






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
1.
提示:以下是本篇文章正文内容,下面案例可供参考
一、复杂查询的相关操作:
1.主键 primary key
针对每一条记录,作为身份标识
唯一性:不重复(身份证,电话号码)
不为空
简单来说primary相当于unique+not null,一个表里,主键只能有
一个,但unique则是可以有多个的
create table student2(id int primary key,name varchar(20));

遇到的问题:

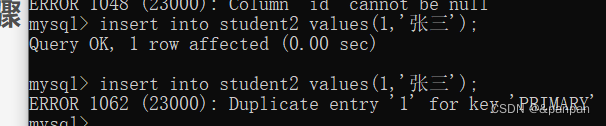 分别违背了非空型和唯一性;
分别违背了非空型和唯一性;
我们在使用逐渐时候,需要设置一个唯一值,mysql提供‘自增主键,自动设置主键值;primary key auto_increment
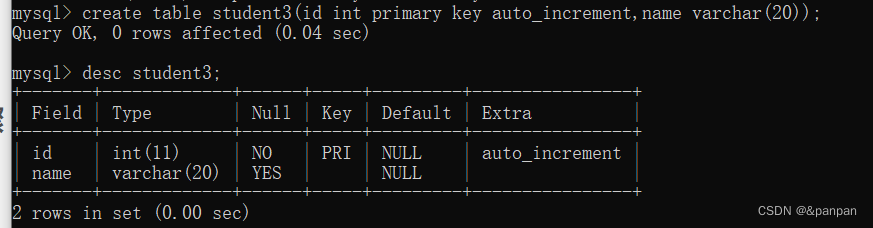
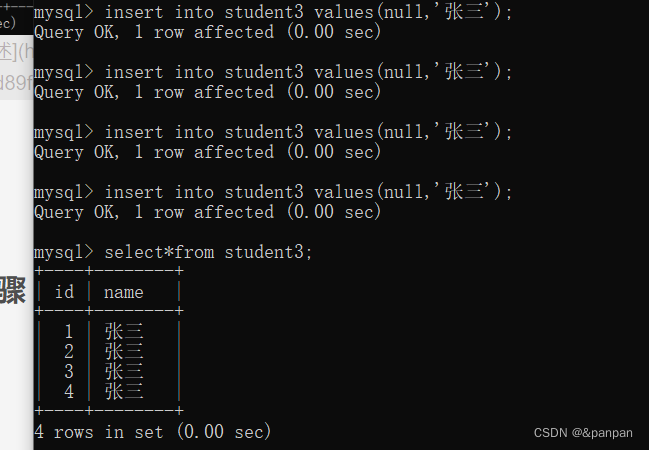
依次递增
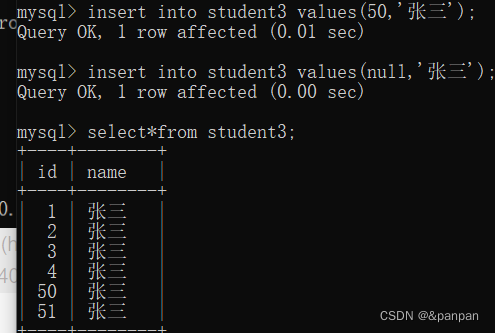
手动分配后依次递增
结论:自增主键,可以理解成mysqll里记录了当前足以大值id是几,都是从最大值之后在进行增加的-
2)数据库分布式部署:
当表太大,一台机器存不下,拆成多个表在不同机子上,还能不能满足主键的唯一性呢,不能!!!
解决方案:分布式系统生成唯一id算法
生成公式=(时间戳+机房编号/主机编号+随机因子)=》计算哈希值
2.外键foreign key
关联俩个表,例学生表里的每一个记录(字表),包含班级编号得在班级表中存在(父表)
create table class(classId int,name varchar(20));
create table student(studentId int primary key,name varchar(20),foreign key(studentId) references class(classId);

