







什么是 Java 代码重构?
Java 代码重构是一种在不影响代码外部行为的前提下进行的代码优化,它通过渐进和小规模的优化来改善现有代码的结构和质量。重构的目标是提高代码的可读性、性能、可维护性和效率等。
Martin Fowler 是这个领域的权威的大牛和非常高产的作家,他在多篇文章和书籍中探讨了代码设计和重构的主题。在他的作品《重构:改善既有代码的设计》中,他精辟地解释了重构的本质:
“重构是在不改变代码外在行为的前提下,对代码做出修改,以改进程序内在结构的过程。重构是一种经过千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减少整理过程中引入的错误几率。其核心是不断进行一些小的优化,每个优化看似不起眼,但积少成多,效果显著。”
——Martin Fowler
在进行 Java 代码重构时,可以考虑以下常见的优化措施:
- 为变量、类、函数和其他元素重命名,使其具有更好的可读性和自描述性。
- 通过内联减少方法或函数调用,使用更简洁的内容。
- 抽取函数中的代码块,并将它们移到新的独立函数中,以增强模块性和可读性。
- 消除冗余,通过删除相同功能的多个代码片段,并将它们合并为一个。
- 拆分处理过多职责的类或模块,将其分解为更小、更有内聚的组件。
- 合并具有相似功能的类或模块,简化结构。
- 进行代码性能方面的优化。
Java 代码重构技巧
变量和方法的重新命名
为变量和方法选择具有代表性的名称是增强代码可读性的重要方法。
代码的可读性是构建高质量代码库的关键要素之一。易读的代码能够清晰地表达其目的,而难以理解的代码则会增加重构过程中出现错误的风险。采用有意义的变量和方法名称可以减少注释的需求,并降低沟通成本。
// 重构前
int d = 30; // 天数
int h = 24; // 一天的小时数
// 重构后
int daysInMonth = 30;
int hoursInDay = 24;方法的提取
在 Java 代码重构技术中,方法的提取是一种常见而实用的策略。当一个方法变得过长和过于复杂时,通过提取部分功能到一个新的方法中能够使原方法更简洁和易读。这不仅使代码更具可维护性,还提高了其可重用性。
假设你有一个简单的类,用于处理订单并计算小计、税费和总费用。
public class OrderProcessor {
private List<Item> items;
private double taxRate;
public double processOrder() {
double subtotal = 0;
for (Item item : items) {
subtotal += item.getPrice();
}
double totalTax = subtotal * taxRate;
double totalCost = subtotal + totalTax;
return totalCost;
}
}你可以将该代码重构,把计算小计、税费和总费用的代码分别提取到 calculateSubtotal、calculateTax 和 calculateTotalCost 三个独立的方法中,从而使类更加易读、模块化和可重用。
public class OrderProcessor {
private List<Item> items;
private double taxRate;
public double processOrder() {
double subtotal = calculateSubtotal();
double totalTax = calculateTax(subtotal);
return calculateTotalCost(subtotal, totalTax);
}
private double calculateSubtotal() {
double subtotal = 0;
for (Item item : items) {
subtotal += item.getPrice();
}
return subtotal;
}
private double calculateTax(double subtotal) {
return subtotal * taxRate;
}
private double calculateTotalCost(double subtotal, double totalTax) {
return subtotal + totalTax;
}
}消除“魔法”数字和字符串
“魔法”数字和字符串是指直接硬编码在代码中的值。这种做法不仅会降低代码的可维护性,还可能因输入错误而导致结果不一致和错误的增多。为了避免这样的问题,你应当避免使用硬编码的值,而是通过使用具有清晰描述性的常量来重构你的代码。
// 重构前
if (status == 1) {
// ... 活跃状态的代码 ...
}
// 重构后
public static final int ACTIVE_STATUS = 1;
if (status == ACTIVE_STATUS) {
// ... 活跃状态的代码 ...
