







本文用到的Mysql版本是5.0.18
数据库复制技术说明:(本文后面有具体操作示例)
MySQL features support for one-way, asynchronous replication, in which one server acts as the master, while one or more other servers act as slaves. This is in contrast to the synchronous replication which is a characteristic of MySQL Cluster. In single-master replication, the master server writes updates to its binary log files and maintains an index of those files to keep track of log rotation. The binary log files serve as a record of updates to be sent to any slave servers. When a slave connects to its master, it informs the master of the position up to which the slave read the logs at its last successful update. The slave receives any updates that have taken place since that time, and then blocks and waits for the master to notify it of new updates.
A slave server can itself serve as a master if you want to set up chained replication servers.
Replication offers benefits for robustness, speed, and system administration:
- Robustness is increased with a master/slave setup. In the event of problems with the master, you can switch to the slave as a backup.
- Better response time for clients can be achieved by splitting the load for processing client queries between the master and slave servers. SELECT queries may be sent to the slave to reduce the query processing load of the master. Statements that modify data should still be sent to the master so that the master and slave do not get out of synchrony. This load-balancing strategy is effective if non-updating queries dominate, but that is the normal case.
- Another benefit of using replication is that you can perform database backups using a slave server without disturbing the master. The master continues to process updates while the backup is being made.
Disadvantage:
- Running the server with the binary log enabled makes performance about 1% slower(运行服务器时若启用二进制日志则性能大约慢1%). However, the benefits of the binary log for restore operations and in allowing you to setup replication generally outweigh this minor performance decrement.
MySQL replication is based on the master server keeping track of all changes to your databases (updates, deletes, and so on) in its binary logs. Therefore, to use replication, you must enable binary logging on the master server.
MySQL has several different log files that can help you find out what is going on inside mysqld:
Log Type Information Written to Log
The error log Problems encountered starting, running, or stopping mysqld
The general query log Established client connections and statements received from clients
The binary log All statements that change data (also used for replication)
The slow log All queries that took more than long_query_time seconds to execute or didn’t use indexes
By default, there is no binary log, you can start mysqld with --log-bin=[filename] to enable binary loging like:
shell>mysqld –u root –pmanager --defaults-file=”d:/mysql50/my.ini” --log-bin=”d:/mysql50/data/logs/log_bin”
Or, you can set it in my.ini like:
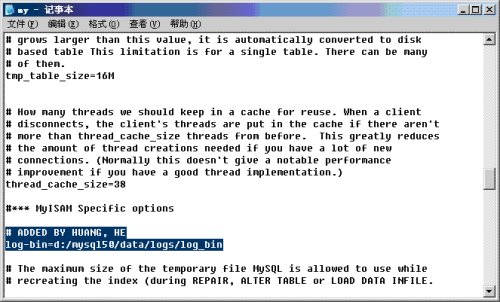
图01
When you restart the mysql server, there some files created automatically like:
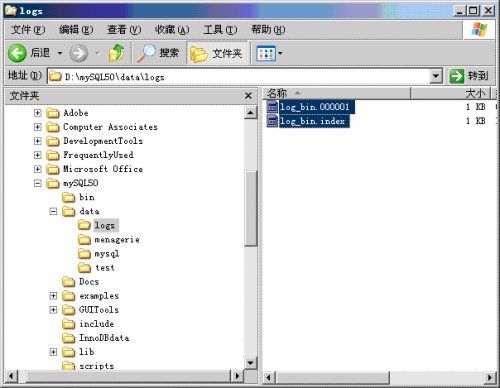
图02
Please note that, the directory of logs is created manually by myself, typically binary logs (in fact, all logs) will be stored in directory data.
mysqld appends a numeric extension to the binary log basename. The number increases each time the server creates a new log file, thus creating an ordered series of files. The server creates a new binary log file each time it starts or flushes the logs. The server also creates a new binary log file automatically when the current log's size reaches max_binlog_size. A binary log file may become larger than max_binlog_size if you are using large transactions because a transaction is written to the file in one piece, never split between files.
