







1、配置windows7的hosts文件(C:\Windows\System32\drivers\etc),以下的三个节点是hadoop集群的一个主节点和两个从节点
192.168.232.131 master131
192.168.232.132 slave132
192.168.232.133 slave1332、在eclipse使用mahout构建hadoop工程,创建过程很简单,所以就省略了
3、修改pom.xml文件,将以下代码添加到pom.xml文件中,这里使用的hadoop版本是1.0.3
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.3</version>
</dependency>4、把hadoop-1.0.3源码里的WordCount.java文件拷贝到刚创建的hadoop工程里,以下是WordCount.java
package com.panguoyuan.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
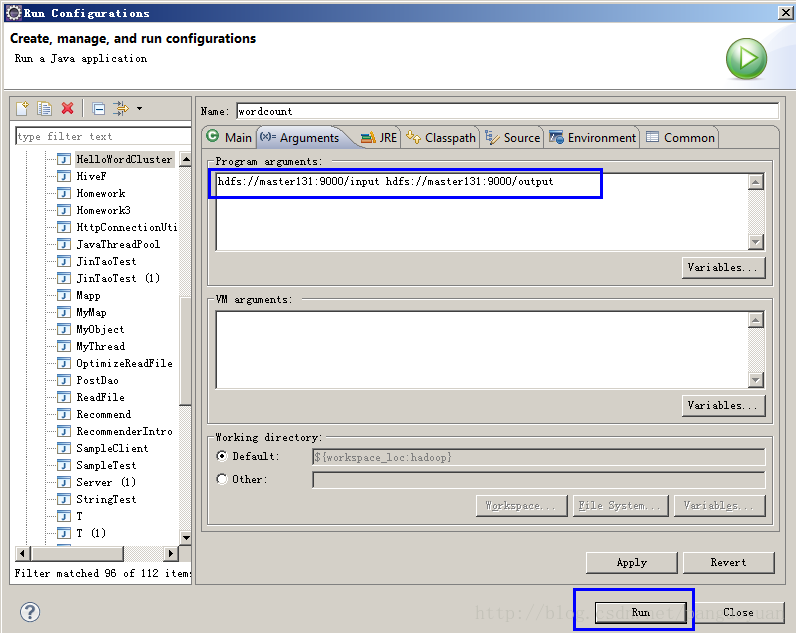
5、在eclipse工具菜单栏里的run->run configurations(在做这一步之前要确保hdfs://master131:9000/input目录下有要统计单词数的文件)
hadoop fs -mkdir /input
hadoop fs -put core-site.xml /input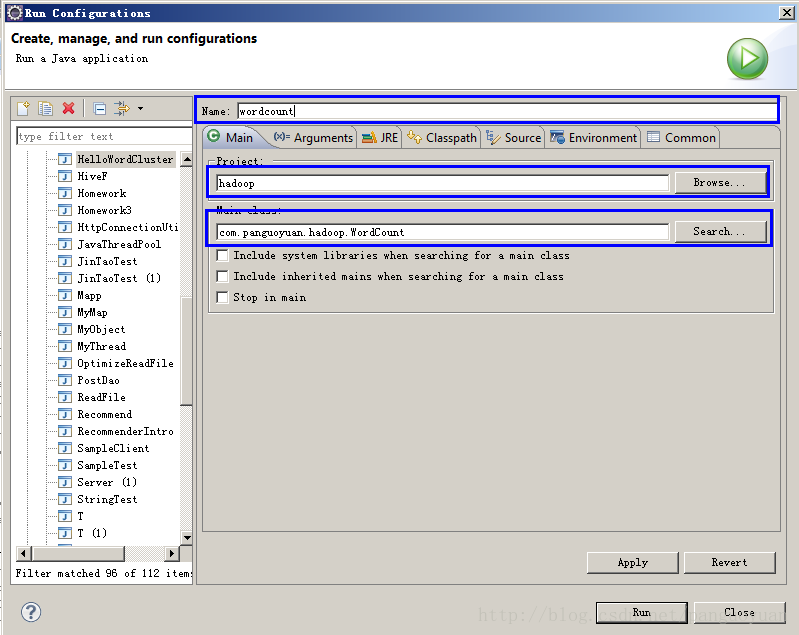
6、此时在eclipse的控制台下面会看到如下信息,这是因为在windows操作系统访问linux下的hadoop集群时报的访问权限问题
2014-5-1 9:33:55 org.apache.hadoop.util.NativeCodeLoader <clinit>
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2014-5-1 9:33:55 org.apache.hadoop.security.UserGroupInformation doAs
严重: PriviledgedActionException as:hadoop cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-hadoop\mapred\staging\hadoop-1444905016\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-hadoop\mapred\staging\hadoop-1444905016\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:500)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:530)
at com.panguoyuan.hadoop.WordCount.main(WordCount.java:67)
7、解决办法
(1)在hadoop-core-1.0.3.jar包找到org.apache.hadoop.fs.FileUtil.java,将以下的几行代码注释掉
private static void checkReturnValue(boolean rv, File p,
FsPermission permission
) throws IOException {
/** if (!rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
} */
}2、重新打成jar包,然后将之前maven自动下载下来的hadoop-core-1.0.3.jar换掉
3、此时重新运行WordCount.java就能正常运行了
2014-5-1 9:46:37 org.apache.hadoop.util.NativeCodeLoader <clinit>
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2014-5-1 9:46:37 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2014-5-1 9:46:37 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2014-5-1 9:46:37 org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>
警告: Snappy native library not loaded
2014-5-1 9:46:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2014-5-1 9:46:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-5-1 9:46:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: io.sort.mb = 100
2014-5-1 9:46:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: data buffer = 79691776/99614720
2014-5-1 9:46:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: record buffer = 262144/327680
2014-5-1 9:46:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2014-5-1 9:46:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2014-5-1 9:46:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2014-5-1 9:46:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 0% reduce 0%
2014-5-1 9:46:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-5-1 9:46:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2014-5-1 9:46:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-5-1 9:46:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-5-1 9:46:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2014-5-1 9:46:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 877 bytes
2014-5-1 9:46:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-5-1 9:46:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2014-5-1 9:46:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-5-1 9:46:40 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2014-5-1 9:46:40 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://master131:9000/output
2014-5-1 9:46:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2014-5-1 9:46:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2014-5-1 9:46:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2014-5-1 9:46:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2014-5-1 9:46:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=1221
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1516
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=83856
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=695
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=758
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=881
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Map input records=27
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=90
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=888
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=266469376
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=106
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Combine input records=52
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=45
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=45
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Combine output records=45
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=45
2014-5-1 9:46:44 org.apache.hadoop.mapred.Counters log
信息: Map output records=52















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









