







Break repeating-key XOR
There's a file here. It's been base64'd after being encrypted with repeating-key XOR.
Decrypt it.
Here's how:
1. Let KEYSIZE be the guessed length of the key; try values from 2 to (say) 40.
2. Write a function to compute the edit distance/Hamming distance between two strings. The Hamming distance is just the number of differing bits. The distance between:
this is a test
and
wokka wokka!!!
is 37. Make sure your code agrees before you proceed.
3. For each KEYSIZE, take the first KEYSIZE worth of bytes, and the second KEYSIZE worth of bytes, and find the edit distance between them. Normalize this result by dividing by KEYSIZE.
4. The KEYSIZE with the smallest normalized edit distance is probably the key. You could proceed perhaps with the smallest 2-3 KEYSIZE values. Or take 4 KEYSIZE blocks instead of 2 and average the distances.
5. Now that you probably know the KEYSIZE: break the ciphertext into blocks of KEYSIZE length.
6. Now transpose the blocks: make a block that is the first byte of every block, and a block that is the second byte of every block, and so on.
7.Solve each block as if it was single-character XOR. You already have code to do this.
8. For each block, the single-byte XOR key that produces the best looking histogram is the repeating-key XOR key byte for that block. Put them together and you have the key.
This code is going to turn out to be surprisingly useful later on. Breaking repeating-key XOR ("Vigenere") statistically is obviously an academic exercise, a "Crypto 101" thing. But more people "know how" to break it than can actually break it, and a similar technique breaks something much more important.
嗯… 这个挑战对我来说有点难。首先是汉明距离(Hamming distance between two strings),i don’t kown。我需要去了解,嗯…学习这个东西;其次是是归一化什么的(The KEYSIZE with the smallest normalized edit distance is probably the key)。
其实,说白了,我没有懂2到5步,猛男哭泣.jpg
汉明距离:https://en.wikipedia.org/wiki/Hamming_distance
嗯…challenge建议说猜测密钥长度为2到40。
for keysize in range(2,40):
然后第二步,是一个汉明距离。
zip函数:接受两个字符串,返回一个元组列表。
zip:https://docs.python.org/zh-cn/3/library/functions.html#zip
def hamming_distance(a,b) :
return sum(a != b for i,j in zip(a,b))
这个汉明距离。。和wiki上写的有点不太一样,我以为只需要字符串不一样的地方就可以了,但是challenge上有个例子,最开始没注意到。后来才发现不对。应该是用异或和二进制,然后sum 一下1的个数。
def hamming_distance(a,b) :
distance = 0
for i ,j in zip(a,b) :
byte = i^j
distance = distance + sum(k == '1' for k in bin(byte) )
return distance
嗯…第三步,猜测密钥,嗯…有点难,在我的浅显认知里,这段话应该是让我们把密文分成密钥大小的块,然后找到t他们(例如:第一个块和第二个块)之间的汉明距离。
Normalize this result by dividing by KEYSIZE. 对于这一句,其实我不太明白怎么就通过除以keysize 归一化。
但实现就完事。
for keysize in range(2,40) :
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
distances = []
for j in range(0, len(block)) :
block1 = block[j]
block2 = block[j+1]
distance = hanming_distance(block1,block2)
distance = distance / keysize
distances.append(distance)
嗯… 挑战提出可以只比较密文的前2-3个或者4个块,但从严谨性上,我比较了密文所分成的所有块,因为我个人觉得前面几个块可能不足以我找到正确的keysize
在写完整代码的时候,发现第三步的这一part 出现了一点点问题,一直在报错。
报错内容主要是这两个:
list assignment index out of range
list index out of range
对此,我想了很多方法去避免这个。
但是无论是我的哪种思路,他都出现了上诉第一种情况,最后我在循环中嵌套了一个try。ok了。
for keysize in range(2,40) :
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
distances = []
for i in range(0,len(block),2) :
try:
block1 = block[i]
block2 = block[i+1]
distance = hamming_distance(block1,block2)
distances.append(distance / keysize)
