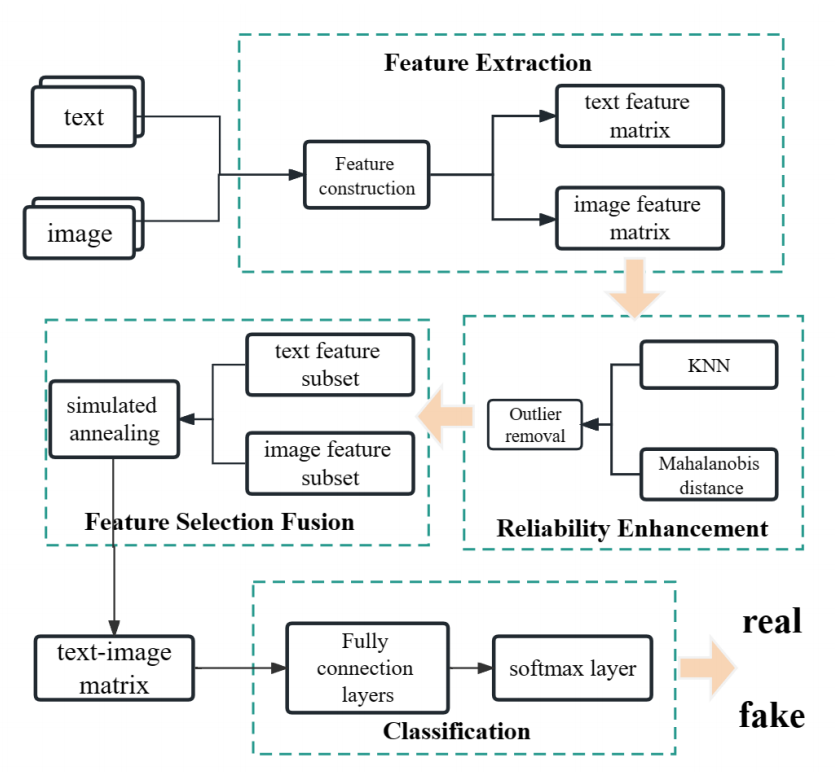
如图3所示
- 利用BERT模块和VGG模块对新闻文章进行特征提取,分别负责提取文本和图像信息。这些模块生成各自文本和图像模态的全面表示。
- 接下来,使用离群点去除模块来识别和消除具有异常属性的实例,从而产生一个新的训练集,并进行后续处理。
- 最后,利用模拟退火算法明智地选择和融合来自文本和图像模态的不同方面的相关信息。合并后的特征随后被导入分类器以产生最终的预测。
鉴于原始数据集中可能存在表现出非典型特征的数据样本,将训练集中的全部文本和图像特征作为输入。利用马氏距离或k近邻(KNN)等方法,识别和删除这些异常实例,得到一个称为reduce的精化数据集。随后,利用这个精心策划的数据集执行训练方案。模拟退火算法在协调文本特征mt和图像特征mp的融合中起着关键作用,从而协调相关属性的选择。最后,合并后的特征遍历一组全连接层,最终得到最终的预测结果。
3.2 特征提取
3.2.1 文本特征提取
BERT是一种基于注意力机制原则的变革性模型,它通过掩码语言模型(MLM)任务进行预训练。在我们的研究中,我们将txti指定为BERT的输入,因为BERT的终端层封装了全面的文本掩码。经验表明,与其他层产生的结果相比,最后四个隐藏层的结果在不同的NLP任务中提供了最佳的性能。因此,将最后四个隐藏层的输出连接起来,从而培养基本的文本特征,从而产生四个输出的累积计数。这些输出按顺序连接起来形成完整的基本文本特征,记为
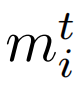
。如下式所示:
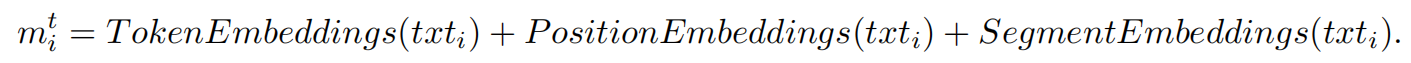
这里,
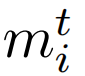
表示第i个文本样本的嵌入向量,TokenEmbeddings对应于token的初始嵌入向量,PositionEmbeddings表示token的位置嵌入向量,SegmentEmbeddings表示token的段嵌入向量。
3.2.2 图像特征提取
VGG(Simonyan & Zisserman(2015))因其深刻的网络架构而备受赞誉,通过多个VGG块的排列而达到深度,每个VGG块都包含卷积层和池化层。这种设计赋予了鲁棒的泛化能力,使其在各种图像数据集上有效。因此,VGG通常被用于图像特征的提取。在我们的研究中,我们使用在ImageNet数据集上预训练的VGG-19作为指定的图像信息特征提取器。当呈现一个维度为W × H的输入图像时,一系列卷积和池化层协作生成一个维度为C的特征向量,封装了显著的图像特征。在这种情况下,C对应于最终卷积层内的通道计数。在我们的方法中,imgi承担了VGG-19输入的角色。终端层的输出与VGG网络的结构蓝图一致,封装了所有图像特征的光谱。因此,我们采用VGG-19终端层的输出作为我们的图像特征,通过以下公式实现:
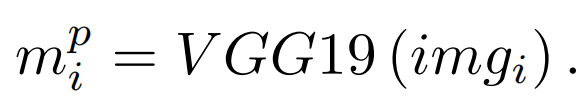
3.2.3 训练增强
将每个样本的文本特征
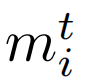
和图像特征
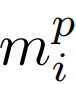
连接起来形成mi,其中
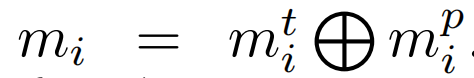
。因此,样本的所有特征表示为M = {mi |∀i = 1,…N}
