









作者主页:paper jie_博客
本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。
本文录入于《JAVA数据结构》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造,将javaSE基础知识一网打尽,希望可以帮到读者们哦。
其他专栏:《算法详解》《C语言》《javaSE》等
内容分享:本期将会分享java数据结构中的二叉搜索树与Java集合中的Set和Map
目录
什么是搜索树
搜索树又名二叉搜索树,它是一颗完全二叉树,且:
左树不为空的话,则左子树上的所有节点的值都小于根节点的值
右树不为空的话,则右子树上的所有节点的值都大于根节点的值
它的左右子树也是搜索树

搜索树的模拟实现
查找功能
实现这个功能就可以利用它的性质,比根节点的小的数在左边,比根节点大的数在右边,通过遍历的方式一直查找,要是遇到了null,代表就没有这个数。
代码实现
//查找元素
//查找复杂度:O(logN)
//最坏情况:O(N)
public boolean search(int node) {
if(root == null) {
return false;
}
TreeNode cur = root;
while(cur != null) {
if(node < cur.val) {
cur = cur.left;
}else if(node > cur.val) {
cur = cur.right;
}else {
return true;
}
}
return false;
}画图分析

新增功能
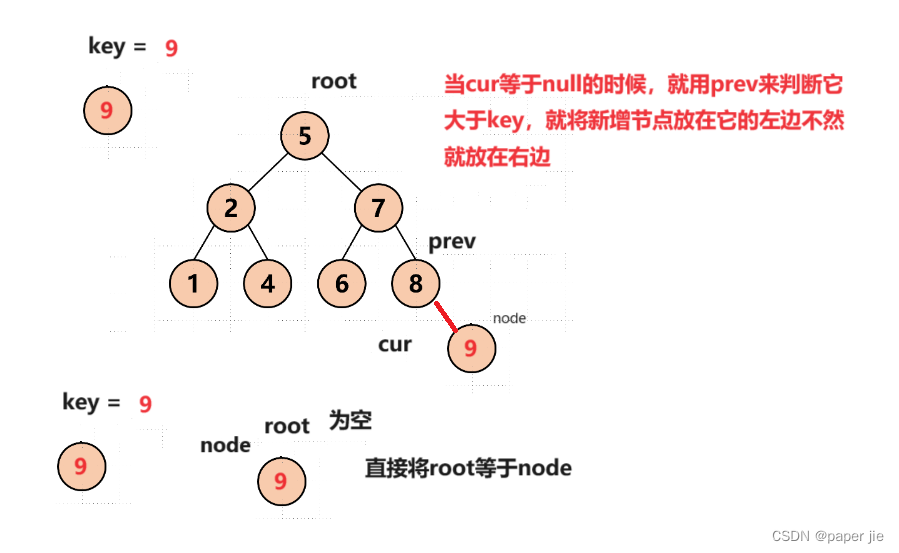
新增节点,我们就分两种情况,一种没有节点,一种有节点,但大致开始用cur遍历找到需要插入的位置,再用一个prev记住cur的前一个节点。且相同是不需要添加的。当cur等于null的时候,就用prev来判断它大于key,就将新增节点放在它的左边不然就放在右边
具体代码
//新增元素
public boolean push(int node) {
if(root == null) {
root = new TreeNode(node);
return true;
}
TreeNode cur = root;
TreeNode prve = null;
while(cur != null) {
if(node < cur.val) {
prve = cur;
cur = cur.left;
}else if(node > cur.val){
prve = cur;
cur = cur.right;
}else {
return false;
}
}
TreeNode treeNode = new TreeNode(node);
if(prve.val > node) {
prve.left = treeNode;
}else {
prve.right = treeNode;
}
return true;
}画图分析
