







0. 序
本篇博客记录一下在写lab3时遇到的问题与一些启发。
问题1: ops complete fast enough测试失败
测试的时候发现,我的实现需要150ms才完成一个op,检查了半天,发现问题出在raft提交日志的设计有一些问题,我设置的leader发送心跳的时间间隔为150ms。leader循环的代码类似于这样:
for{
updateLeaderCommitIndex()
updateLeaderApply()
select{
case <-heartbeat():
sendAppendRPC()
//some code
case <-otherEvent():
....//some code
}
}
所以每次向follower发送日志后,卡在了select语句上,需要等下一次心跳后才会更新apply,后来把更新apply和commitIndex的任务从raft的主协程中移出,设置一个单独的协程发送applyMsg给server,发送RPC的协程负责更新commitIndex就解决了问题。
问题2: raft提交重复的日志
判重上,基本的想法是让server维护一个map,记录了每个clientId目前最大的sequence number, clientId在Clerk服务创建时分配。所以当server收到一个put或者append请求时,仅有在该请求的sequence number大于server维护的sequence number时才会调用start函数。在server收到raft发来的applyMsg后,会更新map中对应clientId的sequence number。但这样其实并不能够保证raft不再提交重复日志。设想下面的情况
- serverA调用
start提交一个Op,此时尚未更新sequence number,然后该serverA对应的raftA把该Op复制到的另一个raftB上,还未提交该Op时,raftB成为了新的leader,这时该Op对应的RPC返回错误,clerk重新向serverB发起请求,由于raftB此前并未提交这个Op,因此serverB此时无法判重,调用start函数,最终raftB中有两条相同的日志对应该Op。
因此,必要的判重应该是在收到applyMsg时进行,而在收到clerk的RPC时进行判重只是一点性能优化罢了。
问题3: server和raft操作的原子性
一些raft和server的操作需要原子性的同步。一个需要解决的问题是,需要在leader变更的时候,server的主协程需要通知RPC协程返回错误,我的做法是利用一个map来存储哪些clientId有对应的未处理完成的request。所以之前我在收到Clerk的RPC时我是这样做的。
PutAppend(...args){
kv.mu.Lock()
outstadingReq[clientId] = true
kv.mu.Unlock()
_, _, isLeader = kv.raft.Start(Op)
if !isLeader{
kv.mu.Lock()
delete(outstandingReq, clientId)
kv.mu.Unlock()
return false
}
// some code
}
这里就没有考虑到原子性的问题,判断server对应的raft是不是leader和删除或添加Req应该是一个原子操作(在我的实现中,这样会出问题是因为server的主协程会定期检测对应的raft是不是leader,如果不是的话就需要清空所有的outstandingReq, 并且利用管道通知相应的RPC线程返回错误,如果上面的代码给outstandingReq添加元素后放掉锁,再去检测raft是不是leader,就会导致主协程看见一个pending的RPC,并且若raft不是leader,导致向管道发送多余的消息,这会导致一些问题)。
启发1:各层直接锁的调用关系
之前我写出了问题3中的代码是看到了guide中讨论的raft和server之间的死锁情况,所以希望尽可能地在调用raft时不要持有server锁。其中避免死锁是要缕清楚各层之间的调用关系。
- 在这个lab中,raft其实是一个下层服务,而server是一个上层应用,所以在实现raft代码时,应该保证不在持有raft锁的时候返回上层应用。换句话说,持有多把锁时,加锁顺序永远应该是先持有上层应用锁,再持有下层的raft锁,一方面这样避免了死锁,同时在写上层应用时,完全可以不理会下层加锁的情况,而把下层代码视为并发安全的黑盒。
启发2:格式规范的日志有助于诊断问题
比如server1的日志就全部以[KVServer][1]开头,而下层的raft的日志则全以[raft][1]开头,这样问题出现后,能够用grep快速地得到某个server或者raft的日志,有助于问题的排查。
一个遗留问题
在跑TestConcurrent3A的时候,我会有小概率遇到下面的报错(然而我在写这篇博客的时候又跑了100遍,结果错误并没有出现)
runtime: marked free object in span
fatal error: Found pointer to free object
但我并没有使用unsafe包?甚至之前也出现过out of memory的报错,实际上一边跑测试,一边用top命令查看测试的内存占用,大概维持在20多M的样子,所以也不太理解为什么会出现out of memory的问题。不过用pporf查看了一下运行时的内存分配情况
$go test -run TestConcurrent3A -memprofile mem.prof
Test: many clients (3A) ...
