







一、语言的分类
1、DDL 数据库定义语言 影响数据结构的,增删改查库或表。
2、DML 数据库操作语言 操作数据,对表中数据的增删改查。
3、DCL 数据库控制语言 无。创建用户,管理用户权限,事务控制。
非标准分类:DQL 数据库查询语言 把对数据的增删改查中的查单提出来。
另外一种分类:
DDL (数据定义语言)
数据定义语言 - Data Definition Language
用来定义数据库的对象,如数据表、视图、索引等
DML (数据操纵语言)
数据处理语言 - Data Manipulation Language
在数据库表中更新,增加和删除记录
如 update, insert, delete
DCL (数据控制语言)
数据控制语言 – Data Control Language
指用于设置用户权限和控制事务语句
如grant,revoke,if…else,while,begin transaction
DQL (数据查询语言)
数据查询语言 – Data Query Language
select
二、连接数据库和退出数据库
mysql -u root -p
exit
三、数据库的操作语句
创建库
create database 库名 [character set 码表 collate 字符校对集]
显示所有库
show databases;
删除库
drop database 库名;
修改数据库码表
alter database 库名 character set 码表 collate 字符校对集
使用数据库
use 库名
查看当前使用的库
select database();
显示创建库语句
show create database 库名;
四、数据库中的数据类型
1、数字型
整型:
一般常用的是INT,占4个字节。如果觉得不够用,还有一个BIGINT,占8个字节。
浮点型:
一般用的是FLOAT,占4个字节。DOUBLE占8个字节,DECIMAL和DOUBLE的区别在于,DOUBLE在运算时有精度的缺失,DECIMAL就是解决精度缺失的问题的。因此如果单纯想表示小数属性的时候,就用DOUBLE,需要频繁参与运算的小数,这时就要用到DECIMAL了。
2、字符串型
注意:字符串类型要用单引号包裹。
短字符串类型:CHAR/VARCHAR(最大长度255)
这里两者有什么区别呢,CHAR是定长字符串,VARCHAR是变长字符串。比如:存储abc时候,指定长度为10,用CHAR的话,后面会自动填充7个空。而用VARCHAR的时候就是abc,因此开发中常用VARCHAR.
长字符串类型:TEXT/CLOB 保存文本–> 当要保存的内容超过255字节时使用。
BLOB 保存字节(字节流) –> 开发中用不到;
区别:
text:只能存储字符数据.
BLOB:可以存储字符和多媒体信息(图片 声音 图像)
3、日期和时间类型
date 只记录日期 2016-08-03
time 只记录时间 21:36:25
year 只记录年 2016
datatime 又记录日期 又记录时间
2016-08-03 11:36:25
**timestamp 同上 2016-08-03 21:36:25datatime 和 timestamp 区别在于,timestamp没有 传值时,那么该类型默认值就是当前时间。datatime类型没有传值时,那么该类型默认值就是null;
4、与创建表相关的语句(DDL)
1.创建表
create table t_user(
id int,
name varchar(20),
sal double(4,3),
birthday datetime,
hiredate timestamp
);
varchar最好指定长度
整型一般不指定.
2.查看当前库中有哪些表
show tables;
3.查看表的结构
desc 表名; description
desc t_user;
4.删除表
drop table 表名;
drop table t_user;
5.添加一列
alter table 表名 add 列名 类型;
alter table t_user add photo blob;
6.修改列的类型
alter table 表名 modify 列名 类型;
alter table t_user modify photo varchar(20);
7.修改列的名称
alter table 表名 change 旧列名 新列名 数据类型;
将 photo这一列 改名为 image
alter table t_user change photo image varchar(20);
8.删除某列
alter table 表名 drop 列名;
alter table t_user drop image;
9.修改表的名称
rename table 旧表名 to 新名;
rename table t_user to user;
10(用的极少)修改表的字符集. (如果创建表时不指定,默认使用数据库的字符集)
alter table 表名 character set 字符集 collate 校对集;
alter table t_user character set utf8 collate utf8_bin;五、约束
列的约束 ,保证数据的完整性的因此.约束是体现数据库的完整性.