马氏距离(Mahalanobis distance)是一种传统的度量方法,用于测量特定点与分布之间的距离。在本方法中,应用马氏距离计算来识别并随后消除异常数据实例。事实上,我们开始推导特征集m的平均向量μ和协方差矩阵Σ。此后,每个样本和数据集作为一个聚合实体之间的距离被精心计算。该阈值称为Distmean,通过计算所有样本之间的平均距离,然后将其乘以标准差σ,并通过加权因子α进行调整。权重系数α的默认值是1。样本点与数据集之间的距离超过该阈值的情况被视为异常,随后被排除在考虑范围之外。马氏距离Dist(mi)的计算方法如下:
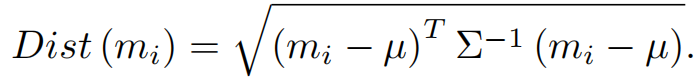
异常阈值Distmax由α和σ的乘积与Distmean相加得到:
![]()
KNN (k-nearest neighbors)是一种流行的无监督聚类算法,它无缝地将其应用于离群点检测。其基本原则是测量当前样本和整个数据集之间的距离。与量化点和分布之间的距离不同,KNN计算每个个体样本与其他样本之间的距离,使用的是欧几里得距离公式,如下所示:
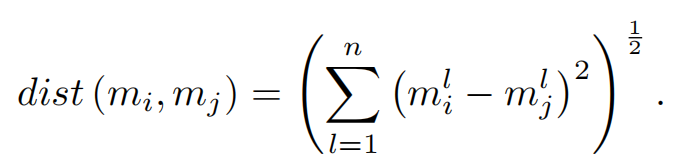
精心选择以最近距离为特征的k个样本,并精心计算当前样本与这k个样本之间距离的算术平均值。然后,这些平均距离被累积起来,并按照从最大到最小的值降序排列。通过划定阈值来界定离群点的比例,进而确定与当前样本相关的平均距离是否超过这个预定义的阈值。如果平均距离超过设置的阈值,当前样本将被分类为异常值。在最终阶段,这些离群样本被系统地切除,最终形成一个称为reduce的新数据集。经过提炼的数据集随后形成了后续训练和测试阶段的基础,使用原始数据集中相同的测试集。
3.4 面向特征选择的元启发式算法
在原始数据集中,每个文本特征
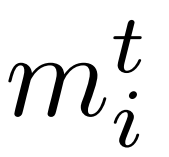
都由一组值概括

,其中,ntxt表示文本特征的范围。同时,每个图像特征
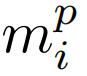
都由一组值表示
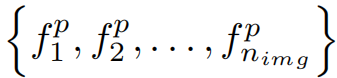
,其中nimg反映图像特征的维数。传统的特征选择策略包含了两种模态特征的聚合,这种做法可能无意中导致信息的丢失,特别是当特征向量包含不同的内涵时。然而,这种方法成倍地增加了计算复杂度,并可能无意中纳入所有维度的不相关或虚假信息,从而可能影响结果。
为解决这一困境,本文主张采用模拟退火算法进行特征选择,准备筛出有效的维度,同时丢弃那些无关的维度。模拟退火算法表现出超越局部最优的能力,从而容纳在探索过程中的次优解,避免陷入局部最优。通过这种方法,希望提高所选特征的口径,减少文本和视觉见解之间的可能干扰,并增强分类任务的整体功效。模拟退火算法用于特征匹配的主要步骤可以简洁地封装如下:
- 加热:最初,预先确定初始温度t0、最小温度tmin和当前温度tcur(最初与t0对齐)。对于
的每个组合,构想一个二元序列
,其长度对应于所包含特征的集合维度。在这个序列中,如果将文本特征的第i维判定为与最终的谣言检测相关,xi的值为1,保留其固有值。相反,如果第i维缺乏显著性,则xi的值为0,强制将其值设置为0。初始化一个完全任意的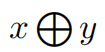
配置,作为基础状态。
- 等温:如果当前温度tcur小于最小温度tmin,迭代过程结束。相反,如果这个条件仍然不满足,新的