... Passed -- 15.4 5 21244 4219
PASS
ok 6.824/kvraft 15.422s
$go tool pprof -http=:8081 mem.prof
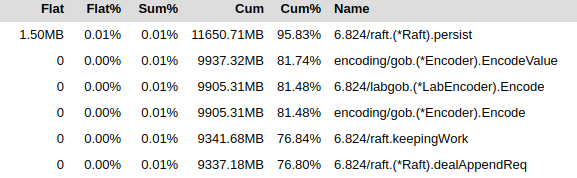
从top图上可以看到,总共分配了11.5G的内存,罪魁祸首就是这个persist函数。
看一下persist函数的实现
func (ps *Persister) ReadRaftState() []byte {
ps.mu.Lock()
defer ps.mu.Unlock()
return clone(ps.raftstate)
}
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
// w := new(bytes.Buffer)
// e := labgob.NewEncoder(w)
// e.Encode(rf.xxx)
// e.Encode(rf.yyy)
// data := w.Bytes()
// rf.persister.SaveRaftState(data)
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
if e.Encode(rf.currentTerm) != nil || e.Encode(rf.votedFor) != nil || e.Encode(rf.log) != nil {
log.Fatalf("[raft][%v] persist encode fail\n", rf.me)
}
rf.persister.SaveRaftState(w.Bytes())
}
当然其实这个persist的接口设计其实很不好,因为每次往log里面添加一个Op都需要整个重新分配内存,然后把原来那块内存释放掉,而不是直接向persist里面添加一个Op。
一个可以做的小优化是,这里ReadRaftState函数的复制是多余的,因此我们可以把persist函数改为下面的样子
rf.persister.mu.Lock()
rf.persister.raftstate = w.Bytes()
rf.persister.mu.Unlock()
//rf.persister.SaveRaftState(w.Bytes())

从上图可以看到,预期这样可以省去1个多G的内存分配。
$go test -run TestConcurrent3A -memprofile memopt.prof
Test: many clients (3A) ...
... Passed -- 15.3 5 20494 4068
PASS
ok 6.824/kvraft 15.297s
$go tool pprof memopt.prof
File: kvraft.test
Type: alloc_space
Time: Feb 16, 2022 at 8:25pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top --cum
Showing nodes accounting for 0.50MB, 0.0052% of 9616.26MB total
Dropped 80 nodes (cum <= 48.08MB)
Showing top 10 nodes out of 54
flat flat% sum% cum cum%
0 0% 0% 9209.75MB 95.77% encoding/gob.(*Encoder).EncodeValue
0 0% 0% 9189.74MB 95.56% 6.824/labgob.(*LabEncoder).Encode
0 0% 0% 9189.74MB 95.56% encoding/gob.(*Encoder).Encode
0.50MB 0.0052% 0.0052% 9150.73MB 95.16% 6.824/raft.(*Raft).persist
0 0% 0.0052% 7486.93MB 77.86% encoding/gob.(*Encoder).encode
0 0% 0.0052% 7485.93MB 77.85% encoding/gob.(*Encoder).encodeStruct
0 0% 0.0052% 7481.43MB 77.80% encoding/gob.encOpFor.func4
0 0% 0.0052% 7470.93MB 77.69% encoding/gob.(*Encoder).encodeArray
0 0% 0.0052% 7470.93MB 77.69% encoding/gob.encOpFor.func1
0 0% 0.0052% 7444.42MB 77.41% encoding/gob.(*Encoder).encodeSingle
(pprof) list persist
Total: 9.39GB
ROUTINE ======================== 6.824/raft.(*Raft).persist in /home/ckf/distribution_lesson/6.824/src/raft/raft.go
512.02kB 8.94GB (flat, cum) 95.16% of Total
. . 145: // e := labgob.NewEncoder(w)
. . 146: // e.Encode(rf.xxx)
. . 147: // e.Encode(rf.yyy)
. . 148: // data := w.Bytes()
. . 149: // rf.persister.SaveRaftState(data)