1、非空约束(not null) 指定非空约束的列, 在插入记录时 必须包含值.
2、唯一约束(unique) 该列的内容在表中. 值是唯一的.
3、主键约束:当想要把某一列的值,作为该列的唯一标示符时,可以指定主键约束(包含 非空约束和唯一约束). 一个表中只能指定一个主键约束列.主键约束 , 可以理解为 非空+唯一.
注意: 并且一张表中只能有一个主键约束.
例子:创建带有约束的表
create table t_user2(
id int primary key auto_increament, -- 员工编号
name varchar(10) not null, -- 员工姓名
loginname varchar(10) not null unique, -- 登陆名称
password varchar(20) not null, -- 密码
age int(3) not null, -- 年龄
birthday datetime not null, -- 生日
hiredate timestamp not null -- 入职日期
);create table t_user2(
id int primary key auto_increament, name varchar(10) not null,
loginname varchar(10) not null unique,
password varchar(20) not null,
age int(3) not null,
birthday datetime not null,
hiredate timestamp not null
);主键自动增长
注意:
1.前提某个表的主键是数字. 我们可以将该主键设置为自增.
2.使用主键自增可能会造成主键的断层。
3.mysql,sqlserver,sqllite这三个数据库具有该功能.
4.主键自增只能给主键约束的列加。
自增就是 每次插入记录时不需要指定值. 该字段自己维护自己的值.维护方式就是每次加1;
语法:
create table t_user(
id int primary key auto_increment,
password varchar(30) not null,
age int not null,
birthday datetime not null,
hiredate timestamp not null,
number int unique
);练习——————创建修改表练习
CREATE TABLE employee (
id INT(10),
NAME VARCHAR(10),
gender VARCHAR(10),
birthday DATETIME,
entry_date TIMESTAMP,
job VARCHAR(5),
salary DOUBLE(5,3),
RESUME TEXT
);1在上面员工表的基础上增加一个image列。
alter table employee add image varchar(20);
2修改job列,使其长度为60。
alter table employee modify job varchar(60);
3删除gender列。
alter table employee drop gender;
4表名改为user。
rename table employee to user;
5修改表的字符集为utf8
6列名name修改为username
alter table employee change name username varchar(20);
练习————对表中数据的增删改(DML)
create table t_user(
id int primary key auto_increment,
name varchar(20) not null,
email varchar(20) unique
)(1)为表添加记录
insert into 表名[(列名1,列名2…)] values (值1,值2…);
1.插入一条数据
1>指定要插入那些列
insert into t_user(name,email) values('tom','tom@itcast.cn');
****注意: 数据类型为字符串类型的.需要使用单引号包裹.
2>不指定插入哪些列, 需要指定每一列的值
insert into t_user values(null,'jerry','jerry@itcast.cn');
insert into t_user(name,email) values('汤姆','tom2@itcast.cn');
SHOW VARIABLES LIKE ‘%character%’; ==> 查看字符编码配置
| character_set_client | gbk 客户端的编码 ***
|
| character_set_results | gbk 结果集的编码 ***
|
| character_set_connection | utf8 客户端连接的编码
|
| character_set_database | utf8 数据库默认使用的编码
|
| character_set_filesystem | BINARY 文件系统存放时使用的编码
|
| character_set_server | utf8 服务器编码 安装时指定的
|
| character_set_system | utf8 内部系统编码
结论: 如果使用cmd 命令控制台操作数据库,
注意character_set_client 和 character_set_results 需要设置成GBK, 因为我们的命令控制行使用gbk码表显示中文.
使用如下命令设置:
方式:
set character_set_client=gbk
set character_set_results=gbk
注意:
每次重新连接数据库都要重新设置.