配置将在其前身的基础上产生。这种变形是通过从初始
排列中选择一定数量的维度,然后反转它们的主要0-1值来实现的。随机性的程度和选定维度的计数随着温度的升高而上升。这种不断升级的关系可以用下面的公式来表示:
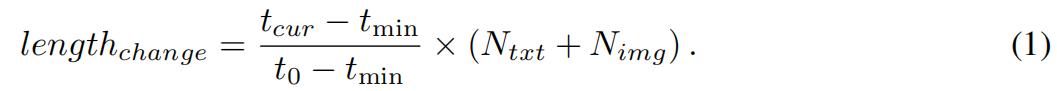
利用更新后的
![]()
构型对初始特征mi进行变换,得到重构后的特征
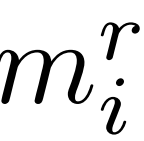
。然后,将这些重构后的特征引入到分类器检测器中,得到分类结果outi。准确率是通过将outi与实际标签标签并置来精心计算的。这个准确率作为控制模拟退火算法的关键目标函数出现:

其中,

- 冷却:如果当前迭代的准确率高于之前的最佳准确性,修正了
配置直接接受。相比之下,如果精度下降,接受新解决方案的决心就会对目前的温度t电流和在现有和前最优精度之间的准确性上的差异造成影响,并以其为代表。升高的温度导致了采用的提高概率,有效地促进了对局部最优a的避免。将主流解决方案结合起来的概率由随后的方程治理:
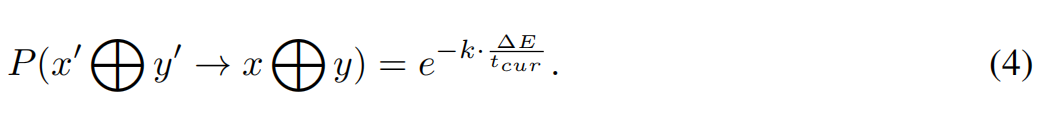
如果当前解被接受,则其准确率承担最优准确率的覆盖。随后,将当前温度乘以冷却因子k,并将更新后的温度返回等温过程阶段。如果当前的溶液没有被吸收,则进程迅速恢复到等温过程阶段。将以上三个步骤重复多次,完成多轮模拟退火算法,以达到最佳效果。
4 实验
4.1 数据集
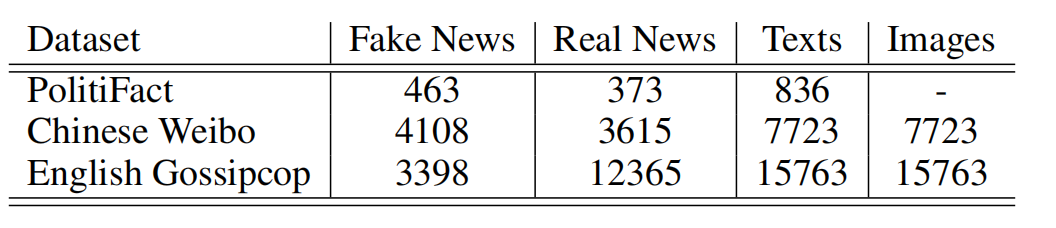
在单模态测试中,我们选择使用PolitiFact数据集来评估所提出的自适应特征匹配优化(AFMO)框架的有效性(Shu等人,2020)。PolitiFact数据集从FakeNewsNet获得,包括从事实检查网站PolitiFact提取的新闻文章,由领域专家精心标记其真实性。在多模态测试中,我们选择了两个公认的、公开的基准数据集——中文微博数据集和英文Gossipcop数据集,对假新闻检测领域进行了严格的评估和实验。为了提供数据集特征的简明概述,我们在表2中总结了数据集统计信息。
后续实验过程,略
5 总结
本文提出一种新的方法,用于训练模型来检测假新闻,并战略性地结合各种模态来识别误导性信息。该方法包括几个关键步骤。首先,分别使用BERT和VGG19提取新闻文本和图像的基本特征;采用基于KNN和马氏距离的鲁棒离群点检测技术,有效剔除具有异常特征的训练样本。该框架的核心在于对模拟退火算法的利用,该算法在选择有效结合文本和图像模态的信息量最大的特征方面起着至关重要的作用。这里的首要目标是尽量减少文本和视觉信息之间的潜在干扰,从而提高所选特征的整体质量和可区分性。然后,这些精心选择的特征被无缝地集成到分类过程中,以识别虚假新闻。该方法通过严格的实验得到证实,将其性能与现有方法进行了比较。实证结果强烈强调了所提出方法在假新闻检测领域比其他方法的有效性和优越性。展望未来,我们的研究轨迹包括用户相关属性的集成,包括追随者和朋友数量等指标。通过合并这一额外的以用户为中心的信息层,可以进一步提高假新闻检测领域的准确性和整体性能。这种全面的方法,包括不同的模态和用户属性,有望在解决识别和减轻假新闻的多方面挑战方面产生更令人印象深刻的结果。


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