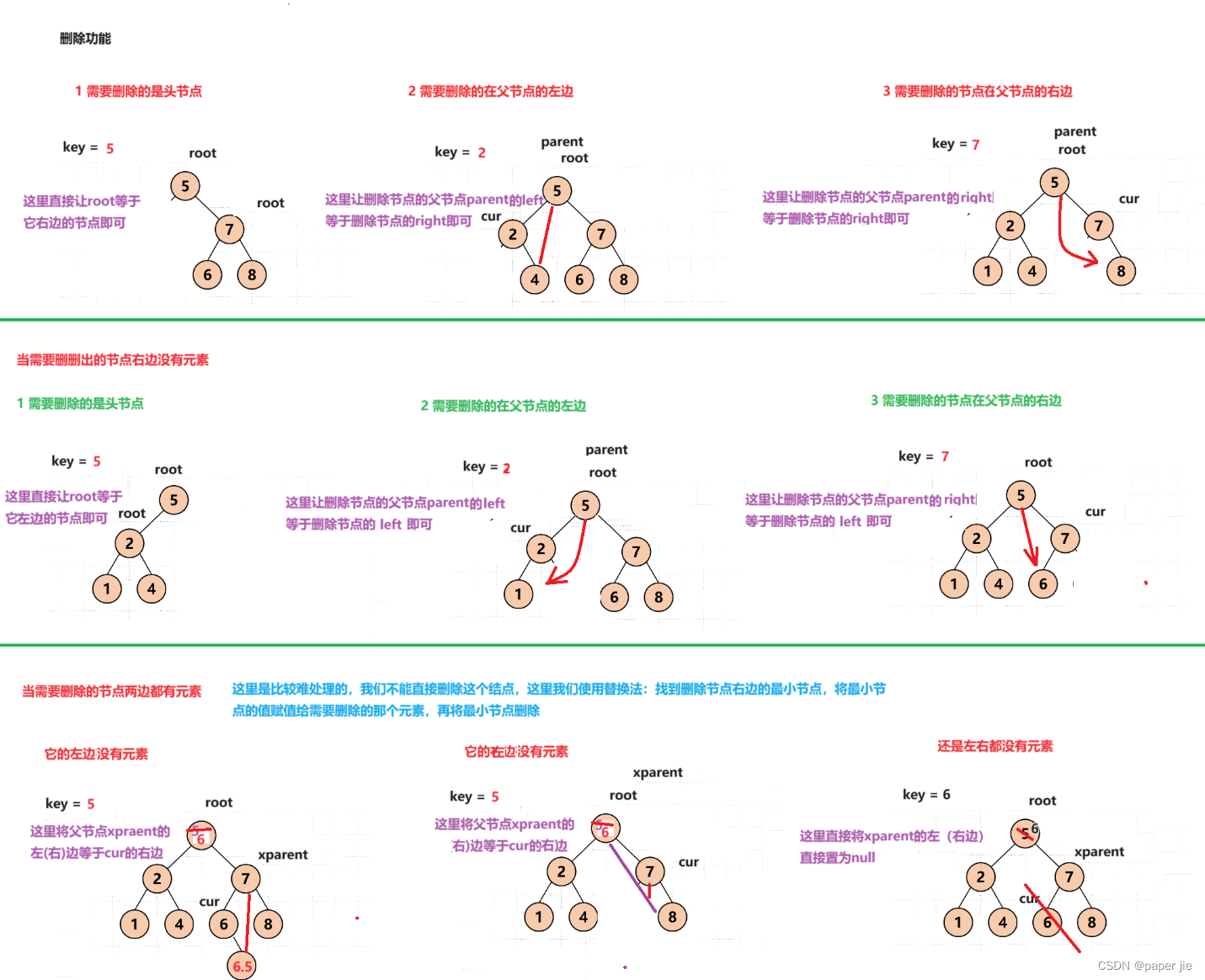
删除功能
删除就比较复杂一点,得分几种情况,而这几种情况中又得细分:
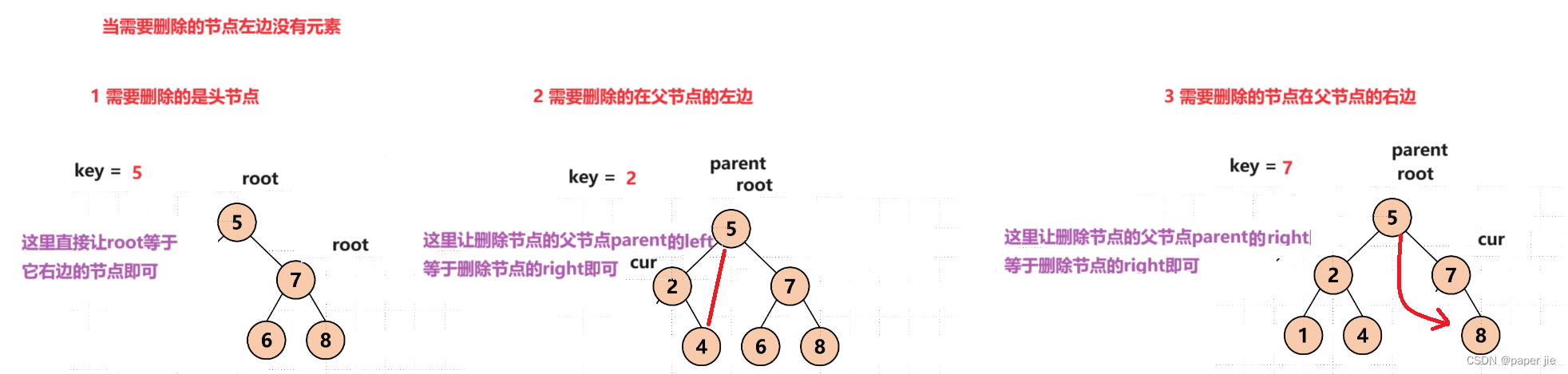
当需要删除的节点左边没有元素
1 需要删除的是头节点
2 需要删除的在父节点的左边
3 需要删除的节点在父节点的右边
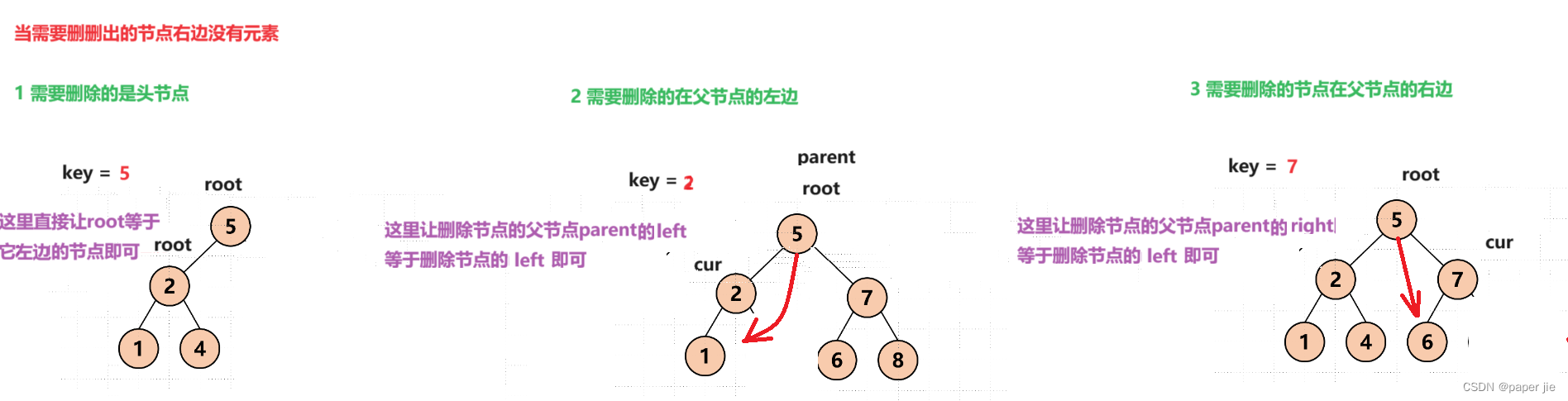
当需要删删出的节点右边没有元素
1 需要删除的是头节点
2 需要删除的在父节点的左边
3 需要删除的节点在父节点的右边
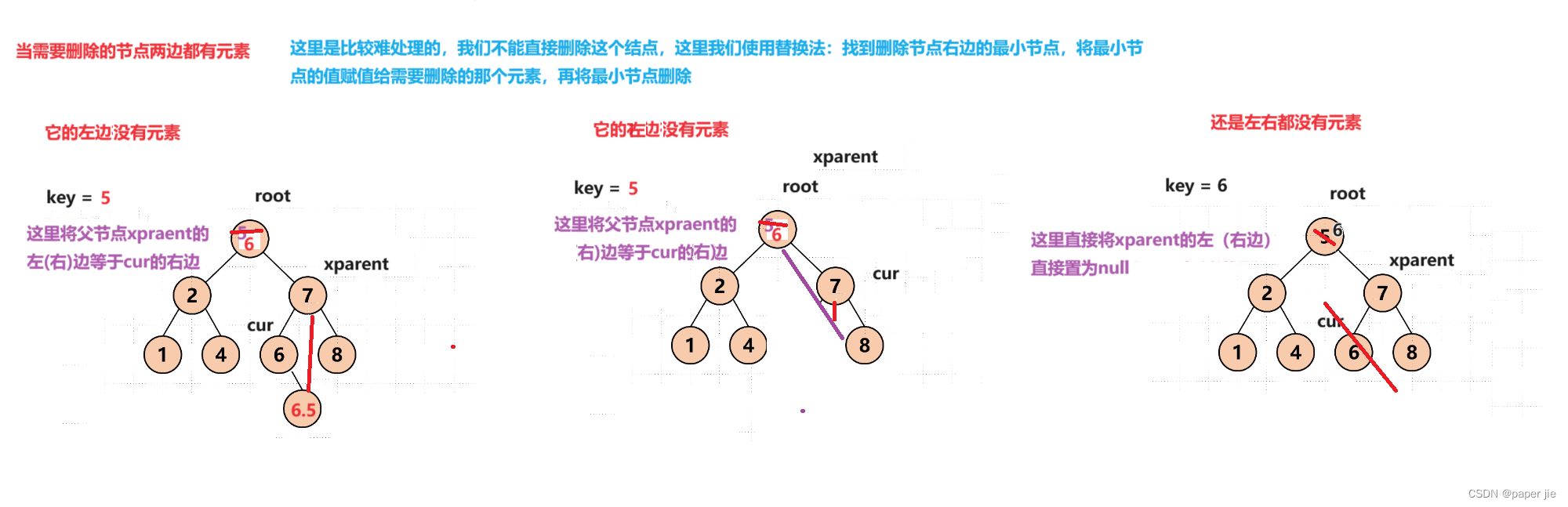
当需要删除的节点两边都有元素
这里是比较难处理的,我们不能直接删除这个结点,这里我们使用替换法:找到删除节点右边的最小节点,将最小节点的值赋值给需要删除的那个元素,再将最小节点删除,在删除这个最小节点的时候我们也要考虑:
它的左边有没有元素,它的右边有没有元素,还是左右都没有元素
具体代码
//删除元素
public boolean poll(int key) {
TreeNode cur = root;
TreeNode parent = null;
while(cur != null) {
if(key < cur.val) {
parent = cur;
cur = cur.left;
}else if(key > cur.val) {
parent = cur;
cur = cur.right;
}else {
removeNode(cur, parent);
return true;
}
}
return false;
}
private void removeNode(TreeNode cur, TreeNode parent) {
//删除节点左边为空
if(cur.left == null) {
if(cur == root) {
root = root.right;
}else if(parent.left == cur) {
parent.left = cur.right;
}else {
parent.right = cur.right;
}
//删除节点右边为空
}else if(cur.right == null) {
if(root == cur) {
root = root.left;
}else if(parent.left == cur) {
parent.left = cur.left;
}else {
parent.right = cur.left;
}
//都不为空
}else {
TreeNode xparent = cur;
TreeNode x = cur.right;
while(x.left != null) {
xparent = x;
x = x.left;
}
cur.val = x.val;
if(xparent.left == x) {
xparent.left = x.right;
}else {
xparent.right = x.right;
}
}
}
}
画图分析
搜索树的性能