# print('11111',distance)
except :
break
第四步,The KEYSIZE with the smallest normalized edit distance is probably the key嗯… 归一化之后的汉明距离最小的keysize就很可能是密钥。嗯… 对于每一次keysize ,上面代码的distances 再次进行归一化 ,然后再找出最小的值,那个所对应的keysize应该就是密钥。
_distance = sum(distances) / len(distances)
data = {
'keysize' : keysize,
'distance': _distance
}
_data.append(data)
_keysize = sorted(_data, key = lambda distance:distance['distance'])[0]
# _keysize = min(_data,key = lambda distance:distance['diatance'])
第五步,将密文分成keysize长度的块
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
第六到第七步,转置块,然后单字暴力XOR就行。
简单来说就是:
ciphertext :123 456 789 123 456 789
key : i c e i c e i c e i c e i c e i c e
其中我们最初在第五步中将ciphertext安照keysize 分成了各个块,就是上面用空格分开形成的各个块。
每一个块的第一个字节,相当于上面ciphertext中黄色高亮部分,他们都是与 i 进行XOR ,因此,我们可以将ciphertext中黄色高亮部分 组成新的块,然后进行单字符XOR。
这是我最初的实现方式:
keysize = _keysize['keysize']
for i in range(0,keysize) :
new_block = []
t = b''
for j in range(0,len(block)) :
s = block[j]
t=t+byte([s[i]])
new_block.append(t)
在实现过程中,我的代码存在一些错误。而且不需要new_block了。
_keysize = Get_the_keysize(ciphertext)
keysize = _keysize['keysize']
print(keysize)
key = b''
cipher = b''
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
for i in range(0 , keysize) :
new_block = []
t = b''
for j in range(0,len(block)-1) :
s= block[j]
t=t+bytes([s[i]])
socre = ciphertext_XOR(t)
单字节XOR在之前的challenge中写过了,就不写了。
这是完整的代码:
#set1_6
import string
import re
from operator import itemgetter, attrgetter
import base64
def English_Scoring(t):
latter_frequency = {
'a': .08167, 'b': .01492, 'c': .02782, 'd': .04253,
'e': .12702, 'f': .02228, 'g': .02015, 'h': .06094,
'i': .06094, 'j': .00153, 'k': .00772, 'l': .04025,
'm': .02406, 'n': .06749, 'o': .07507, 'p': .01929,
'q': .00095, 'r': .05987, 's': .06327, 't': .09056,
'u': .02758, 'v': .00978, 'w': .02360, 'x': .00150,
'y': .01974, 'z': .00074, ' ': .15000
}
return sum([latter_frequency.get(chr(i),0) for i in t.lower()])
def Single_XOR(s,single_character) :
t = b''
#print(s,single_character)
# s = bytes.fromhex(s)
# t: the XOR'd result
for i in s:
t = t+bytes([i^single_character])
# t = re.sub(r'[\x00-\x1F]+','', t)
#remove the ascii control characters
return t
def ciphertext_XOR(s) :
_data = []
# s = bytes.fromhex(s)
# key = ord (single_character)
# ciphertext = b''
# for i in s :
# ciphertext = ciphertext + bytes([i ^ key])
for single_character in range(256):
ciphertext = Single_XOR(s,single_character)
#print(ciphertext)
score = English_Scoring(ciphertext)
data = {
'Single character' : single_character,
'ciphertext' : ciphertext,
'score' : score
}
_data.append(data)
score = sorted(_data, key = lambda score:score['score'], reverse=True)[0]
# print(score['ciphertext'])
return score
def Repeating_key_XOR(_message,_key) :
cipher = b''
length = len(_key)
for i in range(0,len(_message)) :
cipher = cipher + bytes([_message[i]^_key[i % length]])
# print(cipher.hex())
return cipher
"""
if __name__ == '__main__':
_data = []
s = open('cryptopals_set1_4.txt').read().splitlines()
for i in s :
# print(i)
data = ciphertext_XOR(i)
_data.append(data)
best_score = sorted(_data, key = lambda score:score['score'], reverse=True)[0]
print(best_score)
for i in best_score :
print("{}: {}".format(i.title(), best_score[i]))
# print(f'{j}:{t},{score}')
"""
def hamming_distance(a,b) :
distance = 0
for i ,j in zip(a,b) :