如果使用的cmd窗口操作数据库. 就修改如下的码表为gbk(cmd窗口使用的是gbk码表). 这种做法影响的范围只在你当前连接中.
(2)修改一条记录
update 表名 set 列名1 = 值 , 列名2 = 值 ....[where 条件1,条件2...]
练习1:
create table t_user(
id int primary key auto_increment,
name varchar(20) not null,
email varchar(20) unique
)修改表中id为3 的记录, 将name修改为rose;
update t_user set name='rose' where id=3;
update t_user set name='rose';
练习2:
CREATE TABLE employee (
id INT,
NAME VARCHAR(20),
gender VARCHAR(20),
birthday DATE,
entry_date DATE,
job VARCHAR(30),
salary DOUBLE,
RESUME LONGTEXT
);
INSERT INTO employee VALUES(1,'zs','male','1980-12-12','2000-12-12','coder',4000,NULL);
INSERT INTO employee VALUES(2,'ls','male','1983-10-01','2010-12-12','master',7000,NULL);
INSERT INTO employee VALUES(3,'ww','female','1985-03-08','2008-08-08','teacher',2000,NULL);
INSERT INTO employee VALUES(4,'wu','male','1986-05-13','2012-12-22','hr',3000,NULL); -- 要求
-- 将所有员工薪水修改为5000元。
update employee set salary=5000;
-- 将姓名为’zs’的员工薪水修改为3000元。
update employee set salary=3000 where name = "zs";
-- 将姓名为’ls’的员工薪水修改为4000元,job改为ccc。
update employee set salary=4000,job = "ccc" where name="ls";
-- 将wu的薪水在原有基础上增加1000元。
update employee set salary = salary+1000 where name ="wu"; (3)删除记录语句
DELETE FROM 表名 [WHERE 条件];1. 删除表中名称为’rose’的记录。
DELETE FROM employee WHERE NAME='rose';
2. 删除表中所有记录。
DELETE FROM employee ;
3.使用truncate删除表中记录。
TRUNCATE TABLE employee;
DELETE 删除 和 TRUNCATE删除(了解) 两者有什么区别?
首先,这两种都是删除表中的记录.
不同的是:
1. delete 是逐行标记删除. TRUNCATE 是将整张表包括表结构都移除,然后将表重新创建.
2. delete DML语句。 TRUNCATE DDL语句。
3.delete 删除的记录可以被恢复,TRUNCATE 不能回复。
4. delete 不释放空间,TRUNCATE 释放空间.
5. TRUNCATE 会提交事务.DQL语句(DML) 查询语句.
语法:
SELECT selection_list /*要查询的列名称*/
FROM table_list /*要查询的表名称*/
WHERE condition /*行条件*/
GROUP BY grouping_columns /*对结果分组*/
HAVING condition /*分组后的行条件*/
ORDER BY sorting_columns /*对结果排序*/
LIMIT offset_start, row_count /*结果限定*/创建两个表stu和emp
stu表
CREATE TABLE stu ( --学生表
sid CHAR(6), -- 学生编号
sname VARCHAR(50), -- 学生姓名
age INT, -- 年龄
gender VARCHAR(50) -- 性别
);
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);emp表
CREATE TABLE emp( -- 员工表
empno INT, -- 员工编号
ename VARCHAR(50), -- 员工姓名
job VARCHAR(50), -- 工作
mgr INT, -- 员工上司的编号
hiredate DATE, -- 入职日期
sal DECIMAL(7,2), -- 工资
comm DECIMAL(7,2), -- 奖金
deptno INT -- 部门编号
);
INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);练习1
1.1 查询所有行所有列
select * from stu;
*号 是通配符.通配所有列. 上面语句与下面是一模一样的
select sid,sname,age,gender from stu;
谁的效率更高?
下面的效率更高. *需要运算.
1.2 查询所有行指定列
select sname from stu;
2.1 条件查询介绍
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
? =、!=、<>、<、<=、>、>=;
? BETWEEN…AND;
? IN(SET)/NOT IN(SET)
? IS NULL/IS NOT NULL
//---条件连接符
? AND; &&
? OR; ||
? NOT; !