这里我们可以把查找的效率看做整个搜索树的性能,因为不管是新增和删除都是需要查找的嘛。
对于搜索树,我们知道,它就是一颗二叉树,所以比较的次数就是树的深度。但是所有情况都是这样嘛,这里会因为一个数据集合,如果他们数据插入的次序不一样,则会得到不一样的数据结构,比如下图:
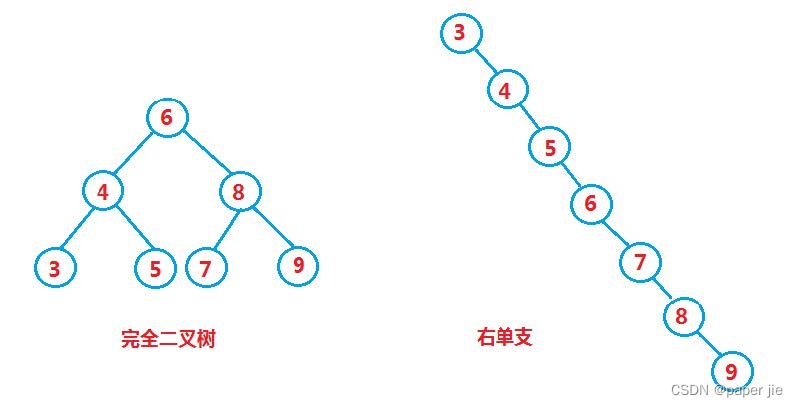
这里我们就知道了,在最坏情况下搜索树会退化成一个链表所以:
最好情况时间复杂度:O(logN)
最坏情况时间复杂度:O(N)
搜索树与Java类集合的关系
Java中的TreeMap和TreeSet就是利用搜索树实现的,但是呢它们底层使用的是搜索树的进化再进化版红黑树(搜索树 - LAV树 - 红黑树 ),LAV树就是对搜索树的改进,遇到链表情况下它就是翻转这个链表,让他变成一个高度平衡的搜索树,而红黑树是在这个基础加上颜色一节红黑树性质的验证进一步的提高了它的效率。
Set和Map
概念
Map和Set是一种专门用来进行搜索的容器或者数据结构,它的搜索效率和实现它们的子类有关。一般比较简单的搜索方式有:
直接遍历,复杂度为O(N),效率比较底下
二分查找,复杂度为O(logN),但它麻烦的是必须是有序的
而这些搜索方式只适合静态的搜索,但对于区间这种插入和删除的操作他们就不行了,这种就属于动态搜索方式。Map和Set就是用来针对这种的动态查找的集合容器
模型
这集合中,一般把搜索的数据称为关键字Key和关键字的对应值Value,这两个称为键值对,一般有两种模型:
纯Key模型,即只需要一个数据,比如:
查找手机里面有没有这个联系人
Key-Value模型,比如:
查找这个篇文章里面这个词出现了几次 (词,出现的次数)
Map就是Key-Value模型,Set是纯Key模型
Map接口下继承了HashMap和TreeMap两个类,而Set接口下继承了TreeSet和HashSet两个类
TreeMap和TreeSet底层是红黑树,而HashMap和HashSet底层是哈希表

Map
Map是一个接口,它没有和其他几个类一样继承Collection,它存储的是<K,V>键值对,且K是唯一·的,V可以重复
Map.Entry<K,V>
Map.Entry<K,V>在Map中是一个内存类, 它是用来Map内部实现存放<K,V>键值对映射关系的,它还提供了Key,value的设置和Key的比较方式:
| 方法 | 解释 |
| K getKey() | 返回Entry中的Key |
| K getValue() | 返回Entry中的Value |
| K setValue(V value) | 设置Entry中的value |
这里要注意它没有提供设置Key的方法
Map的常用方法

注意事项:
1 Map是一个接口,它不可以实例化对象,要实例化只能实例化它的子类TreeMap或者HashMap
2 Map中存放键值对里的Key是唯一的,value是可以重复的
3 在TreeMap中插入键值对时,Key不能为空,否则就会抛NullPointerExecption异常,value可以为空。但是HashMap的Key和value都可以为空
