






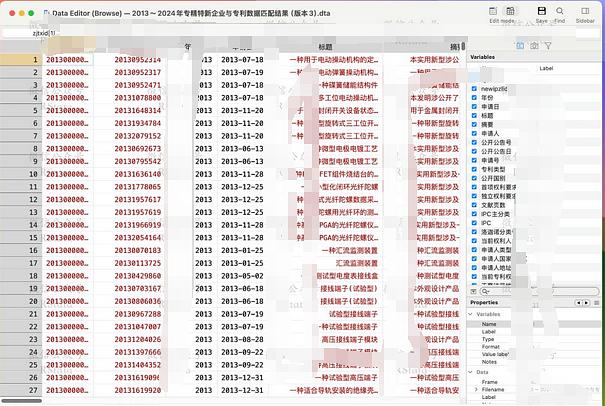
前不久给大家分享了专利数据和专精特新数据,今天再给大家分享一份专精特新企业与专利数据的匹配结果。因为数据较大,所以我特意将匹配结果分拆成分年版本,时间范围为 2013~2024 年。数据格式方面,我提供的是供 Stata 读取的 dta 格式。数据概览如下:
统计数量的时候注意去除重复专利,详情可以阅读专利的介绍(文初的链接)。
匹配方法
结合专精特新企业数据与专利数据的变量,我首先使用专精特新数据中的企业名称与专利数据中的申请人进行匹配,然后再使用统一信用代码匹配(新版本的专利数据里面有这个变量,然后专精特新+工商注册信息里面也有这个变量)。
具体匹配方法分为四步:
- 专利数据中有个申请人变量,每个专利可能有多个申请人,申请人之间使用冒号分隔。因此需要首先处理申请人变量,处理思路如下:
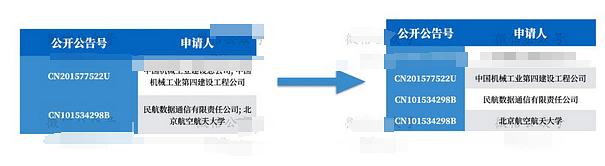
2.其次,对专精特新数据库里的企业名称和专利数据里的申请人变量进行处理,主要是改正错字和去除对匹配没有帮助的词汇(例如“有限公司”、“有限责任公司”)。为便于两个数据集的连接,我在专精特新数据中生成了 zjtxid 变量以在匹配过程中识别每个观测值。在之前的课程「Stata 中的中文模糊匹配——以 2014 年工企数据和境外投资名录数据匹配为例」中,我分享过使用 Stata 进行模糊匹配的方法,不过模糊匹配耗时耗力,并且错误率很高。不同于英文,中文企业名称只要有一个字不同都可能不是同一家企业(英文企业名称有一两个字母不同可能是因为笔误)。所以中文企业名称的模糊匹配没有意义。因此这里我还是使用了精确匹配,考虑到企业名称中经常会把“有限公司”和“有限责任公司”混用,以及有限公司改股份有限公司之类的。所以这里在匹配前删除了下面词汇:股份有限、集团有限、有限责任、有限、责任、股份、公司、厂、 、(集团)、(集团)、(、)、(、)、省、市、区、县、回族自治区、壮族自治区、维吾尔自治区、自治区。这样可以大大提高匹配成功率。
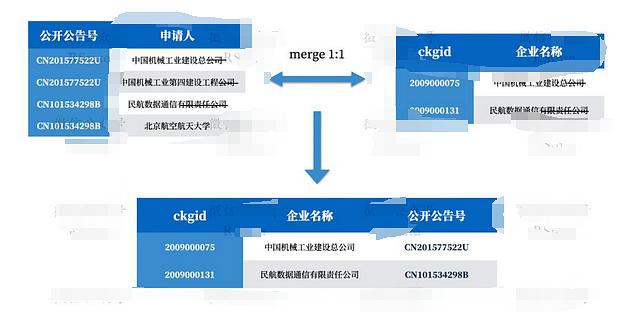
- 使用处理后的企业名称和申请人匹配。
- 使用统一社会信用代码匹配。这里其实也涉及到上述的拆分。
【下载→
方式一(推荐):主页↓个人↓简介
经管数据库-CSDN博客
方式二:数据下载地址汇总-CSDN博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