}代码复用
代码复用是指删除代码库中多处出现的重复或相似的代码段。这样的代码不仅降低了代码质量和效率,还可能导致 bug 更加频繁的出现和代码库变得更加复杂。因此,开发人员通常会对这类代码感到反感。为了优化代码,我们可以考虑提取重复部分来创建可复用的方法或函数,同时确保重构过程中保持原有代码的功能和逻辑。
重构前
public class NumberProcessor {
// 计算总和
public int calculateTotal(int[] numbers) {
int total = 0;
for (int i = 0; i < numbers.length; i++) {
total += numbers[i];
}
return total;
}
// 计算平均值
public double calculateAverage(int[] numbers) {
int total = 0;
for (int i = 0; i < numbers.length; i++) {
total += numbers[i];
}
double average = (double) total / numbers.length;
return average;
}
}重构后
public class NumberProcessor {
// 计算总和
public int calculateSum(int[] numbers) {
int total = 0;
for (int i = 0; i < numbers.length; i++) {
total += numbers[i];
}
return total;
}
// 计算总和
public int calculateTotal(int[] numbers) {
return calculateSum(numbers);
}
// 计算平均值
public double calculateAverage(int[] numbers) {
int total = calculateSum(numbers);
double average = (double) total / numbers.length;
return average;
}
}在优化后的代码中,我们将用于计算数组总和的逻辑提取到了一个名为 calculateSum 的独立方法中。现在,calculateTotal 和 calculateAverage 方法可以直接调用 calculateSum 来获取数组的总和,从而避免了代码重复。
简化方法
随着时间的推移,随着维护代码的人越来越多,代码库容易变得陈旧和混乱。为保证代码的清晰度和易维护性,就非常有必要对代码进行重构,使其更易理解、维护和扩展。
在简化方法的过程中,首先要识别出那些包含复杂嵌套逻辑和承担过多职责的方法。接着,可以通过以下几步来简化它们:
- 遵循单一责任原则(SRP)来调整方法的功能划分。
- 将部分功能提取出来,创建新的子方法。
- 删除无用和冗余的代码。
- 减少方法内部的嵌套层次,使其结构更清晰。
接下来,我们将通过一个 Java 代码重构示例来具体展示如何简化方法。
简化前
public class ShoppingCart {
private List<Item> items;
// 计算总价
public double calculateTotalCost() {
double total = 0;
for (Item item : items) {
if (item.isDiscounted()) {
total += item.getPrice() * 0.8;
} else {
total += item.getPrice();
}
}
if (total > 100) {
total -= 10;
}
return total;
}
