




 本文记录了使用gdb-multiarch调试xv6内核的方法,包括makeCPUS=1qemu-gdb和gdb-multiarch的使用。在调试过程中,详细解析了entry.S的汇编代码,解释了la指令、mhartid寄存器的含义以及auipc和lui指令的功能。通过设置栈指针,为每个CPU分配栈空间,为进入start函数做好准备。
本文记录了使用gdb-multiarch调试xv6内核的方法,包括makeCPUS=1qemu-gdb和gdb-multiarch的使用。在调试过程中,详细解析了entry.S的汇编代码,解释了la指令、mhartid寄存器的含义以及auipc和lui指令的功能。通过设置栈指针,为每个CPU分配栈空间,为进入start函数做好准备。
序
过了两个月,现在准备重新看xv6的源代码,调试的时候却死活记不起来自己当初是怎么调试的,遂明白写博客记录的重要性,打算这次看源代码的时候,把容易遗忘的东西都记录下来,留待后观吧。
xv6调试方法
在xv6源代码有Makefile的路径上,一个终端输入
make CPUS=1 qemu-gdb
然后在另一个终端输入
gdb-multiarch
特别注意这里用的是gdb-multiarch(花了好多时间就是找不到合适的gdb,MIT的教学视频里面的riscv64-linux-gnu-gdb在我的linux上找不到这玩意)。该路径下有一个.gdbinit的初始化文件,gdb-multiarch会读取这个文件然后自动连接之前的gdb,然后就可以正常调试了。
记得之前还遇到了因为权限问题,gdb没办法读取这个.gdbinit文件而报错,可能因为之前配置好了,这次就没遇到这个问题了。
xv6的单步调试
从入口点entry.S的汇编代码开始。
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
初始情况entry.S被加载到地址0x80000000。这里的la是一条伪指令,由aupic和addi组合而成,实际效果相当于,sp = stack + pc。gdb显示如下:
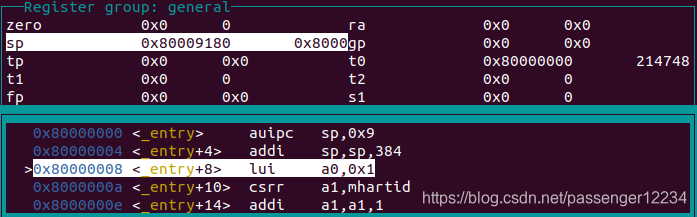
在执行auipc指令之后,sp的值变为0x80009000,因此auipc指令的作用是 rd = sp + (立即数 << 12)。接着的li也是一条伪指令,在gdb中对应指令lui。lui指令的作用是rd = 立即数 << 12。
csrr伪指令用于读取CSR到目的寄存器rd。mhartid感觉可以简单地理解为cpu编号的标识?下面是文档中的描述。

实际上通过print可以知道此时mhartid=0。我想这个作用在于多个cpu启动时为每个cpu建立一个不同的栈吧。
总的来说,entry.S的汇编代码在进入start函数之前,设置了栈指针esp = 0x80000000 + stack0 + 4096 * (mhartid + 1)。因此在进入start函数前,esp = 0x8000a180。
再查看一下stack0的值:

反汇编内核代码可以看到,stack0是位于.bss段的一个全局数据结构,声明为一个数组,为每个cpu提供一页的栈空间。
小结关键词:
gdb调试内核方法,la指令,mhartid含义,aupic,lui指令。

















 3983
3983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









