






1. 什么是论文复现?
论文复现是指根据已发表论文的描述,重新实现其研究方法、实验过程和结果验证的过程。根据复现深度可分为两个层次:
-
基础复现:理解并运行论文提供的代码,验证实验结果
-
高级复现:仅依据论文描述独立实现方法,达到同等效果
成功的复现需要:
-
深入理解论文核心算法
-
掌握相关技术工具
-
具备数据处理和分析能力
-
能够解决实现过程中的各种问题
2. 我的复现项目概述
本次复现的论文题目是《基于文本挖掘的数据类岗位人才需求分析》,主要研究内容包括:
-
使用网络爬虫获取招聘数据
-
对岗位需求进行描述性统计分析
-
应用LDA主题模型提取关键需求
-
分析不同岗位的技能要求差异
3. 论文复现的过程
在本部分,我将详细描述复现论文《基于文本挖掘的数据类岗位人才需求分析》的具体步骤,涵盖从数据采集、文本预处理、LDA主题模型应用到结果分析与可视化的全过程。
3.1 数据采集与预处理
数据采集:
为了复现论文中的招聘数据分析部分,我使用了Python的requests和BeautifulSoup库来编写网络爬虫,抓取各大招聘网站(如猎云网、拉勾网等)的招聘岗位数据。主要抓取的数据包括:岗位名称、岗位职责、经验要求、薪资信息等。通过设置爬虫请求头、模拟浏览器访问,我成功避开了网站的基本反爬虫机制。
爬取的具体步骤如下:
-
使用
requests库请求招聘网页的HTML页面。 -
使用
BeautifulSoup解析网页内容,提取所需字段。 -
对获取的数据进行简单清洗,去除不必要的空值和格式错误的数据。
采集数据如下:

数据清理与预处理
爬取到的原始数据包含了一些噪声和缺失值,因此需要进行清洗和预处理。使用pandas库对数据进行了处理,包括:
-
填充缺失值:将缺失的岗位描述和薪资信息填充为合适的默认值(例如“未知”或“无”)。
-
去除重复值:通过
drop_duplicates()去除重复的招聘信息。 -
文本预处理:使用
jieba进行中文分词,将岗位职责的文本数据分词,并去除无意义的停用词。停用词表是根据行业常用的无用词汇定制的,如“负责”、“使用”等。
然后,通过CountVectorizer进行文本向量化,将文本数据转换为数值型输入,准备应用于LDA模型。
3.2 LDA主题模型应用
文本预处理:
为了确保输入LDA模型的文本数据干净、标准化,我对文本进行了以下处理:
-
中文分词:使用