512.02kB 512.02kB 150: w := new(bytes.Buffer)
. 6.50MB 151: e := labgob.NewEncoder(w)
. 8.93GB 152: if e.Encode(rf.currentTerm) != nil || e.Encode(rf.votedFor) != nil || e.Encode(rf.log) != nil {
. . 153: log.Fatalf("[raft][%v] persist encode fail\n", rf.me)
. . 154: }
. . 155: rf.persister.mu.Lock()
. . 156: rf.persister.raftstate = w.Bytes()
. . 157: rf.persister.mu.Unlock()
可以看到,内存分配的减少和预期一致,也可以看到,内存分配的大头基本在encoder上,这一点点优化可能影响也不是很大。
结果
Test: one client (3A) ...
... Passed -- 15.1 5 20590 4110
Test: ops complete fast enough (3A) ...
... Passed -- 1.8 3 10032 0
Test: many clients (3A) ...
... Passed -- 15.2 5 18441 3657
Test: unreliable net, many clients (3A) ...
... Passed -- 16.6 5 8580 1431
Test: concurrent append to same key, unreliable (3A) ...
... Passed -- 1.0 3 208 52
Test: progress in majority (3A) ...
... Passed -- 0.7 5 50 2
Test: no progress in minority (3A) ...
... Passed -- 1.0 5 86 3
Test: completion after heal (3A) ...
... Passed -- 1.0 5 43 3
Test: partitions, one client (3A) ...
... Passed -- 22.7 5 17678 3191
Test: partitions, many clients (3A) ...
... Passed -- 22.7 5 49859 3269
Test: restarts, one client (3A) ...
... Passed -- 19.4 5 30511 3853
Test: restarts, many clients (3A) ...
... Passed -- 19.8 5 60799 3795
Test: unreliable net, restarts, many clients (3A) ...
... Passed -- 20.4 5 9027 1433
Test: restarts, partitions, many clients (3A) ...
... Passed -- 27.2 5 73206 3706
Test: unreliable net, restarts, partitions, many clients (3A) ...
... Passed -- 27.6 5 6699 730
Test: unreliable net, restarts, partitions, random keys, many clients (3A) ...
... Passed -- 28.7 7 20670 2001
Test: InstallSnapshot RPC (3B) ...
... Passed -- 2.4 3 323 63
Test: snapshot size is reasonable (3B) ...
... Passed -- 0.7 3 2426 800
Test: ops complete fast enough (3B) ...
... Passed -- 0.7 3 9016 0
Test: restarts, snapshots, one client (3B) ...
... Passed -- 20.7 5 162789 29773
Test: restarts, snapshots, many clients (3B) ...
... Passed -- 19.8 5 30317 596
Test: unreliable net, snapshots, many clients (3B) ...
... Passed -- 16.3 5 8056 1335
Test: unreliable net, restarts, snapshots, many clients (3B) ...
... Passed -- 20.9 5 9182 1426
Test: unreliable net, restarts, partitions, snapshots, many clients (3B) ...
... Passed -- 28.2 5 9006 1065
Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (3B) ...
... Passed -- 28.7 7 24744 2360
PASS
ok 6.824/kvraft 380.086s















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