}我们可以通过提取 calculateItemPrice 逻辑到 calculateItemPrice 和 applyDiscount 方法中,并使用三元运算符来简化条件判断,使上述示例更为简洁。
简化后
public class ShoppingCart {
private List<Item> items;
// 计算总价
public double calculateTotalCost() {
double total = 0;
for (Item item : items) {
total += calculateItemPrice(item);
}
total -= applyDiscount(total);
return total;
}
// 计算价格
private double calculateItemPrice(Item item) {
return item.isDiscounted() ? item.getPrice() * 0.8 : item.getPrice();
}
// 获取满减
private double applyDiscount(double total) {
return total > 100 ? 10 : 0;
}
}红绿重构流程
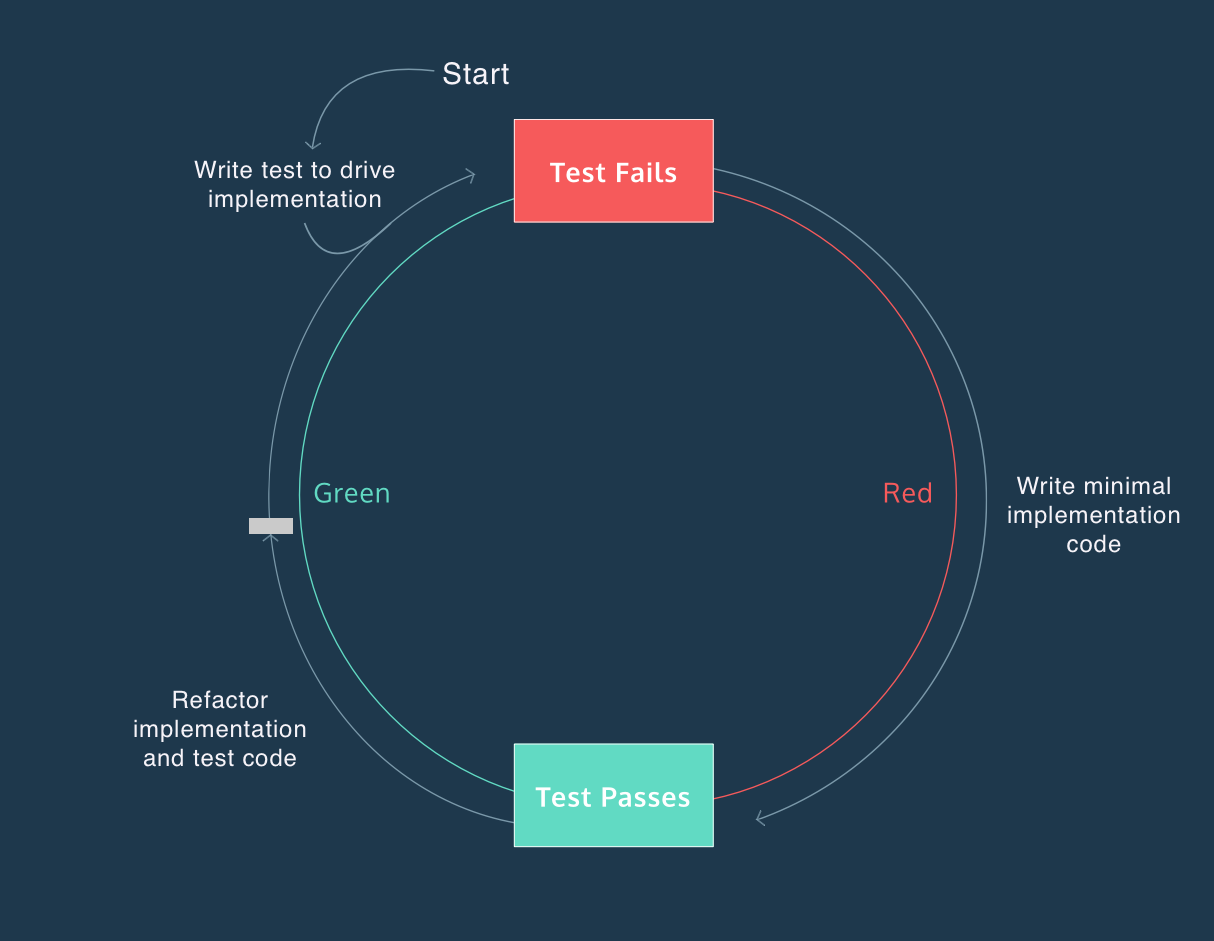
图片来源: Codecademy
红绿重构,又称测试驱动开发(TDD),是一种强调先编写测试再编写能通过这些测试的代码的代码重构技术。该技术是一个循环迭代的过程,每一轮迭代都包括编写新的测试和足够的代码来通过这些测试,最后对代码进行重构。
这一技术包括以下三个阶段:
- 红色阶段: 在这一阶段,你还未编写实际的代码。首先需要编写一组预期会失败的测试(标记为红色),因为还没有相应的实现来满足这些测试条件。
- 绿色阶段: 此阶段的目的是编写足够的代码来通过之前编写的未通过的测试,即让测试变绿。注意,此时的目标不是编写完美或高度优化的代码,而是简单地确保测试的通过。
- 重构阶段: 在确认代码已成功通过所有测试后,此时应着重于代码重构,以提升其性能和结构,而不改变其基本功能,确保测试仍然能够顺利通过。
每完成一个测试用例后,你将进入下一个循环,继续编写新的测试用例和对应的代码,然后再进行代码重构以实现更好的优化。
优化违反单一责任原则的代码
可能你已对面向对象编程中的 SOLID 原则有所了解。SOLID 是五个设计原则的首字母缩写。
- S:单一责任原则(Single Responsibility Principle),这个原则强调一个类应该仅有一个变化的原因,简言之,一个类应只负责一个功能点。
- O:开放封闭原则(Open Closed Principle),软件实体应该是可扩展的而不是可修改的。
- L:里氏替换原则(Liskov Substitution Principle),对象应该能够被其子类型所替换,而不影响程序的正确性。
- I:接口隔离原则(Interface Segregation Principle),客户端不应被强迫依赖于它们不用的接口。
- D:依赖倒置原则(Dependency Inversion Principle),高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
单一责任原则是首要原则,该原则强调每个类应仅有一个变化的原因,即一个类只负责一个功能点遵守单一责任原则是确保代码可维护、可读、灵活和模块化的基本方式之一。下面我们将展示一个 OrderProcessor 类的示例,这个类违反了单一责任原则,因为它同时承担了订单处理和记录信息日志两项职责。
重构前
public class OrderProcessor {
// 处理订单
public void processOrder(Order order) {
// 订单验证
// 处理逻辑
// 日志记录