当建立好外键约数,学生表中(字表)中插入记录calssid必须在班级表(父表)中存在,此时班级表对学生表产生了约数
*此处要求子表中引用父表的这一列,务必得是primary key或者unique
子表对附表也有约数:
子表存在情况,这一届删除父表会出现问题
总结:
父限子(增,改)
子限父(删,改)
3.逻辑删除
如果想要在外键约数下删除可以采用逻辑删除的方式
二.表的设计
数据库设计主要思路:
1.根据需求找到实体(描述的关键词)
2.梳理清楚实体之间的关系
- 一对一 学生账号
- 一对多 学生班级
- 多对多 学生课程 (关联表)
- 没关系
一般来说每个实体都会安排一个表
*
sql可以把查询结果插入到另一张表里:
insert into student2 select*from student where id!=1;(把student 里的数据查出来,插入到student2里面
三.聚合查询
:
又来聚合函数就可以进行行和行的运算
常见聚合函数:count() 计算行数 sum() 行相加 avg() max() min()
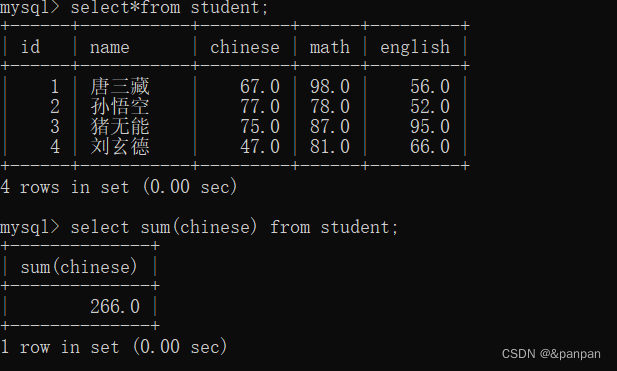
select count(*)from student;
计算行的个数4
select count(0)from student where english>60;
分组查询/聚合:
把值相同的记录,分成一组,然后针对每一组进行聚合
eg:查询每个岗位的薪资(最高,平均,最低)
mysql> select*from emp;
±—±-------------±-------------±---------+
| id | name | role | salary |
±—±-------------±-------------±---------+
| 1 | 马云 | 服务员 | 1000.20 |
| 2 | 马化腾 | 游戏陪玩 | 2000.99 |
| 3 | 孙悟空 | 游戏角色 | 999.11 |
| 4 | 猪无能 | 游戏角色 | 333.50 |
| 5 | 沙和尚 | 游戏角色 | 700.33 |
| 6 | 隔壁老王 | 董事长 | 12000.66 |
select role from emp group by role;
±-------------+
| role |
±-------------+
| 服务员 |
| 游戏角色 |
| 游戏陪玩 |
| 董事长 |
±-------------+
mysql> select role,count(0),min(salary) from emp group by role;最低薪资
±-------------±---------±------------+
| role | count(0) | min(salary) |
±-------------±---------±------------+
| 服务员 | 1 | 1000.20 |
| 游戏角色 | 3 | 333.50 |
| 游戏陪玩 | 1 | 2000.99 |
| 董事长 | 1 | 12000.66 |
±-------------±---------±------------+
select*from emp group by role;
这里相当于只展示每一组的第一条记露
分组查询还可以进行筛选条件
1.分组之前筛选 where
2.分组之后筛选 having
eg:1.查询每个岗位平均薪资(除去张三这个记录)
思路:先把张三去掉,在分组
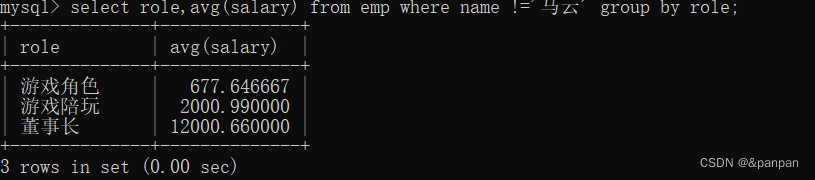
2.查询平均薪字>1000岗位
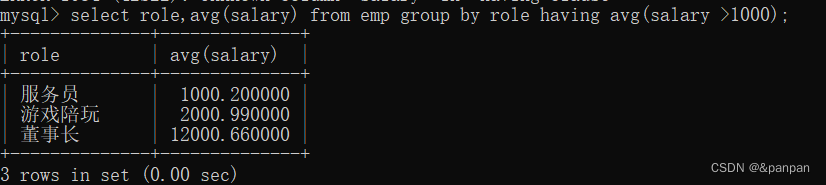
此处先进行分组,算好平均薪资,然后再找到平均薪资>1000岗位
having写到group后面(分完组才能算平均薪资)
3.求除了张三之外,每个岗位的平均薪资,并且保留平均薪资》1000岗位

so:where写在group by之前
having之后 搭配聚合查询语句
四.联合查询:
笛卡尔积其实就是简单的排列组合
行数,是两个表的行数之积,
列数,是两个表的列数之和
联合/多表查询=笛卡尔积+链接条件+其他条件
selectfrom student ,class(笛卡尔积)或者 selctfrom student join class on …
where student.classid=class.classid(链接条件)
五.外连接
1.表上的数据不在一一对应
from 表1,表2 内连接
from 表1 join 表2 on 条件 使用join 可以作为内连接,也可以作为外连接
直接写join或者inner join是内连接
写作left join左外连接
right join 右外连接
左外连接会尽可能显示左侧数据,右侧没有体现填null,右侧相反。
左外和右外主要看表的先后顺序在join左侧还是右侧
六.自连接
自己和自己做笛卡尔积,条件查询中,核心在于列和列之间的比较,而从来没有进行行与行的交换
select*form 表名 as 列名 表名 as 列名
七.子查询
本质上是吧多个查询语句,组合成一个查询一局(套娃)
如果子查询返回的结果有多条就用in来进行子查询
八.合并查询
union(去重)/union all(不去重)来完成两个查询结果合在一起(并集)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