To keep track of which binary log files have been used, mysqld also creates a binary log index file that contains the names of all used binary log files. By default this has the same basename as the binary log file, with the extension '.index'. You can change the name of the binary log index file with the --log-bin-index[=file_name] option. You should not manually edit this file while mysqld is running; doing so would confuse mysqld.
It is extremely important to realize that the binary log is simply a record starting from the fixed point in time at which you enable binary logging. Any slaves that you set up need copies of the databases on your master as they existed at the moment you enabled binary logging on the master. If you start your slaves with databases that are not in the same state as those on the master when the binary log was started, your slaves are quite likely to fail.
By default, relay logs filenames have the form host_name-relay-bin.nnnnnn, where host_name is the name of the slave server host and nnnnnn is a sequence number, beginning with 000001.The slave uses an index file to track the relay log files currently in use. The default relay log index filename is host_name-relay-bin.index. By default, the slave server creates relay log files in its data directory. The default filenames can be overridden with the --relay-log and --relay-log-index server options.
Relay logs have the same format as binary logs and can be read using mysqlbinlog.
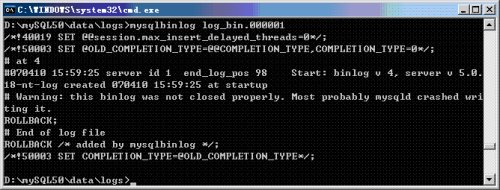
图03
A slave server create a new relay log file under the following conditions:
- each time the I/O thread starts
- When the logs are flushed; for example, with FLUSH LOGS or mysqladmin flush-logs
- When the size of the current relay log file becomes too large. The meaning of “too large” is determined as follows:
- If the value of max_relay_log_size is greater than 0, that is the maximum relay log file size.
- If the value of max_relay_log_size is 0, max_binlog_size determines the maximum relay log file size.