4 Map中的Key是可以分离出来的,存储到Set中来进行访问(因为Key不能重合)
5 Map中的value也可以分离出来,存放到Collection的任何一个子集合中,但是value可能会重合
6 Map中的键值对Key不能直接修改,value可以修改,如果要修改Key,只能先将Key先删除,再来插入
TreeMap和HashMap的比较
| Map底层结构 | TreeMap | HashMap |
| 底层结构 | 红黑树 | 哈希桶 |
| 时间复杂度 | O(logN) | O(1) |
| 是否有序 | 有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/添加的区别 | 需要进行数据间的比较 | 直接通过计算哈希函数来确定地址 |
| 应用场景 | 在需要有序的场景下 | 不关心是否有序,更需要效率的场景下 |
| 比较和重写 | Key必须是可以比较的,不可以为null | 自定义类型需要重写哈希Code方法和equals方法 |
使用栗子:
HashMap:
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("猪八戒", 500);
map.put("孙悟空", 550);
map.put("唐僧", 40);
map.put("沙和尚", 100);
map.put("白龙马", 300);
System.out.println(map.get("猪八戒"));
System.out.println(map.remove("八戒"));
System.out.println(map.get("猪八戒"));
Set<Map.Entry<String, Integer>> set = map.entrySet();
for(Map.Entry<String, Integer> entry : set) {
System.out.println(entry);
}
System.out.println(map.containsKey("猪八戒"));
}TreeMap:
public static void TestMap() {
Map<String, String> m = new TreeMap<>();
// put(key, value):插入key-value的键值对
// 如果key不存在,会将key-value的键值对插入到map中,返回null
m.put("林冲", "豹子头");
m.put("鲁智深", "花和尚");
m.put("武松", "行者");
m.put("宋江", "及时雨");
String str = m.put("李逵", "黑旋风");
System.out.println(m.size());
System.out.println(m);
// put(key,value): 注意key不能为空,但是value可以为空
// key如果为空,会抛出空指针异常
// m.put(null, "花名");
str = m.put("无名", null);
