






#学习记录
一、需求分析
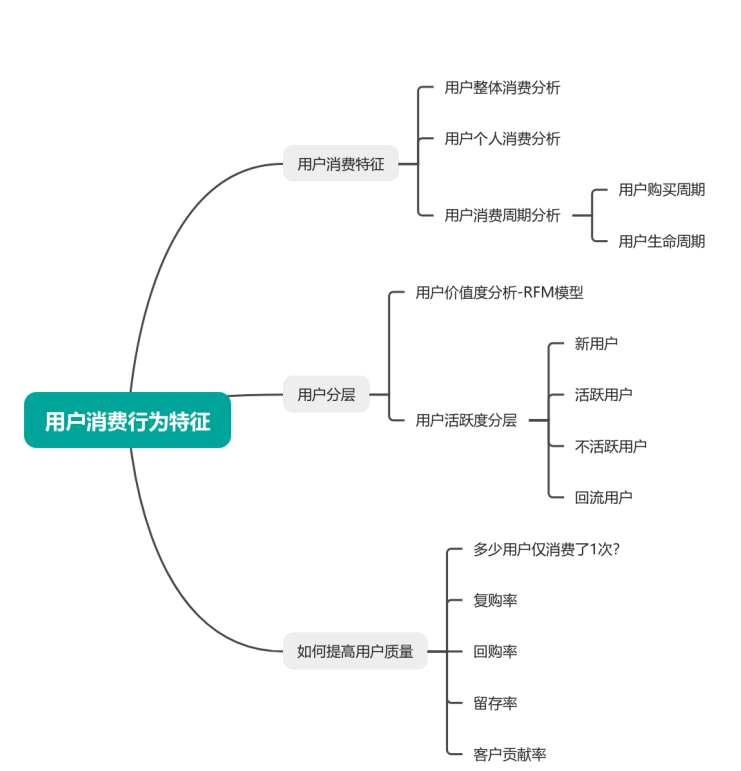
二、项目案例
1、用户个体消费分析
先看原数据,省的跑题
按照用户进行分组,分别统计销售数量、销售金额
#用户个体消费分析
#1、用户消费金额 按用户进行分组汇总销售数量、销售金额
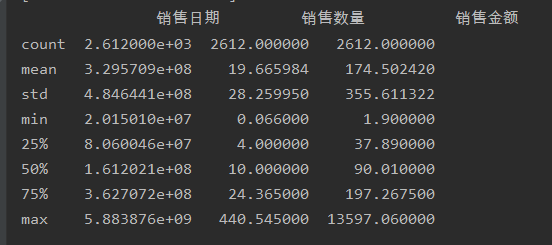
user_groupby=df3.groupby(by='顾客编号').sum()观察按用户进行分组之后,使用user_groupby.describe()数据集大致的情况
用户购买数量角度:数量均值19.6、标准差28.2、中位数10,均值>中位数,呈右态分布,可以推断出用户购买数量的区间在10-19个之间
消费金额角度:消费金额的均值174.5、标准差355.6、中位数90,均值>中位数,大致推断,汇总后的数据偏右边分布,用户消费金额区间在100-190元之间,看75%分布值,才与均值相近,可以推断出,存在个别土豪
看用户的产品的购买数量与消费金额的散点图
#可视化每个用户订单的产品的购买数量与消费金额的散点图
df3.plot(kind='scatter',x='销售数量',y='销售金额')
plt.tight_layout()
plt.show()从散点图中可以看出,每个用户订单消费商品单价是小于10元 ,且没有呈现线性分布的,可能存在商品单价分层严重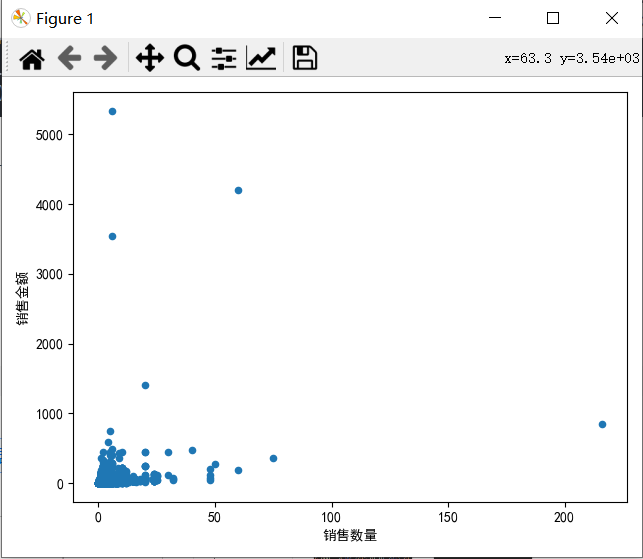
消费金额分布分析
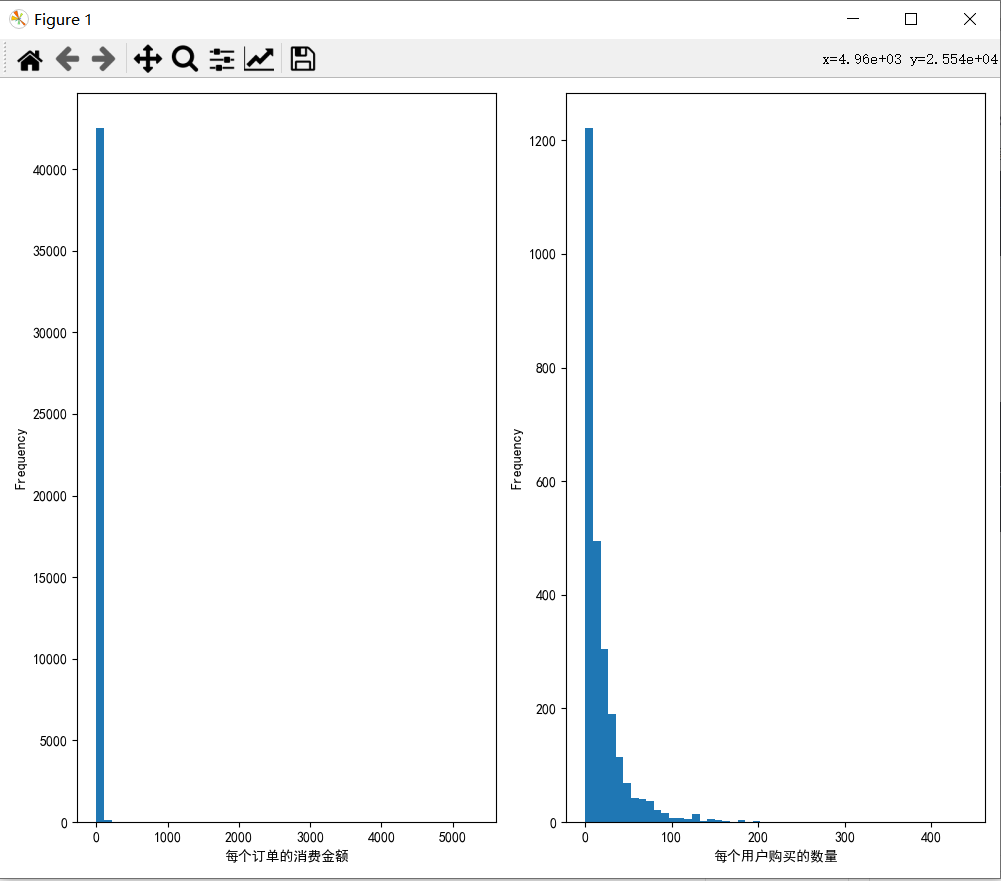
每个订单的消费金额
#每个订单的消费金额
plt.subplot(121)#一行两列
df3['销售金额'].plot(kind='hist',bins=50)#bins:区间分数,影响柱子的额宽度,值越大,柱子越细
plt.xlabel('每个订单的消费金额')每个用户购买的数量