2.2 查询性别为女,并且年龄小于50的记录
select * from stu where gender='female' and age<50;
2.3 查询学号为S_1001,或者姓名为liSi的记录
select * from stu where sid='S_1001' or sname='liSi';
数据库中,sql语句不区分大小写 ,但是 数据区分大小写.
2.4 查询学号为S_1001,S_1002,S_1003的记录
select * from stu where sid='S_1001' or sid='S_1002' or sid='S_1003';
select * from stu where sid in('S_1001','S_1002','S_1003');
2.5 查询学号不是S_1001,S_1002,S_1003的记录
select * from stu where not (sid='S_1001' or sid='S_1002' or sid='S_1003');
select * from stu where sid not in('S_1001','S_1002','S_1003');
2.6 查询年龄为null的记录
select * from stu where age=null;
null的特性: null不等于null 所以判断时应如下写法:
select * from stu where age is null;
2.7 查询年龄在20到40之间的学生记录
select * from stu where age >= 20 and age <= 40;
select * from stu where age between 20 and 40;
2.8查询性别非男的学生记录
select * from stu where gender!= 'male';
select * from stu where not gender='male';
select * from stu where gender not in ('male');
2.9 查询姓名不为null的学生记录
select * from stu where sname is not null;
select * from stu where not sname is null;练习2
where 字段 like '表达式';
% => 通配 通配任意个字符.
_ => 通配 通配单个字符.
说明: LIKE 条件后 根模糊查询表达式, "_"==> 代表一个任意字符
3.1查询姓名由5个字母构成的学生记录
select * from stu where sname like '_____';
3.2查询姓名由5个字母构成,并且第5个字母为“i”的学生记录
select * from stu where sname like '____i';
3.3 查询姓名以“z”开头的学生记录
说明: "%"该通配符匹配任意长度的字符.
select * from stu where sname like 'z%';
3.4查询姓名中第2个字母为“i”的学生记录
select * from stu where sname like '_i%';
3.5 查询姓名中包含“a”字母的学生记录
select * from stu where sname like '%a%';
4.1 去除重复记录
关键词: distinct => 去除重复查询结果记录.
select gender from stu; ==> 出现大量重复的记录
select distinct gender from stu; =>去除重复的记录
4.2查看雇员的月薪与佣金之和
select sal*12+comm from emp;
null与任何数字计算结果都是null.上面的写法是错误的.
使用IFNULL(参数1,参数2) 函数解决. 判断参数1的值是否为null,如果为null返回参数2的值.
select sal*12 + IFNULL(comm,0) from emp;
*这个函数在所有数据库通用吗?
不通用.