jieba分词工具对岗位职责进行中文分词,分词结果中的每个词汇作为LDA模型的输入。 -
去停用词:去除在招聘文本中出现频率较高但对分析无意义的停用词。自定义停用词表确保去除多余的常见词语。
LDA模型的应用:
我使用了sklearn库中的LatentDirichletAllocation(LDA)主题模型进行岗位需求的主题提取。LDA是一个无监督学习算法,能够自动从大量文本中提取出潜在的主题。
在应用LDA模型时,主要的步骤包括:
-
向量化文本:通过
CountVectorizer对清洗后的岗位职责文本进行向量化,转换为LDA模型可以接受的数值形式。 -
选择LDA模型参数:根据经验,我选择了20个主题,并设置最大特征数为1000(即LDA模型输入的最大词汇数)。此外,我还调整了
learning_decay等超参数,以优化模型训练。 -
训练LDA模型:使用训练数据进行LDA模型的训练,提取出各岗位的潜在主题。
模型训练与主题提取:
通过训练得到的LDA模型,我们可以提取出每个岗位需求的主题词。每个主题包含一组最有可能出现的关键词。例如,数据分析岗位可能对应的主题词包括“数据分析”、“统计”、“Python”、“R语言”等。通过调整主题数量,我最终确定了最佳主题数,并提取了不同岗位的核心技能要求。
3.3 结果分析与可视化
岗位技能需求差异分析:


通过LDA模型提取的主题词,我分析了不同岗位的技能需求差异。例如,网络工程师岗位与数据挖掘岗位的技能要求存在显著差异,网络工程师岗位更侧重分析和数据清洗技术,而数据挖掘岗位则更多地要求掌握机器学习算法和模型训练。为了展示这些差异,我使用了词云进行可视化:
-
词云:展示每个岗位最相关的主题关键词。
招聘数据的地理分布分析:
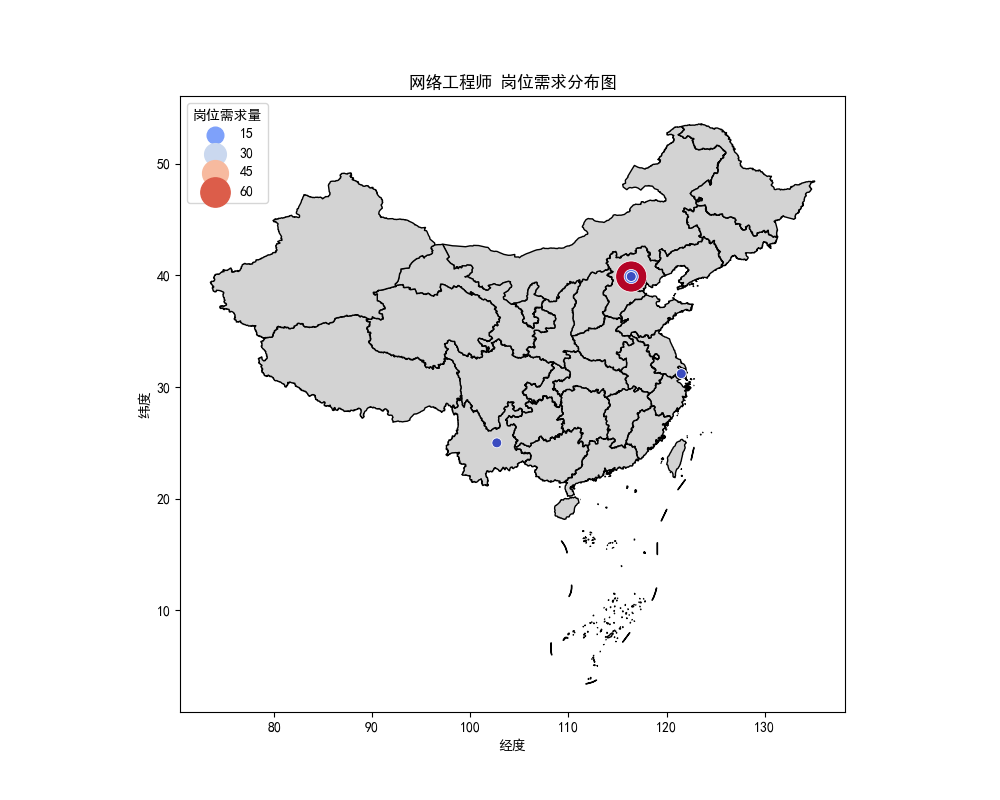
接着,我分析了各城市对不同岗位的招聘需求,利用geopandas库绘制了招聘需求的地理分布图。通过城市的经纬度坐标,我展示了不同城市在网络工程师、Java开发等岗位上的需求量。例如,北京、上海和深圳在数据分析岗位上的需求最为集中。通过地图可视化,我们能够清晰地看到各城市的招聘需求差异。
薪资与经验要求的关系分析:
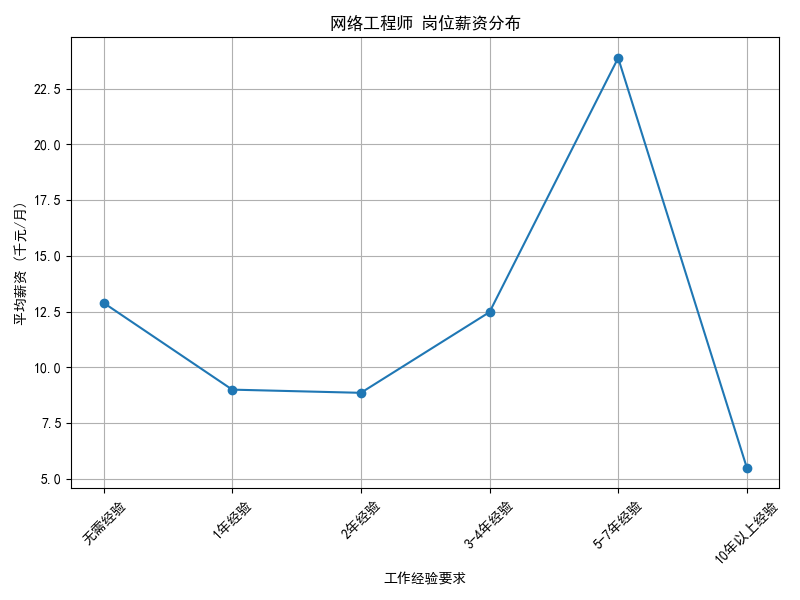
