







from:
http://www.javacodegeeks.com/2010/07/java-best-practices-high-performance.html
Continuing our series of articles concerning proposed practices while working with the Java programming language, we are going to discuss and demonstrate how to utilize Object Serialization for high performance applications.
All discussed topics are based on use cases derived from the development of mission critical, ultra high performance production systems for the telecommunication industry.
Prior reading each section of this article it is highly recommended that you consult the relevant Java API documentation for detailed information and code samples.
All tests are performed against a Sony Vaio with the following characteristics :
- System : openSUSE 11.1 (x86_64)
- Processor (CPU) : Intel(R) Core(TM)2 Duo CPU T6670 @ 2.20GHz
- Processor Speed : 1,200.00 MHz
- Total memory (RAM) : 2.8 GB
- Java : OpenJDK 1.6.0_0 64-Bit
- Concurrent worker Threads : 200
- Test repeats per worker Thread : 1000
- Overall test runs : 100
High performance Serialization
Serialization is the process of converting an object into a stream of bytes. That stream can then be sent through a socket, stored to a file and/or database or simply manipulated as is. With this article we do not intend to present an in depth description of the serialization mechanism, there are numerous articles out there that provide this kind of information. What will be discussed here is our proposition for utilizing serialization in order to achieve high performance results.
The three main performance problems with serialization are :
- Serialization is a recursive algorithm. Starting from a single object, all the objects that can be reached from that object by following instance variables, are also serialized. The default behavior can easily lead to unnecessary Serialization overheads
- Both serializing and deserializing require the serialization mechanism to discover information about the instance it is serializing. Using the default serialization mechanism, will use reflection to discover all the field values. Furthermore if you don't explicitelly set a „serialVersionUID“ class attribute, the serialization mechanism has to compute it. This involves going through all the fields and methods to generate a hash. The aforementioned procedure can be quite slow
- Using the default serialization mechanism, all the serializing class description information is included in the stream, such as :
- The description of all the serializable superclasses
- The description of the class itself
- The instance data associated with the specific instance of the class
To solve the aforementioned performance problems you can use Externalization instead. The major difference between these two methods is that Serialization writes out class descriptions of all the serializable superclasses along with the information associated with the instance when viewed as an instance of each individual superclass. Externalization, on the other hand, writes out the identity of the class (the name of the class and the appropriate „serialVersionUID“ class attribute) along with the superclass structure and all the information about the class hierarchy. In other words, it stores all the metadata, but writes out only the local instance information. In short, Externalization eliminates almost all the reflective calls used by the serialization mechanism and gives you complete control over the marshalling and demarshalling algorithms, resulting in dramatic performance improvements.
Of course, Externalization efficiency comes at a price. The default serialization mechanism adapts to application changes due to the fact that metadata is automatically extracted from the class definitions. Externalization on the other hand isn't very flexible and requires you to rewrite your marshalling and demarshalling code whenever you change your class definitions.
What follows is a short demonstration on how to utilize Externalization for high performance applications. We will start by providing the “Employee” object to perform serialization and deserialization operations. Two flavors of the “Employee” object will be used. One suitable for standard serialization operations and another that is modified so as to able to be externalized.
Below is the first flavor of the “Employee” object :
Things to notice here :
- We assume that the following fields are mandatory :
- “firstName”
- “lastName”
- “socialSecurityNumber”
- “department”
- “position”
- “hireDate”
- “salary”
Following is the second flavor of the “Employee” object :
Things to notice here :
- We implement the “writeExternal” method for marshalling the “Employee” object. All mandatory fields are written to the stream
- For the “hireDate” field we write only the number of milliseconds represented by this Date object. Assuming that the demarshaller will be using the same timezone as the marshaller the milliseconds value is all the information we need to properly deserialize the “hireDate” field. Keep in mind that we could serialize the entire “hireDate” object by using the “objectOutput.writeObject(hireDate)” operation. In that case the default serialization mechanism would kick in resulting in speed degradation and size increment for the resulting stream
- All the non mandatory fields (“supervisor” and “phoneNumbers”) are written to the stream only when they have actual (not null) values. To implement this functionality we use the “attributeFlags” and “attributes” byte arrays. Each position of the “attributeFlags” array represents a non mandatory field and holds a “marker” indicating whether the specific field has a value. We check each non mandatory field and populate the “attributeFlags” byte array with the corresponding markers. The “attributes” byte array indicates the actual non mandatory fields that must be written to the stream by means of “position”. For example if both “supervisor” and “phoneNumbers” non mandatory fields have actual values then “attributeFlags” byte array should be [1,1] and “attributes” byte array should be [0,1]. In case only “phoneNumbers” non mandatory field has a non null value “attributeFlags” byte array should be [0,1] and “attributes” byte array should be [1]. By using the aforementioned algorithm we can achieve minimal size footprint for the resulting stream. To properly deserialize the “Employee” object non mandatory parameters we must write to the steam only the following information :
- The overall number of non mandatory parameters that will be written (aka the “attributes” byte array size – for the demarshaller to parse)
- The “attributes” byte array (for the demarshaller to properly assign field values)
- The actual non mandatory parameter values
- For the “phoneNumbers” field we construct and write to the stream a String representation of its contents. Alternatively we could serialize the entire “phoneNumbers” object by using the “objectOutput.writeObject(phoneNumbers)” operation. In that case the default serialization mechanism would kick in resulting in speed degradation and size increment for the resulting stream
- We implement the “readExternal” method for demarshalling the “Employee” object. All mandatory fields are written to the stream. For the non mandatory fields the demarshaller assigns the appropriate field values according to the protocol described above
For the serialization and deserialization processes we used the following four functions. These functions come in two flavors. The first pair is suitable for serializing and deserializing Externalizable object instances, whereas the second pair is suitable for serializing and deserializing Serializable object instances.
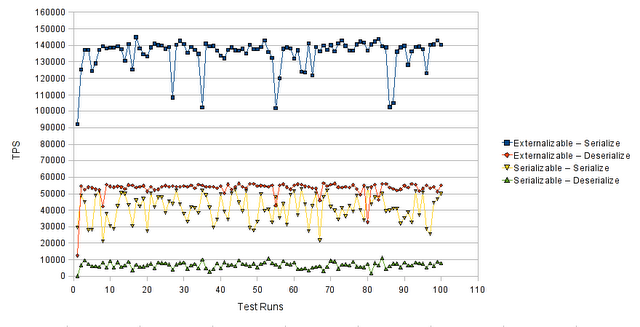
Below we present a performance comparison chart between the two aforementioned approaches















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