System.out.println(m.size());
// put(key, value):
// 如果key存在,会使用value替换原来key所对应的value,返回旧value
str = m.put("李逵", "铁牛");
// get(key): 返回key所对应的value
// 如果key存在,返回key所对应的value
// 如果key不存在,返回null
System.out.println(m.get("鲁智深"));
System.out.println(m.get("史进"));
//GetOrDefault(): 如果key存在,返回与key所对应的value,如果key不存在,返回一个默认值
System.out.println(m.getOrDefault("李逵", "铁牛"));
System.out.println(m.getOrDefault("史进", "九纹龙"));
System.out.println(m.size());
//containKey(key):检测key是否包含在Map中,时间复杂度:O(logN)
// 按照红黑树的性质来进行查找
// 找到返回true,否则返回false
System.out.println(m.containsKey("林冲"));
System.out.println(m.containsKey("史进"));
// containValue(value): 检测value是否包含在Map中,时间复杂度: O(N)
// 找到返回true,否则返回false
System.out.println(m.containsValue("豹子头"));
System.out.println(m.containsValue("九纹龙"));
// 打印所有的key
// keySet是将map中的key防止在Set中返回的
for (String s : m.keySet()) {
System.out.print(s + " ");
}
System.out.println();
// 打印所有的value
// values()是将map中的value放在collect的一个集合中返回的
for (String s : m.values()) {
System.out.print(s + " ");
}
System.out.println();
// 打印所有的键值对
// entrySet(): 将Map中的键值对放在Set中返回了
for (Map.Entry<String, String> entry : m.entrySet()) {
System.out.println(entry.getKey() + "--->" + entry.getValue());
}
System.out.println();
}Set
Set和Map的不同点就在于Set是继承于Collection接口类的,Set只存储了Key。
Set的常用方法

注意事项:
1 Set是继承Collection的一个接口
2 Set只存储Key,且要求Key是唯一的