#每个用户购买的数量
plt.subplot(122)#一行两列
df3.groupby(by='顾客编号')['销售数量'].sum().plot(kind='hist',bins=50)#bins:区间分数,影响柱子的额宽度,值越大,柱子越细
plt.xlabel('每个用户购买的数量')看图可以分析出来,每个订单的消费金额都在百元以内,每个用户购买商品的数量在10个左右
用户消费的贡献度分析
按照用户进行分组,将用户使用ABC分成三类,看用户对消费金额的贡献度
#2、用户累计消费金额占比分析(用户的贡献度)
#总销售金额
total_sales = df3['销售金额'].sum()
user_cumsum=df3.groupby(by='顾客编号')['销售金额'].sum().sort_values(ascending=False).reset_index()
# 计算累计金额
user_cumsum['累计销售金额'] = user_cumsum['销售金额'].cumsum()
# 计算累计百分比(添加微小值避免浮点数精度问题) 产品销售金额由高到底进行排序
user_cumsum['累计占比'] = (user_cumsum['累计销售金额'] / total_sales) * 100
#将用户进行ABC分类分析
# 处理特殊情况:如果所有销售金额为0,所有产品归为C类
if total_sales == 0:
user_cumsum['分类'] = 'C'
else:
# 使用更宽的区间边界避免边界值问题
user_cumsum['分类'] = pd.cut(
user_cumsum['累计占比'],
bins=[-0.001, 80, 95, 100.001], # 扩展边界处理浮点数精度问题
labels=['A', 'B', 'C'],
include_lowest=True
)
# 计算各类别的顾客消费次数和销售金额占比
category_summary = user_cumsum.groupby('分类').agg(
