







总概
本篇文章提出了三点:
1、propose一个two-stream卷积神经网络框架,时间流和空间流。
2、表明提出的光流神经网络在action recognition上有较好的结果。
3、multi-task learning,用于data argument。
所有的训练和评估bendmark:UCF101和HMDB-51。
设计成two-stream的原因:
Video can naturally be decomposed into spatial and temporal components. The spatial part, in the form of individual frame appearance, carries information about scenes and objects depicted in the video. The te mporal part, in the form of motion across the frames, conveys the movement of the observer (the camera) and the objects.
Two-stream Deep Convolutional Networks:
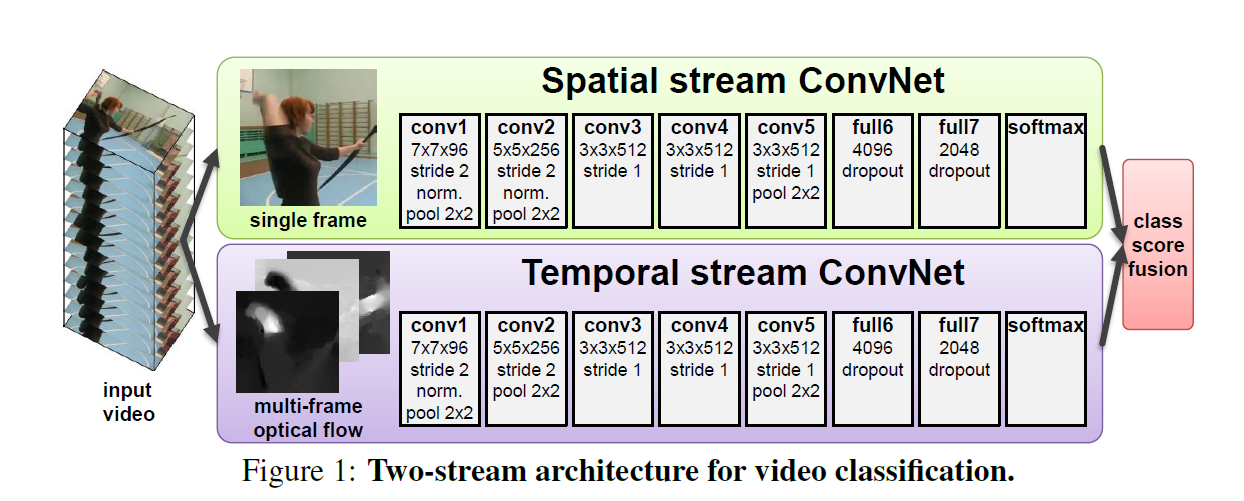
对于时间流:我们的输入是这样处理的:
Optical flow stacking:
To represent the motion across a sequence of frames, we stack the flow channels of L consecutive frames to form a total of 2L input channels. More formally, let w and h be the width and height of a video; a ConvNet input volume
for an arbitrary frame is then constructed as follows:
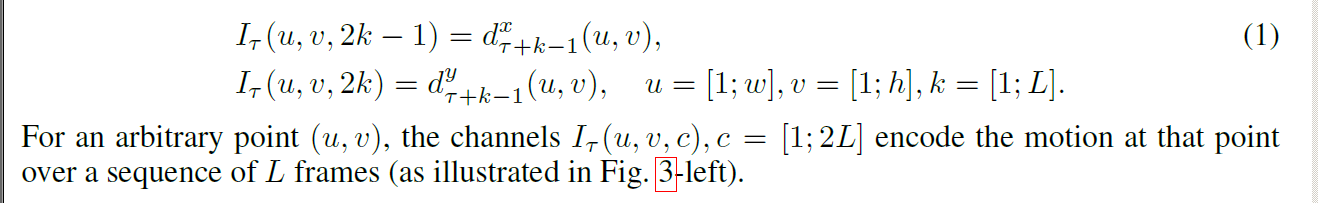
Trajectory stacking:
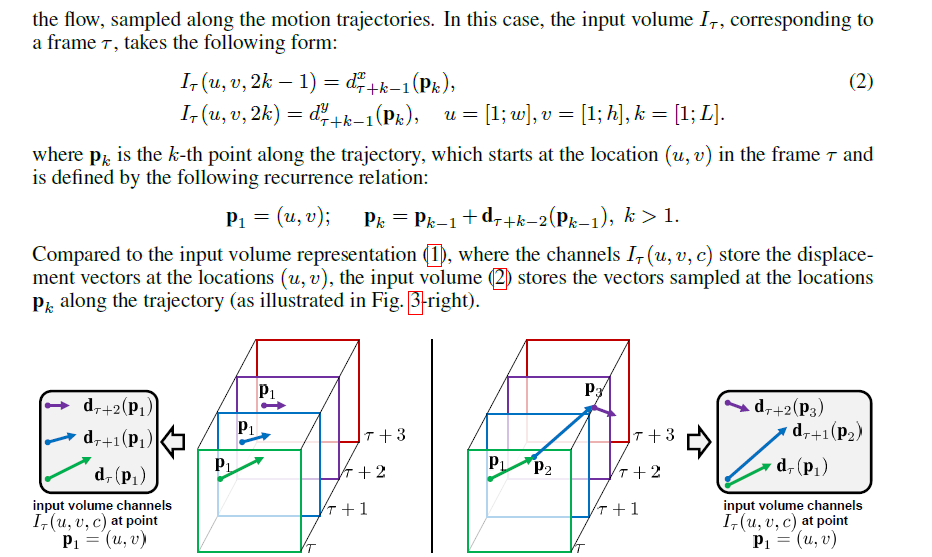
Mean Flow Subtraction
from each displacement field d we subtract its mean vector
Multi-task Learning
A more principled way of combining several datasets is based on multi-task learning,本质上就是有两个softmax层,一个用于HMDB51数据集,一个用于UCF101数据集。Its aim
is to learn a (video) representation, which is applicable not only to the task in question (such as HMDB-51 classification), but also to other tasks (e.g. UCF-101 classification). Additional tasks act as a regulariser, and allow for the exploitation of additional training data. In our case, a ConvNet architecture is modified so that it has two softmax classification layers on top of the last fullyconnected layer: one softmax layer computes HMDB-51 classification scores, the other one – the UCF-101 scores. Each of the layers is equipped with its own loss function, which operates only on the videos, coming from the respective dataset.