A slave replication server creates two additional small files in the data directory. These status files are name master.info and relay-log.info by default, Their names can be changed by using the --master-info-file option.
现在,在master上插入两条记录:
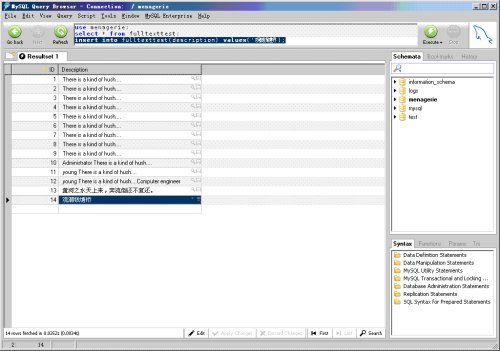
图04

图05
两条记录一条是在MySQL Query Browser里加入的( 对中文支持不好),另外一条是在mysql终端上加入的,然后我们用mysqlbinlog命令就可以看到此时的bin log已经和前面不同了。Mysql就是利用这样的原理来进行数据库复制的。
数据库复制的实际操作具体步骤:
1. 准备工作
- 在192.168.0.186上安装Mysql5.0.18(OS均为xp),作为Master
- 在192.168.0.64上安装Mysql5.0.18(OS均为xp),作为Slave
2. 在Master MySQL服务器上建立一个用于复制的账号给Slave服务器
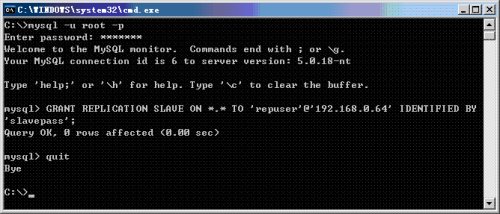
图06
上面是Master开放一个Slave上的账号repuser/slavepass用于数据复制。这时候通过MySQL Administrator可以看到:
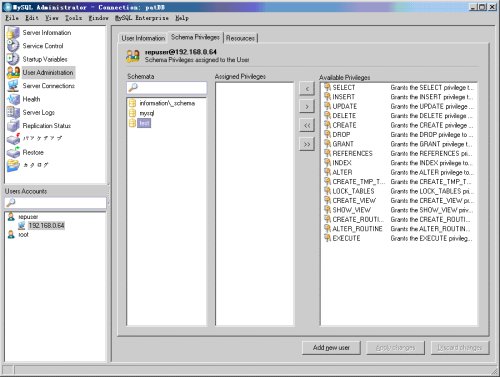
图07
3. 在database服务库中建立一个数据表reptable1
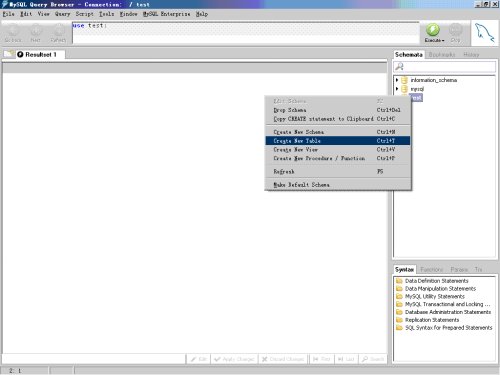
图08
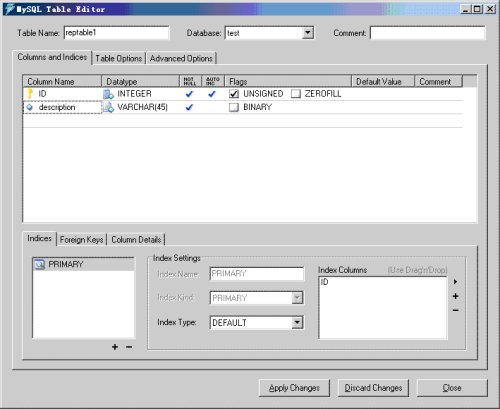
图09
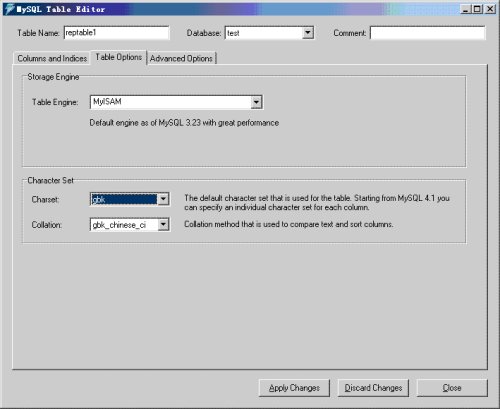
图10
注意,建表时字段名千万不要使用保留字,如description不能写称desc,否则会报1064错误。
4. 在reptable1中插入一条记录:

图11
5. 将Master服务器shutdown
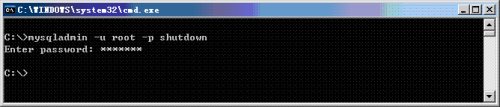
图12
6. 将Slave服务器也shutdown,将Master服务器Data目录下相应的数据库目录中的所有文件拷贝到Slave服务器的Data目录下。比如将Master的../data/test目录中的所有文件拷贝到Slave的../data/test目录中(将原来的文件覆盖掉了)
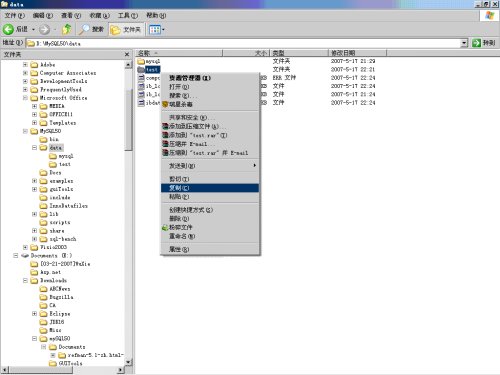
图13
7. 修改Master机器上的my.ini文件,在〔mysqld〕区段内加入如下信息(见高亮部分):
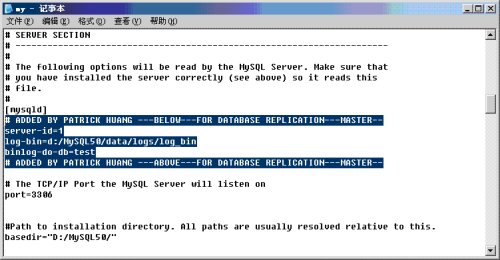
图14
各字段信息含义如下:
server-id的值域为1-2^32-1。
(--server-id=# Uniquely identifies the server instance in the community of replication partners.)
log-bin指定二进制日志文件在目录d:/MySQL50/data/logs下的文件log_bin,每次数据库启动或者日志的大小超过max_binlog_size时,会自动在其后加1。
(--max_binlog_size=# Binary log will be rotated automatically when the size exceeds this value. Will also apply to relay logs if max_relay_log_size is 0. The minimum value for this variable is 4096). 如下图所示。
binlog-do-db=test告诉Master只记录数据库test的变化。
(--binlog-do-db=dbname Tells the master it should log updates for the specified database, and execlude all others not explicitly mentioned).