顾客个数=('顾客编号', 'count'),
总销售金额=('销售金额', 'sum')
).reset_index()
if not category_summary.empty:
category_summary['顾客个数占比%'] = (
category_summary['顾客个数'] / category_summary['顾客个数'].sum() * 100
).round(2)
category_summary['销售金额占比%'] = (
category_summary['总销售金额'] / category_summary['总销售金额'].sum() * 100
).round(2)
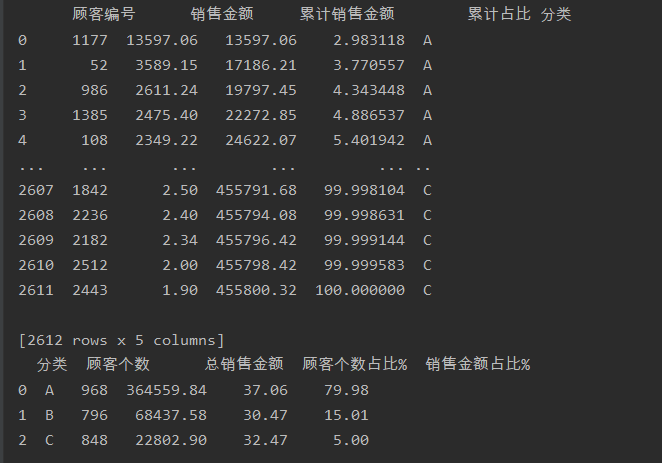
print(user_cumsum)
按照A类前80%,B类前95%,C类100%的销售金额 占比来看,顾客个数的分布均衡,可以看出A类客户存在消费价值高的客户
可视化
#获取分类之后前10名的妇科编码
top10=user_cumsum.groupby('分类').head(10).reset_index()
# 创建画布
fig, ax = plt.subplots(figsize=(12, 6))
# 获取各类别的数据
a_products = top10[top10['分类'] == 'A']
b_products = top10[top10['分类'] == 'B']
c_products = top10[top10['分类'] == 'C']
# 绘制柱状图
x = np.arange(len(top10))
ax.bar(x[a_products.index], a_products['销售金额'], color=['g'], label='A类')
ax.bar(x[b_products.index], b_products['销售金额'], color=['b'], label='B类')