一开始看到这里很多地方懵了,觉得最后怎么可能同时连接两个softmax层呢,其实是将flow的卷积框架先用一个softmax维度为51的神经元个数来训练HMDB51数据集,然后把这个参数保存,把最后一层softmax维度改为101,继续在UCF101上训练。
Implement details:
框架区别:Spatial stream ConvNet和Temporal stream CnovNet的区别是temporal stream ConvNet比Spatial stream ConvNet少了第二个Norm层。
原文是:The only difference between spatial and temporal ConvNet configurations is that we removed the second normalisation layer from the latter to reduce memory consumption.
训练结果
when training a ConvNet from scratch, the rate is changed to after 50K iterations, then to
after 70K iterations, and training is stopped after 80K iterations.
In the fine-tuning scenario, the rate is changed to after 14K iterations, and training stopped after 20K iterations.
Muti-GPU training:
Multi-GPU training. Our implementation is derived from the publicly available Caffe toolbox [13],but contains a number of significant modifications, including parallel training on multiple GPUs installed in a single system. We exploit the data parallelism, and split each SGD batch across several GPUs. Training a single temporal ConvNet takes 1 day on a system with 4 NVIDIA Titan cards, which constitutes a 3:2 times speed-up over single-GPU training.
Evaluation:
1、数据集:
UCF101有13K个视频,HMDB51有6.8K个视频,两个视频分别被split三个部分,其中的两个作为training set,剩下的一个作为validation set,因此对于每个split,UCF101包含9.5K个视频,HMDB51包含3.7K个视频。We begin by comparing different architectures on the first split of the UCF-101 dataset.
