







在内核中操作文件的函数与用户空间不同,需要使用内核空间专用的一套函数,主要有filp_open()、filp_close()、vfs_read()、vsf_write()、set_fs()、get_fs()等,上述函数在头文件linux/fs和asm/uaccess.h中声明。
1.内核空间中的文件结构
内核中对文件操作额文件结构struct file,是进行文件操作时经常使用的结构,结构的原型定义如下,其中的f_op是对文件进行操作的结构,f_pos为文件当前的指针为止:
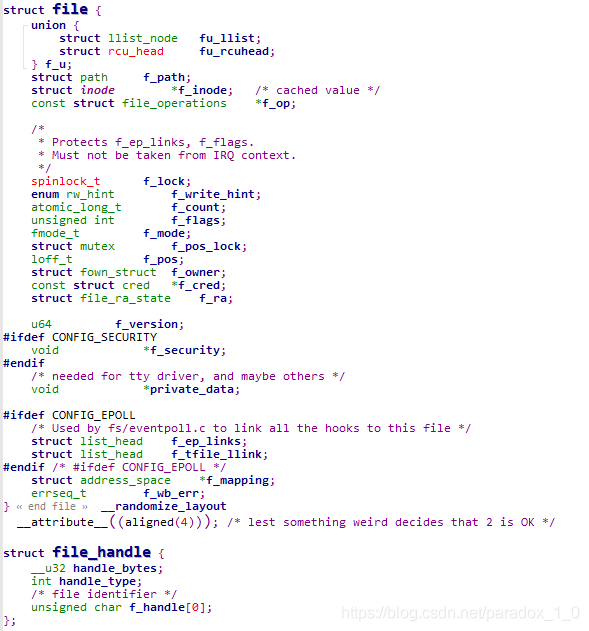
struct file_operations结构中定义的为一些内核文件操作的函数,结构的原型定义如下,例如其read()成员函数从文件中读取数据,write()成员函数向文件中写入数据。
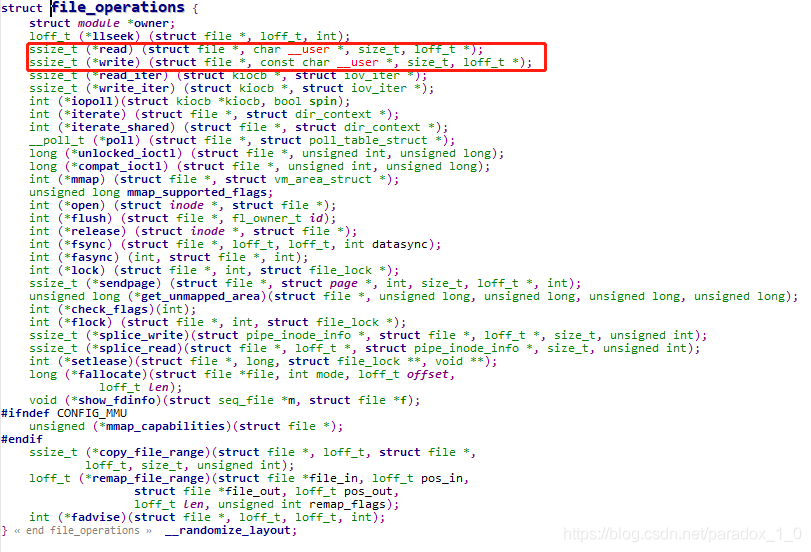
2.内核空间的文件建立操作
内核中打开文件不能调用用户空间的库函数,而且内核空间和用户空间打开文件的函数不同,内核空间打开文件的函数为filp_open()(注意不是file_open()),其原型如下:
struct file *filp_open(const char *filename, int flags, int mode); ![]()
filp_open用于打开路径filename下的文件,返回一个指向结构struct file的指针,后面的函数使用这个指针对文件进行操作,返回值需要使用IS_ERR()函数来检验其有效性。
参数说明如下:
- filename:要打开或者创建的文件名称,包含路劲部分。在内核中使用打开文件的函数容易出现打开文件时机不对的错误,例如当调用此函数时,文件驱动没有加载,或者打开的文件没有挂载到系统中。
- open_mode:设置文件的打开方式,这个值与用户空间的open对应的参数类似,可以取值O_CREAT、O_RDWR、O_RDONLY等值。
- mode:这个参数只有在创建文件的时候使用,用于设置创建文件的读写权限,不创建文件的其他情况可以忽略,设为0。
#define DBGPRINT printk
//内核程序使用file_open来打开文件
struct file *SIPFW_OpenFile(const char *filename, int flags, int mode)
{
struct file *f = NULL;
DBGPRINT("==>SIPFW_OpenFile\n");
/* */
f = filp_open(filename, flags, 0);
if (!f || IS_ERR(f))
{
f = NULL;
}
DBGPRINT("<==SIPFW_OpenFile\n");
return f;
}3.内核空间文件读写操作
Linux内核中对文件进行读写操作的函数为vfs_read()函数和vfs_write()函数,这两个函数的原型如下。函数的基本含义与用户空间是基本一致的。
//读文件
ssize_t vfs_read(struct file *filp, char __user *buffer, size_t len, loff_t *pos);
