






 numpy.histogram帮助计算数据分布,涉及参数如数据集a、bins配置、密度选项,返回值包括直方图值和边疆。示例展示了不同场景的使用。
numpy.histogram帮助计算数据分布,涉及参数如数据集a、bins配置、密度选项,返回值包括直方图值和边疆。示例展示了不同场景的使用。
说明
numpy.histogram(a, bins=10, range=None, density=None, weights=None)
计算一个数据集的直方图。
参数:
a:代表输入的数据集。直方图是在展平的数组上计算的。
bins:如果bins是一个整数,它定义了在给定范围(默认为10)内等宽的bins的数量。如果bins是一个序列,它定义了一个单调递增的bin边缘数组,包括最右边的边缘,允许非均匀的bin宽度。
density:如果为False,结果将包含每个bin中的样本数量。如果为True,结果是归一化的概率密度函数在bin处的值,使得在整个范围内的积分为1。请注意,除非选择宽度为1的bins,否则直方图值的总和不会等于1;它不是一个概率质量函数。
返回:
hist:数组,直方图的值。
bin_edges:数组。返回bin边缘。(length(hist)+1).
注意:最后一个bin(最右边的)是全闭,其它的bin是半开。例如,如果输入参数bins的值是
[1, 2, 3, 4]
那么第一个 bin 是 [1, 2)(包括 1,但不包括 2),第二个 bin 是 [2, 3)。然而,最后一个 bin 是 [3, 4],它包括了 4。
举例
下面示例返回每个bin的样本数量:
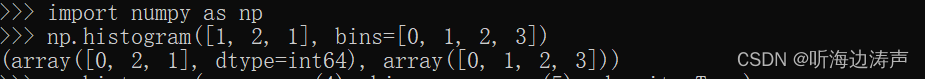
下面示例返回每个bin的概率密度:

下面示例输入数据是2维的,直方图是在展平的数组上计算的:

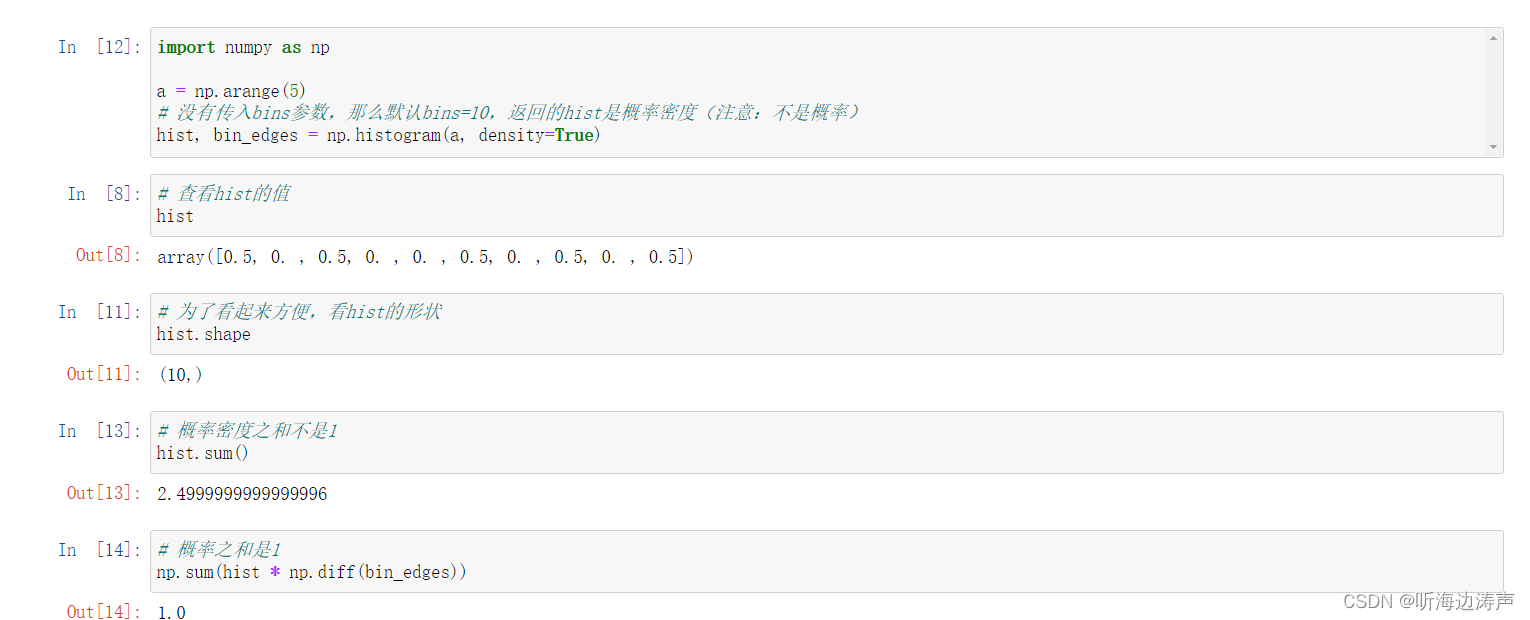
下面示例演示了概率密度、概率:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









