










提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
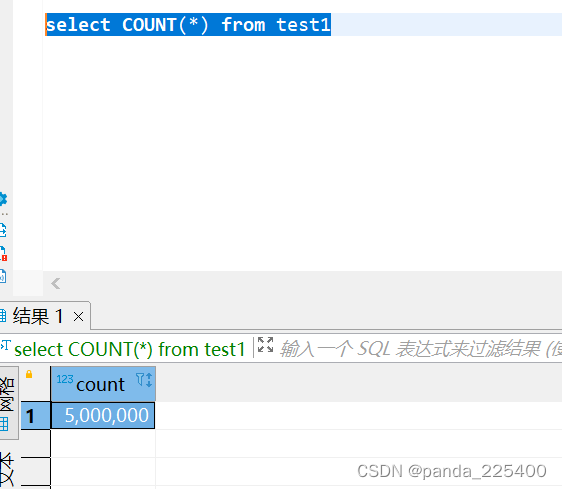
分布式关系型数据库集群搭建好了,试下是否如网上所述处理的数据具有高性能的优势,所以导入500万条测试数据进行简单的试下
提示:以下是本篇文章正文内容,下面案例可供参考
一、generate_series是什么?
GreenPlum是基于PostgreSQL - 使用generate_series函数生成大量测试数据。
generate_series(start, stop, step)函数
生成一个数值型序列,从 start 到 stop,步进为 step。
列: select * from generate_series(2,4); 结果为 2,3,4
二、使用步骤
1.建张测试表
代码如下(示例):
create table gpdb.test1
(uid varchar(10),gnd varchar(4),
name varchar(100),phone varchar(11)
)distributed by (uid);
2.插入简单的测试数据
代码如下(示例):
insert into test1
(uid,gnd,name,phone)
select
floor(random()*10000000000)
,(array['男','女','其他'])[floor(random()*3)::int+1]
,(array['小四','小花','小凡'])[floor(random()*3)::int+1]
,floor(random()*(10000000000-13899999999)+13899999999)