//写文件
ssize_t vfs_write(struct file *filp, const char __user *buffer, size_t len, loff_t *pos);这两个函数的参数含义如下所述。
- filp:文件指针,由filp_open()函数返回。
- buffer:缓冲区,从文件中读出的数据放到这个缓冲区,向文件中写入数据也在这个缓冲区。
- len:从文件中读出或者写入文件的数据长度。
- pos:为文件指针的位置,即从什么地方开始对文件数据进行操作。
注意:vfs_read()和vfs_write()这两个函数的第二个参数,在buffer前面都有一个__user修饰符,这要求buffer指针应该指向用户的空间地址。如果在内核中使用上述的两个函数直接进行文件操作,将内核空间的指针传入的时候,函数会返回失败EFAULT。但在Linux内核中,一般不容易生成用户空间的指针,或者不方便独立使用用户空间内存。为了使这两个函数能够正常工作,必须使得这两个函数能够处理内核空间的地址。
使用set_fs()函数可以指定上述两个函数对缓冲区地址的处理方式,原型如下:
void set_fs(mm_segment_t fs);这个函数改变内核对内存检查的处理方式,将内存地址的检查方式设置为用户指定的方式。参数fs取的值有两个:USER_DS和KERNEL_DS。分别代表用户空间和内核空间。
在默认情况下,内核对地址的检查方式为USER_DS,即按照用户空间进行地址检查并进行用户地址空间到内核地址空间的变换。如果函数中要使用内核地址空间,需要使用set_fs(KERNEL_DS)函数进行设置。与set_fs()函数对应,get_fs()函数获得当前的设置,在使用set_fs()之前先调用get_fs()函数获得之前的设置,对文件进行操作后,使用set_fs()函数还原之前的设置。
内核空间文件续写的框架为:
mm_segmen_t old_fs;
old_fs = get_fs();
set_fs(KERNEL_DS);
...
set_fs(old_fs)注意:使用vfs_read()和vfs_write()的时候,要注意最后的参数loff_t *pos,pos所指向的值必须要进行初始化,表明从文件的什么为止进行读写。使用此参数可以对续写文件的位置进行设定,这可以完成用户空间中lseek()函数的功能。
下面是一个使用内核空间的文件读函数从文件中读取数据的例子:
ssize_t ReadFile(struct file *filp, char __user *buffer, size_t len, loff_t *pos)
{
ssize_t count = 0;
oldfs = get_fs();
set_fs(KERNEL_DS);
count = file->f_op->read(filp, buf, len, &file->f_pos);
set_fs(oldfs);
return count;
}这里我想废一些话,因为是在下面的实例程序中遇到的问题:
查阅的文章连接:(http://blog.chinaunix.net/uid-15141543-id-2775960.html)