3 TreeSet的底层是使用了Map来实现的,其使用Key与Object的一个默认对象作为键值对插入到Map中
4 Set的最大特点就是去重
5 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedSet,它是在HashSet上维护了一个双向链表来记入插入元素的次序
6 Set中的Key不能修改,如果要修改的话,呀先将原来的删除,再重新插入
7 TreeSeet中不能插入null的Key,但HashSet可以
TreeSet和HashMap的比较
| Set底层结构 | TreeSet | HashSet |
| 底层结构 | 红黑树 | 哈希桶 |
| 复杂度 | O(logN) | O(1) |
| 是否有序 | 有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 使用红黑树的性质来插入和删除的 | 使用哈希函数来计算插入和删除的地址 |
| 比较和重写 | Key必须可以比较,不能为null | 自定义类型需要重写equals方法和HashCode方法 |
| 应用场景 | 需要Key有序场景下 | 需要更高的时间性能 |
栗子:
public static void TestSet2(){
Set<String> s = new TreeSet<>();
// add(key): 如果key不存在,则插入,返回ture
// 如果key存在,返回false
boolean isIn = s.add("apple");
s.add("orange");
s.add("peach");
s.add("banana");
System.out.println(s.size());
System.out.println(s);
isIn = s.add("apple");
// add(key): key如果是空,抛出空指针异常
//s.add(null);
// contains(key): 如果key存在,返回true,否则返回false
System.out.println(s.contains("apple"));
System.out.println(s.contains("watermelen"));
// remove(key): key存在,删除成功返回true
// key不存在,删除失败返回false
// key为空,抛出空指针异常
s.remove("apple");
System.out.println(s);
s.remove("watermelen");
System.out.println(s);
Iterator<String> it = s.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println();
}这里文章中我们提到的HashMap和HashSet的底层 - 哈希桶,下一篇文章就会介绍,期待一下吧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