2、RESULT:
Spatial ConvNet:
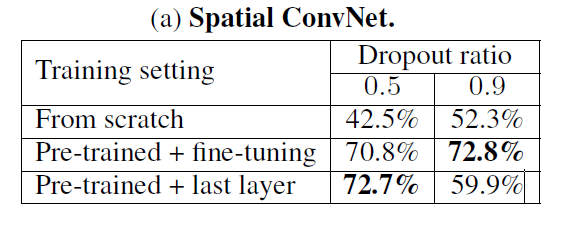
Spatial ConvNet需要pre-trained模型然后在整个网络上微调,可以看到当from scratch训练时,dropout ratio=0.9 也会过拟合。所以pre-traiined的网络上进行微调,可以看到,微调整个网络,dropout ratio=0.9 达到72.8%。
Temporal ConvNet:

Optical flow stacking L=10 最高达到81.0%。光流使用bi-dir,准确率81.2%,还有几点可以从表格里看出:
we find that mean subtraction is helpful, as it reduces the effect of global motion between the frames.
it turns out that optical flow stacking performs better than trajectory stacking, and using the bi-directional optical flow is only slightly better than a uni-directional forward flow.
Finally, we note that temporal ConvNets significantly outperform the spatial ConvNets , which confirms the importance of motion information for action recognition.
Two-stream:

(i) temporal and spatial recognition streams are complementary, as their fusion significantly improves on both (6% over temporal and 14% over
spatial nets);
(ii) SVM-based fusion of softmax scores outperforms fusion by averaging;
(iii) using bi-directional flow is not beneficial in the case of ConvNet fusion;
(iv) temporal ConvNet, trained using multi-task learning, performs the best both alone and when fused with a spatial net.
COMPARISON:
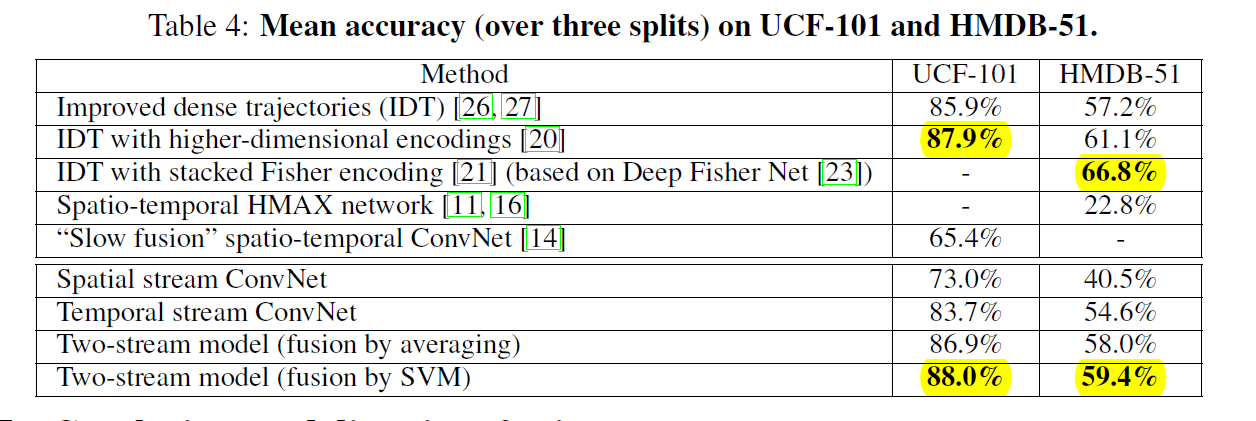
Conclusion:
这个方法有效且效果66666.
不足:
There still remain some essential ingredients of the state-of-the-art shallow representation , which are missed in our current architecture. The most prominent one is local feature pooling over spatio-temporal tubes, centered at the trajectories. Even though the input captures the optical flow along the trajectories, the spatial pooling in our network does not take the trajectories into account. Another potential area of improvement is explicit handling of camera motion, which in our case is compensated by mean displacement subtraction.















 5755
5755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