Logger logger = new Logger();
logger.log("Order processed: " + order.getId());
}
}为了遵循单一责任原则,我们可以将该类重构为三个类:一个是 OrderProcessor 类,只负责订单处理;OrderValidator负责订单校验,另外一个是 OrderLogger 类,专门负责日志记录。
重构后
public class OrderProcessor {
private final OrderValidator orderValidator;
public OrderProcessor(OrderValidator orderValidator) {
this.orderValidator = orderValidator;
}
// 处理订单
public void processOrder(Order order) {
// 订单验证
if(!orderValidator.validate(order)) {
throw new IllegalArgumentException("Order is not valid");
}
// 处理逻辑
// ...
// 日志记录
OrderLogger logger = new OrderLogger();
logger.logOrderProcessed(order);
}
}
public class OrderValidator {
// 订单验证
public boolean validate(Order order) {
// 验证逻辑
// ...
return true;
}
}
public class OrderLogger {
public void logOrderProcessed(Order order) {
Logger logger = new Logger();
logger.log("Order processed: " + order.getId());
}
}Java 代码重构的 14 条最佳实践
代码重构是一个能够显著提升代码质量的重要步骤,它带来了我们之前强调的诸多好处。但在进行重构时也需谨慎,特别是在处理庞大的代码库或不熟悉的代码库时,以避免无意中改变软件的功能或产生未预见的问题。
为了避免任何潜在问题,您可以参考以下重构 Java 代码的技巧和最佳实践:
- 保持功能不变: Java 代码重构的首要目标是提高代码质量。然而,程序的外部行为,如它如何响应输入和输出以及其他用户交互应该保持不变。
- 充分理解代码: 在开始重构某个代码片段之前,请确保你充分理解你即将重构的代码。这包括其功能、交互和依赖关系。这种理解将指导你的决策,并帮助你避免做出可能影响代码功能的更改。
- 将 Java 重构过程分解为小步骤: 重构大型软件,尤其是当你对它还不够了解时,可能会令人感到不知所措。然而,通过将重构过程分解为更小、易于管理的步骤,你可以使工作负担更轻,减少错误的风险,并容易持续验证你的更改。
- 使用版本控制创建备份: 由于重构涉及对代码库进行更改,有可能事情不会按计划进行。在一个单独的分支上备份你的工作软件是一个好主意,以避免在找不出是哪些更改破坏了你的软件时浪费大量时间和资源。像 Git 这样的版本控制系统允许你同时管理不同的软件版本。
- 频繁测试你的更改: 在重构代码时你最不想做的就是不小心破坏程序的功能或引入影响软件的错误。在进行任何重大的代码更改之前,尤其是重构,建立一套测试集是提供安全网的好方法。这些测试验证你的代码行为是否符合预期,以及现有的功能是否保持完整。
- 利用重构工具: 有了像 Eclipse 和 IntelliJ 这样的现代 IDE,Java 代码重构不必是一个紧张的过程。例如,IntelliJ IDEA 包括一套强大的重构功能。一些功能包括安全删除,提取方法/参数/字段/变量,内联重构,复制/移动等。这些功能使你的工作更轻松,减少了你在重构过程中引入错误的机会。