from generate_series(1,5000000);
3.查看数据分散情况
代码如下(示例):
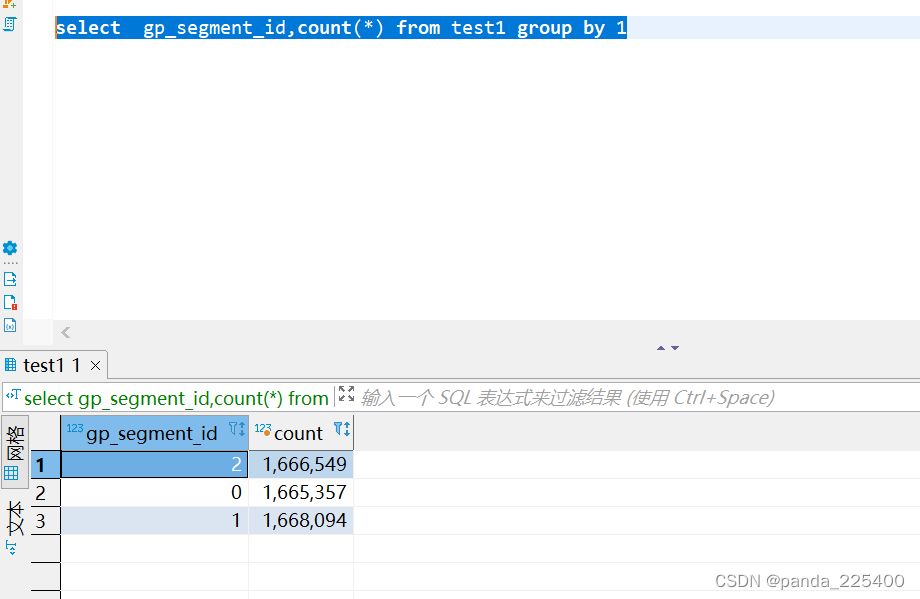
select gp_segment_id,count(*) from test1 group by 1
我搭建的环境部署了3个segment数据节点
500万数据分布在3个数据节点
4.通过SQL测试性能
代码如下(示例):
select phone ,count(*) from test1 group by 1
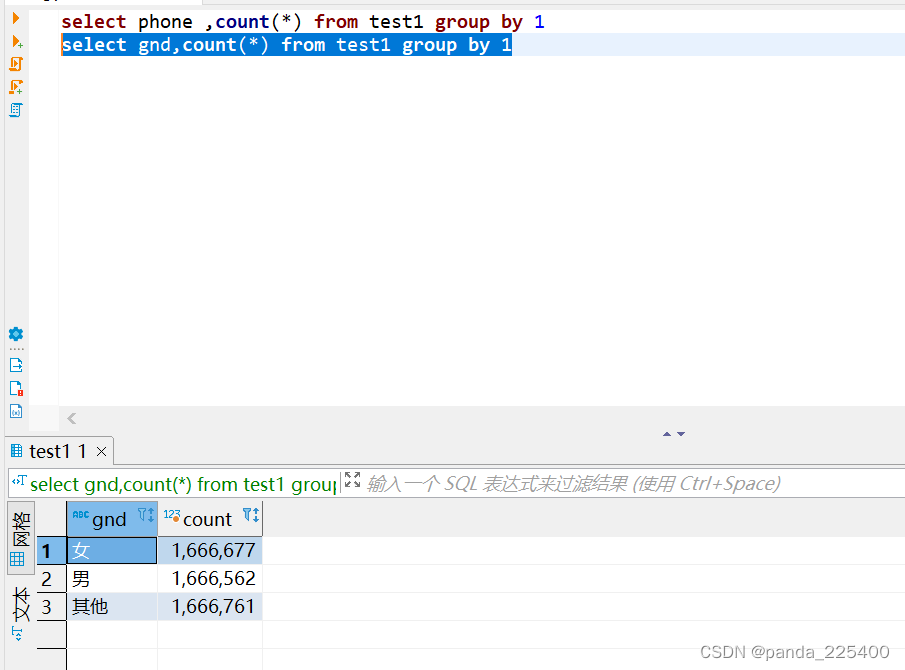
select gnd,count(*) from test1 group by 1
select phone,gnd ,count(*) from test1 group by phone,gnd
select gnd,count() from test1 group by 1
500万数据执行时间2秒不到
select phone ,count() from test1 group by 1
500万数据执行时间5秒不到
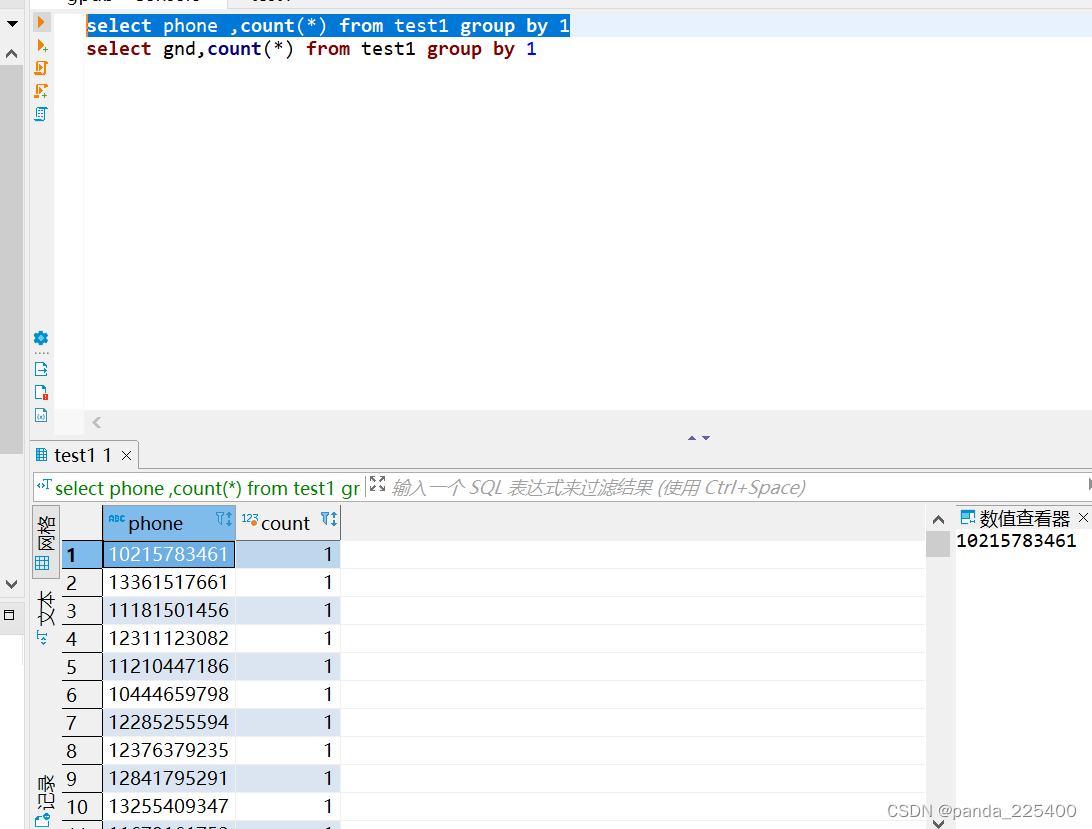
select phone,gnd ,count(*) from test1 group by phone,gnd
500万数据执行时间5.1秒左右
总结
在普通数据库里500万数据使用group by统计确实比较慢,但在GreenPlum下测试觉的确实性能高
















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