4.3 给列名添加别名
select sal*12 + IFNULL(comm,0) as '年收入' from emp;
** select sal*12 + IFNULL(comm,0) '年收入' from emp;
select sal*12 + IFNULL(comm,0) 年收入 from emp;
5.1 查询所有学生记录,按年龄升序排序
asc: 升序
desc:降序
select * from stu order by age asc;
默认就是升序
select * from stu order by age;
5.2 查询所有学生记录,按年龄降序排序
select * from stu order by age desc;
5.3 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
select * from emp order by sal desc , empno asc;六、聚合函数
聚合函数是用来做纵向运算的函数:
COUNT():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
6.1 COUNT
当需要纵向统计时可以使用COUNT()。
1>查询emp表中记录数:
select count(*) from emp;
2>查询emp表中有佣金的人数:
select count(*) from emp where comm is not null and comm >0;
3>查询emp表中月薪大于2500的人数:
select count(*) from emp where sal > 2500;
4>统计月薪与佣金之和大于2500元的人数:
select count(*) from emp where sal+IFNULL(comm,0) > 2500;
5>查询有佣金的人数并且有领导的人数:
select count(*) from emp where comm > 0 and mgr is not null;
6.2 SUM(计算总和)和AVG(计算平均值)
当需要纵向求和时使用sum()函数。
1>查询所有雇员月薪和:
select sum(sal) from emp;
2>查询所有雇员月薪和,以及所有雇员佣金和:
select sum(sal),sum(comm) from emp;
3>查询所有雇员月薪+佣金和:
select sum(sal+IFNULL(comm,0)) from emp;
4>统计所有员工平均工资:
select avg(sal) from emp;
6.3 MAX和MIN
查询最高工资和最低工资:
select max(sal),min(sal) from emp;分组查询
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
1>查询每个部门的部门编号和每个部门的工资和:
select deptno,sum(sal) from emp group by deptno;
2>查询每个部门的部门编号以及每个部门的人数:
select deptno,count(ename) from emp group by deptno;
3>查询每个部门的部门编号以及每个部门工资大于1500的人数:
select deptno,count(ename) from emp where sal>1500 group by deptno ;
HAVING子句
4>查询工资总和大于9000的部门编号以及工资和:
select deptno,sum(sal) from emp group by deptno having sum(sal)>9000;使用having在分组之后加条件.
where和having都可以加条件?
1.where在分组之前加条件.
2.having在分组之后加条件.
where的效率要远远高于having. 分组本身消耗资源非常大.
试题:where 和 having 条件语句的区别 ?
where 是在分组前进行条件过滤,having 是在分组后进行条件过滤
使用where地方都可以用 having替换 , 但是having可以使用分组函数,而where后不可以用分组函数
分页相关知识
LIMIT(MySQL方言)
LIMIT用来限定查询结果的起始行,以及总行数。
1>查询5行记录,起始行从0开始
select * from emp limit 0,5;
2> 查询10行记录,起始行从3开始
select * from emp limit 3,10;
3>如果一页记录为5条,希望查看第3页记录应该怎么查呢?
第一页记录起始行为0,一共查询5行;
select * from emp limit 0,5;
第二页记录起始行为5,一共查询5行;
select * from emp limit 5,5;
第三页记录起始行为10,一共查询5行;
select * from emp limit 10,5;七、多表设计——外键约束
CREATE TABLE teacher (
id int(11) NOT NULL primary key auto_increment,
name varchar(20) not null unique
);
CREATE TABLE student (
id int(11) NOT NULL primary key auto_increment,
name varchar(20) NOT NULL unique,
score double default '0',
teacher_id int(11) NOT NULL,
FOREIGN KEY (teacher_id) REFERENCES teacher (id)
) ;八、MySQL 数据库的备份和恢复
1、备份命令 mysql/bin/mysqldump 将数据库SQL语句导出
语法:mysqldump -u 用户名 -p 数据库名 > 磁盘SQL文件路径
例如: 备份day12数据库 — c:\day12.sql
cmd > mysqldump -u root -p day12 > c:\day12.sql 回车输入密码
INSERT INTO exam VALUES (1,’关羽’,85,76,70),(2,’张飞’,70,75,70),(3,’赵云’,90,65,95),(4,’刘备’,NULL,55,38);
2、恢复命令 mysql/bin/mysql 将sql文件导入到数据库
语法: mysql -u 用户名 -p 数据库名 < 磁盘SQL文件路径
* 导入SQL 必须手动创建数据库 ,SQL不会创建数据库
例如:将c:\day12.sql 导入 day12数据库
cmd > mysql -u root -p day12 < c:\day12.sql 回车密码
补充知识:恢复SQL也可以在数据库内部执行 source c:\day12.sql
多表查询——内连接查询
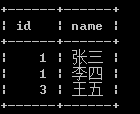

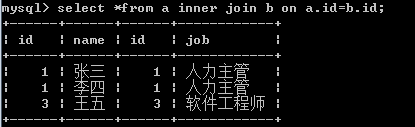















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