图15
8. 现在设定Slave上的my.ini文件,在〔mysqld〕区段内加入如下信息(见高亮部分):
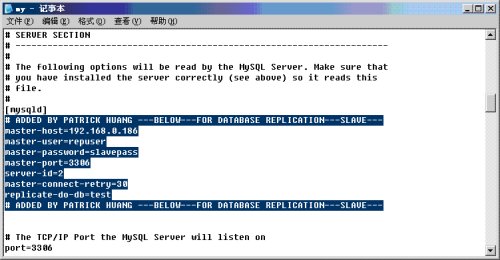
图16
各字段信息含义如下:
--master-host=name
Master hostname or IP address for replication. If not set, the slave thread will not be started. Note that the setting of master-host will be ignored if there exists a valid master.info file.
--master-user=name
The username the slave thread will use for authentication when connecting to the master. The user must have FILE privilege. If the master user is not set, user test is assumed. The value in master.info will take precedence if it can be read.
--master-password=password
The password the slave thread will authenticate with when connecting to the master. If not set, an empty password is assumed.The value in master.info will take precedence if it can be read.
--master-port=#
The port the master is listening on. If not set, the compiled setting of MYSQL_PORT is assumed. If you have not tinkered with configure options, this should be 3306. The value in master.info will take precedence if it can be read.
--master-connect-retry=#
The number of seconds the slave thread will sleep before retrying to connect to the master in case the master goes down or the connection is lost.
--replicate-do-db=dbname
Tells the slave thread to restrict replication to the specified database. To specify more than one database, use the directive multiple times, once for each database
Note that this will only work if you do not use cross-database queries such as UPDATE some_db.some_table SET foo='bar' while having selected a different or no database. If you need cross database updates to work, make sure you have 3.23.28 or later, and use replicate-wild-do-table=db_name.%.
9. 启动Master,再启动Slave
10. 在Master上往test.reptable1中再插入两条数据如下所示:
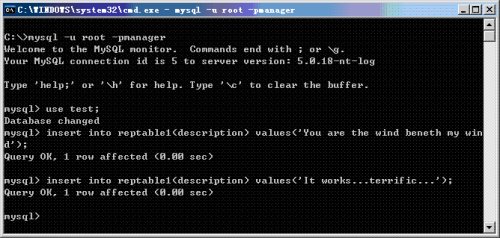
图17
我们到Slave上查到的结果如下所示:
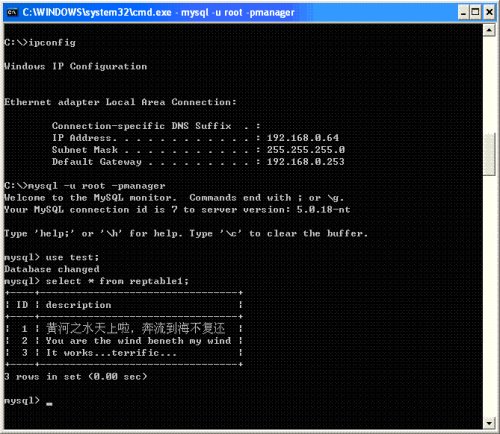
图18
很明显数据复制成功!
11. 实验中的其它感觉:
a. 在Master插入数据后,Slave立即就收到了数据,感觉上这个数据复制是由Master在触发似的。
b. 如果将网线拔出,我们仍然可以在Master上对数据进行操作,只要网线一旦接通,就会在master-connect-retry(上面文件中设定是30s)所规定的时间里,将数据复制过去。















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