ax.bar(x[c_products.index], c_products['销售金额'], color=['y'], label='C类')
# 在柱状图上方添加数值标签
for i, v in enumerate(top10['销售金额']):
ax.text(i, v + 2, f'{v:,.0f}', ha='center', fontsize=8)
# 添加标题和标签
ax.set_title('顾客销售金额ABC分类前10')
ax.set_xlabel('顾客排名(按销售金额降序)')
ax.set_ylabel('销售金额(元)')
ax.set_xticks(x[::2]) # 每隔两个产品显示一个标签
ax.set_xticklabels(top10['顾客编号'][::2])
ax.legend()
plt.xticks(rotation=45)
# 添加累计百分比曲线
ax2 = ax.twinx()
ax2.plot(x, top10['累计占比'] , 'p-', linewidth=2, label='累计占比(%)')
# 在折线图上方添加数值标签
ax2.set_ylabel('累计销售占比(%)')
# 在折线上添加数值标签(只在关键转折点显示)
for a, b in enumerate(top10['累计占比']):
ax2.text(a, b + 2, f'{b :,.0f}', ha='center', fontsize=8)
plt.tight_layout()
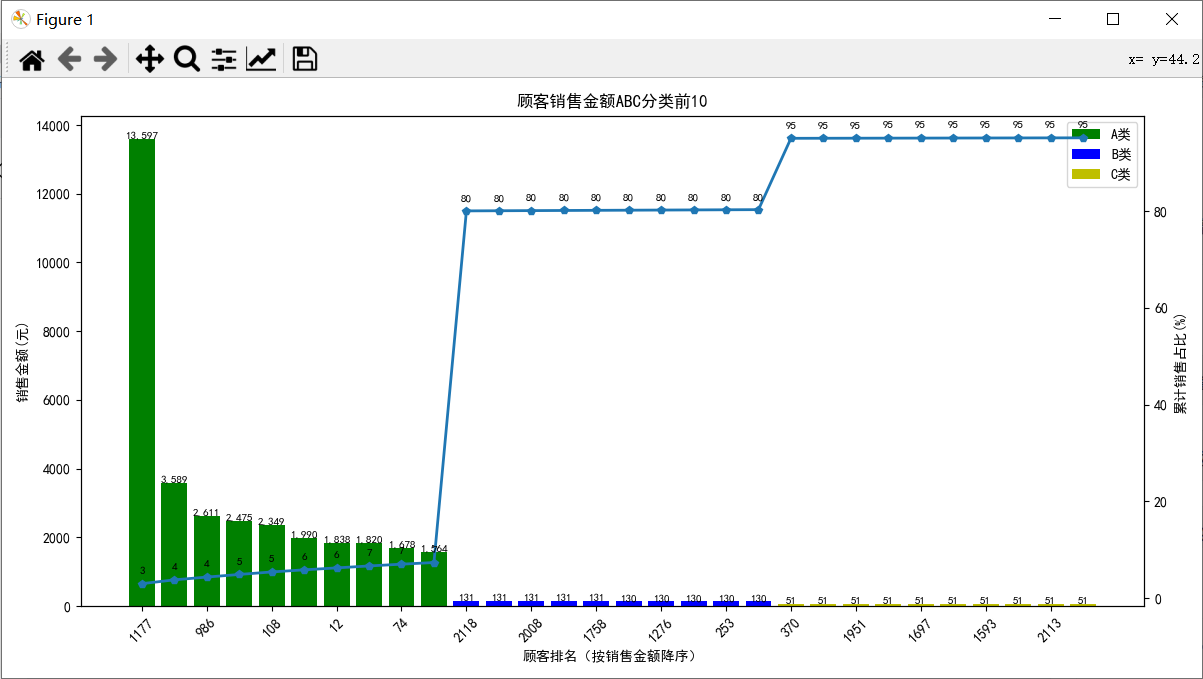
plt.show()由图可以看出A类前10名用户,消费金额都在1500以上,可以针对此类价值高的用户加以维护,而B类与C类客户的整体的消费金额较低,趋向日用产品的购买


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