byte = i^j
distance = distance + sum(k == '1' for k in bin(byte) )
return distance
def Get_the_keysize(ciphertext) :
data = []
for keysize in range(2,41) :
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
distances = []
for i in range(0,len(block),2) :
try:
block1 = block[i]
block2 = block[i+1]
distance = hamming_distance(block1,block2)
distances.append(distance / keysize)
except :
break
_distance = sum(distances) / len(distances)
_data = {
'keysize' : keysize,
'distance': _distance
}
data.append(_data)
_keysize = sorted(data, key = lambda distance:distance['distance'])[0]
# print("123456789456123",_keysize)
#_keysize = min(data,key = lambda distance:distance['diatance'])
return _keysize
def Break_repeating_key_XOR(ciphertext):
# Guess the length of the key
_keysize = Get_the_keysize(ciphertext)
keysize = _keysize['keysize']
print(keysize)
key = b''
cipher = b''
block = [ciphertext[i:i+keysize] for i in range(0,len(ciphertext),keysize)]
for i in range(0 , keysize) :
new_block = []
t = b''
for j in range(0,len(block)-1) :
s= block[j]
t=t+bytes([s[i]])
socre = ciphertext_XOR(t)
key = key + bytes([socre['Single character']])
# cipher = cipher + socre['ciphertext']
# print(cipher)
for k in range(0,len(block)) :
cipher = cipher+Repeating_key_XOR(block[k],key)
# print(key)
return cipher,key
# sorted(data, key = lambda distance:distance['distance'])[0]
if __name__ == '__main__' :
with open('cryptopals_set1_6.txt') as of :
ciphertext = of.read()
ciphertext = base64.b64decode(ciphertext)
cipher,key = Break_repeating_key_XOR(ciphertext)
print("cipher:",cipher,"\nkey:",key)
上诉代码存在一定不足。基本找到了key并且解出了cipher。但是存在'\x11'、'\x16'这些常理来说明文中不会出现的字符
哦,没事了,代码时对的。。。。
跑错了,跑成没改完的代码了。。。。。
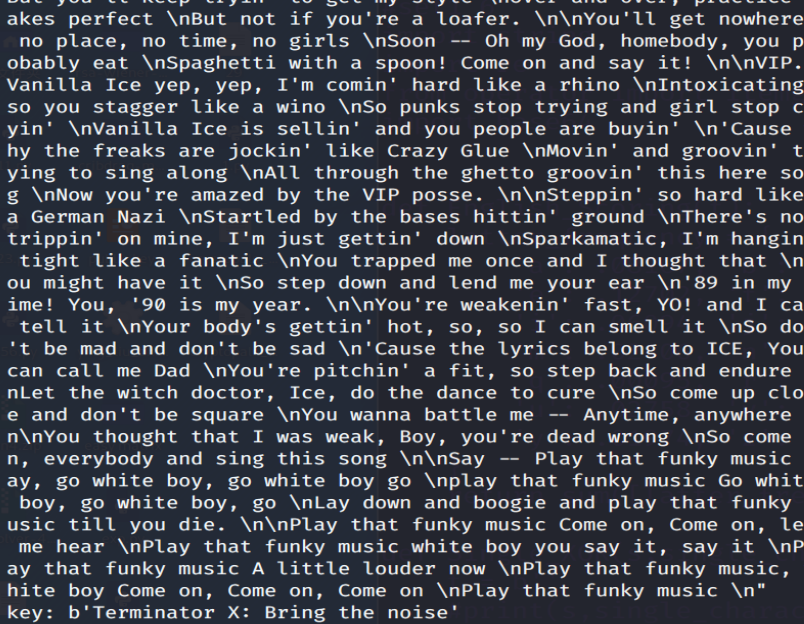
另外,我发现我之前写的关于第四关的字符串异或的代码不够简洁,导致我后续使用时需要更改。(因为我之前是在主函数中循环遍历需要爆破异或的字符,然后在ciphertext_XOR中用Single_XOR和English_Scoring函数实现,但是现在发现这样的不够简单、明了、直观)
原代码:
def ciphertext_XOR(s,single_character) :
_data = []
s = bytes.fromhex(s)
# key = ord (single_character)
# ciphertext = b''
# for i in s :
# ciphertext = ciphertext + bytes([i ^ key])
ciphertext = Single_XOR(s,single_character)
#print(ciphertext)
score = English_Scoring(ciphertext)
data = {
'Single character' : single_character,
'ciphertext' : ciphertext,
'score' : score
}
_data.append(data)
score = sorted(_data, key = lambda score:score['score'], reverse=True)[0]
return score
if __name__ == '__main__':
_data = []
s = open('cryptopals_set1_6.txt').read().splitlines()
for i in s :
# print(i)
for j in range(256):
data = ciphertext_XOR(i,j)
_data.append(data)
best_score = sorted(_data, key = lambda score:score['score'], reverse=True)[0]
print(best_score)
for i in best_score :
print("{}: {}".format(i.title(), best_score[i]))
#print(f'{j}:{t},{score}')
新代码:
def ciphertext_XOR(s) :
_data = []
s = bytes.fromhex(s)
# key = ord (single_character)
# ciphertext = b''
# for i in s :
# ciphertext = ciphertext + bytes([i ^ key])
for single_character in range(256):
ciphertext = Single_XOR(s,single_character)
#print(ciphertext)
score = English_Scoring(ciphertext)
data = {
'Single character' : single_character,
'ciphertext' : ciphertext,
'score' : score
}
_data.append(data)
score = sorted(_data, key = lambda score:score['score'], reverse=True)[0]
return score















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