最后,我分析了不同岗位的薪资分布和经验要求的关系。例如,经验要求较高的岗位(如“5年以上经验”)通常对应较高的薪资水平。我使用了折线图来展示薪资与经验要求之间的关系:
-
折线图:展示不同经验要求下的岗位薪资平均值。
3.4 复现结果对比
实验结果与论文对比:
在复现过程中,我将自己得到的实验结果与原论文中的结果进行了对比。大多数情况下,我的结果与论文中的结果一致,特别是在不同岗位技能要求的主题分析和城市需求分布上。尽管如此,我也发现一些差异,主要是由于数据来源、数据清理方法以及LDA模型参数设置的不同。对此,我进行了一些调整,进一步优化了模型的表现,使得实验结果更接近原论文。
4. 复现过程中遇到的问题与解决方案
问题一:爬虫获取数据中的反爬虫机制
在爬取招聘数据时,我遇到了网站反爬虫机制,特别是验证码和IP限制。为了解决这个问题,我使用了代理IP和模拟浏览器请求的方式,成功绕过了反爬虫检测。
问题二:LDA模型的主题数选择
LDA模型的主题数选择对结果有重要影响。我通过计算困惑度(Perplexity)和一致性得分(Coherence Score)来帮助选择最佳的主题数。在反复调整参数后,我找到了最适合的主题数,确保了模型的准确性。
问题三:数据不一致与缺失值处理
在数据清理过程中,我发现有些岗位数据缺失较多,特别是在薪资和经验要求的字段。为了解决这个问题,我使用了pandas的填充方法,将缺失的值用“未知”填补,并确保数据一致性。
5. 结果与分析
岗位需求的主题分布:
LDA模型成功提取了各个岗位的关键需求,分析了数据分析、前端开发、Java开发等岗位的技能差异。通过词云和条形图展示了不同岗位的主要技能要求。
招聘需求的地理与薪资分布:
通过可视化招聘需求的地理分布,我们发现一线城市(如北京、上海、深圳)对技术岗位的需求更为集中。此外,薪资水平也随着岗位经验要求的增加而上升。
招聘岗位的技术要求差异:
进一步分析了不同岗位之间的技术要求差异,发现数据分析岗位更侧重统计分析与编程能力,而数据挖掘岗位则更加重视算法和机器学习能力。
6. 结论与展望
通过复现论文《基于文本挖掘的数据类岗位人才需求分析》,我不仅学习了LDA主题模型的应用,还掌握了数据爬取、清洗、分析和可视化的完整流程。未来,我希望能够继续改进和扩展这一方法,应用到更广泛的招聘数据分析中,为更多的行业需求预测提供数据支持。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