上面的代码实现很简单,在做了一些条件判断以后 ,如果该文件索引节点inode定义了文件的读实现方法的话,就调用此方法. Linux下特殊文件读往往是用此方法, 一些伪文件系统如:proc,sysfs等,读写文件也是用此方法 . 而如果没有定义此方法就会调用通用文件模型的读写方法(在下面的示例中就是碰到了没有定义此方法的情况,也就是说f->f_op->read == NULL, 所以最后直接调用了vfs_read方法进行了文件的读取操作).它最终就是读内存,或者需要从存储介质中去读数据.
4.内核空间的文件关闭操作
内核中的文件如果不在使用,需要将文件进行关闭,释放其中的资源。Linux内核中关闭文件的函数为filp_close(),其原型如下:
int filp_close(struct file *filp, fl_owner_t id);函数用于关闭之前打开的文件,函数的第一个参数为filp_open()返回的指针,第二个参数是POSIX线程ID。Linux内核中使用文件指针可以传入NULL,或者使用current->files传入当前模块额文件指针。
void CloseFile(void)
{
if (myfile)
filp_close(myfiles, current->files);
}5.实例
文件:

源码:
main_file.c
//kernel
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/types.h>
#include <linux/netdevice.h>
#include <linux/skbuff.h>
#include <linux/netfilter_ipv4.h>
#include <linux/inet.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/netlink.h>
#include <linux/spinlock.h>
#include <net/sock.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/icmp.h>
#include <linux/igmp.h>
#include <linux/ctype.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/proc_fs.h>
#include <linux/string.h>
#include <linux/vmalloc.h>
#include <asm/uaccess.h>
//user
#define DBGPRINT printk
//内核程序使用file_open来打开文件
struct file *SIPFW_OpenFile(const char *filename, int flags, int mode)
{
struct file *f = NULL;
DBGPRINT("==>SIPFW_OpenFile\n");
f = filp_open(filename, flags, 0);
if (!f || IS_ERR(f))
{
f = NULL;
}
DBGPRINT("<==SIPFW_OpenFile\n");
return f;
}
ssize_t SIPFW_ReadLine(struct file *f, char *buf, size_t len)
{
#define EOF (-1)
ssize_t count = -1;
mm_segment_t oldfs;
struct inode *inode;
//DBGPRINT("==>SIPFW_ReadLine\n");
if (!f || IS_ERR(f) || !buf || len <= 0)
{
goto out_error;
}
if (!f || !f->f_inode)
{
goto out_error;
}
inode = f->f_inode;
if (!(f->f_mode & FMODE_READ))
{
goto out_error;
}
if (f->f_op /*&& f->f_op->read*/)
{
oldfs = get_fs();
set_fs(KERNEL_DS);
count = 0;
if (vfs_read(f, buf, 1, &f->f_pos) <= 0)
{
DBGPRINT("file read failure\n");
goto out;
}
if (*buf == EOF)
{
DBGPRINT("file EOF\n");
goto out;
}
count = 1;
while (*buf != EOF && *buf != '\0' && *buf != '\n' && *buf != '\r'
&& count < len && f->f_pos <= inode->i_size)
{
buf += 1;
count += 1;
if (vfs_read(f, buf, 1, &f->f_pos) <= 0)
{
count -= 1;
break;
}
}
}
else
{
DBGPRINT("goto out_error\n");
goto out_error;
}
if (*buf == '\r'|| *buf =='\n' ||*buf == EOF )
{
*buf = '\0';
count -= 1;
}
else
{
buf += 1;
*buf = '\0';
}
out:
set_fs(oldfs);
out_error:
//DBGPRINT("<==SIPFW_ReadLine %d\n", count);
return count;
}
// ssize_t SIPFW_WriteLine(struct file *f, char *buf, size_t len)
// {
// ssize_t count = -1;
// mm_segment_t oldfs;
// struct inode *inode;
// DBGPRINT("==>SIPFW_WriteLine\n");
// if (!f || IS_ERR(f) || !buf || len <= 0)
// {
// goto out_error;
// }
// if (!f || !f->f_dentry || !f->f_dentry->d_inode)
// {
// goto out_error;
// }
// inode = f->f_dentry->d_inode;
// if (!(f->f_mode & FMODE_WRITE) || !(f->f_mode & FMODE_READ) )
// {
// goto out_error;
// }
// if (f->f_op && f->f_op->read && f->f_op->write)
// {
// //f->f_pos = f->f_count;
// oldfs = get_fs();
// set_fs(KERNEL_DS);
// count = 0;
// count = f->f_op->write(f, buf, len, &f->f_pos) ;
// if (count == -1)
// {
// goto out;
// }
// }
// else
// {
// goto out_error;
// }
// out:
// set_fs(oldfs);
// out_error:
// DBGPRINT("<==SIPFW_WriteLine\n");
// return count;
// }
void SIPFW_CloseFile(struct file *f)
{
DBGPRINT("==>SIPFW_CloseFile\n");
if(!f)
return;
filp_close(f, current->files);
DBGPRINT("<==SIPFW_CloseFile\n");
}
int SIPFW_HandleConf(void)
{
int retval = 0,count;
int l = 0;
char *pos = NULL;
struct file *f = NULL;
char line[256] = { 0 };
DBGPRINT("==>SIPFW_HandleConf\n");
// 提前建一个/etc/sipfw.conf文件吧
f = SIPFW_OpenFile("/etc/sipfw.conf", O_RDWR, 0);
if(f == NULL)
{
retval = -1;
DBGPRINT("SIPFW_OpenFile called failure\n");
goto EXITSIPFW_HandleConf;
}
while((count = SIPFW_ReadLine(f, line, 256)) > 0)
{
pos = line;
DBGPRINT("line = %d, data: %s\n", l, line);\
l++;
memset(line, 0, sizeof(line));
}
SIPFW_CloseFile(f);
EXITSIPFW_HandleConf:
DBGPRINT("<==SIPFW_HandleConf\n");
return retval;
}
static int __init SIPFW_Init(void)
{
int ret = -1;
DBGPRINT("==>SIPFW_Init\n");
ret = SIPFW_HandleConf();
DBGPRINT("<==SIPFW_Init\n");
return ret;
}
static void __exit SIPFW_Exit(void)
{
DBGPRINT("==>SIPFW_Exit\n");
DBGPRINT("<==SIPFW_Exit\n");
}
module_init(SIPFW_Init);
module_exit(SIPFW_Exit);
MODULE_LICENSE("GPL/BSD");
Makefile:
MODULE_NAME :=main_file
obj-m :=$(MODULE_NAME).o
KERNELDIR = /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean测试中读取的文件:(/etc/sipfw.conf)

运行:
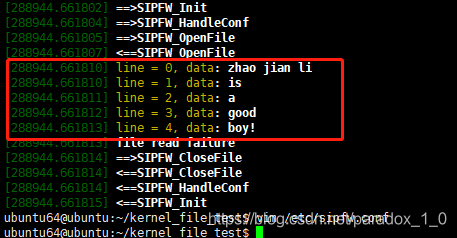
注:此项目运行环境:

ok!希望有帮助!















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