- 深入理解代码变更:在重构过程中,深入了解你所做的代码变更是非常重要的,它可以帮助你快速识别和解决可能出现的问题。
- 充分利用单元测试:作为开发者,我们需要确保在重构代码时不会破坏现有的应用程序或引入新的 bug。一个完善的单元测试套件可以帮助你检测回归问题,确保功能的完整性,同时也有利于团队合作和长期的代码维护。
- 持续跟踪性能变化并反馈:Java 代码重构不仅仅是为了改善代码结构,它还涉及到性能优化。通过持续监控性能指标,你可以确保你的重构工作正在取得实质性的进展。
- 进行同行代码审查:重构完成后,建议邀请另一名开发者来审查你的更改,他们可以从一个新的角度来发现可能被你忽视的问题,并提供有价值的反馈。
- 记录重构变更:当你与其他开发者一起工作时,记录你的重构变更非常重要,因为这样可以提高透明度和协作效率,同时也有助于新员工更快地了解项目。
- 进行回归测试:完成重构后,需要通过回归测试来确保所有现有的功能都得到了保留,并且新引入的逻辑没有与现有代码产生冲突。
- 保持团队同步:在多人开发团队中工作时,及时通报你的重构变更非常必要,这可以避免冲突并帮助团队更好地适应新的变更。
- 在必要时执行回滚:如果重构过程中遇到无法解决的问题,不要犹豫,立即回滚到一个稳定的状态,以避免浪费更多的时间和资源。
结论
重构是一项至关重要的技术实践,它是确保软件项目长期成功的关键。 通过融入我们之前讨论的技术到你的开发周期并严格遵循最佳实践,你可以把任何复杂且混乱的代码库改造为一个可读、可维护和可扩展的软件解决方案。但请注意,Java 代码重构不是一次性的任务,而是一个可以持续整合到你的开发周期中的过程。
常见问题解答
应该何时重构我的 Java 代码?
在软件开发的任何阶段都可以进行代码重构。无论是在添加新功能、修复 bug 还是优化难以理解的代码片段时,都是进行重构的好时机。定期预留时间来进行重构可以避免技术债务的累积,从而维持代码库的高质量。
如何决定哪些代码需要重构?
你可以从识别代码库中难以理解、存在重复逻辑或容易产生 bug 的区域开始。寻找具有冗长的方法、复杂条件语句的代码,并尝试遵循“单一职责原则”来提高代码的组织性。
如何确保重构不会引入 bug?
拥有一套完善的自动化测试套件是减少重构过程中引入 bug 的风险的关键。在开始重构之前,确保你的代码具有良好的测试覆盖率,这将帮助你捕捉任何可能的回归问题,确保代码功能的稳定性。
如何在 Java 中重构类?
首先,你需要确定目标类并深入理解其行为和依赖关系。然后可以考虑拆分庞大的方法和将方法移动到更适合的类中,同时利用继承和接口来实现更清晰的结构。此外,重命名变量和方法、重新组织代码结构和简化条件语句都可以提高代码的可读性。最后,确保对所有更改进行彻底测试,以保证功能的完整性。
最后,推荐一款低代码开发工具
Jnpf是一个快速开发应用的平台,基于Java/.Net开发,专注低代码开发,旨在提供可视化的界面设计和逻辑编排,大幅降低开发门槛。它预置大量开箱即用的功能,可以满足按需定制灵活拼装。稳定强大的集成能力,一次设计,完成多端适配。Jnpf提供了一个用户友好的开放接口,可以轻松地与各种构建工具和IDE集成。还支持插件和自定义规则,使得开发人员可以根据项目的特定需求和标准对其进行定制化配置。更多详细信息可以查看jnpf官方文档。
通过它,编码薄弱的IT人士也能自己搭建个性化的管理应用,降低技术门槛。开发者仅需少量代码或无需代码就可以开发出各类应用管理系统,由于多数采用组件和封装的接口进行开发,使得开发效率大幅提升。
如何你也对使用JNPF感兴趣,可以通过http://www.jnpfsoft.com/?csdn快速试用。















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









