






需求爬取微信读书的某一本书的整本书的内容
增强需求,大批量爬取一批书籍内容
众所周知微信读书是一个很好用的app,他上面书籍的格式很好,质量很高。
本人充值了会员但是看完做完笔记每次还得去翻很不方便,于是想把书籍内容弄下来,方便做笔记学习,本文只做学习交流,不做任何商用,不会披露关键细节代码。如有问题欢迎互相私聊交流:mastercy1
01.找到请求,解析响应
02.解析参数,模拟请求
好,响应我们会解析了,我们尝试模拟一下请求吧
右键copy 复制 curl(base curl)
然后放到爬虫工具库-spidertools.cn 爬虫工具库解析成python request
这网站很好用,推荐一波
直接请求 没有返回值,好那么三步走 看一眼参数 看一眼headers 看一眼cookies
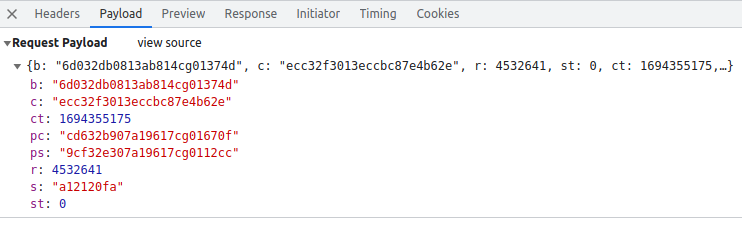
playload里是这样
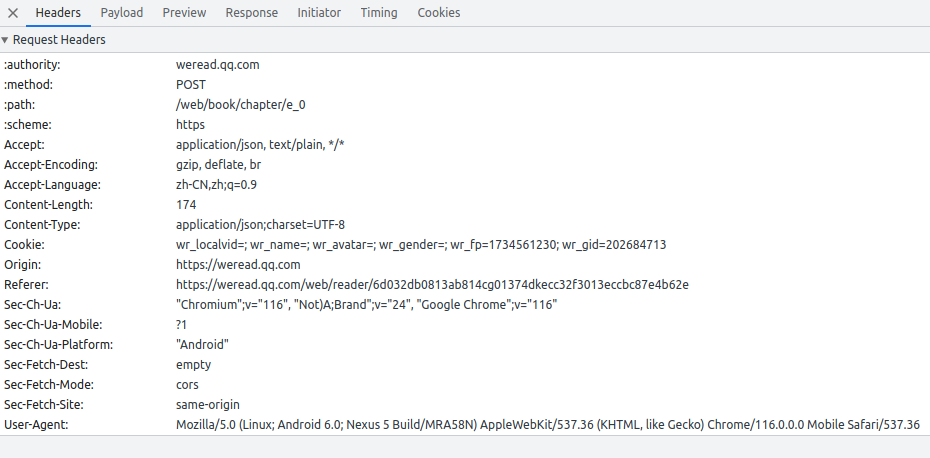
headers里是这样
先观察发现网址里的参数
https://weread.xx.com/web/reader/6d032db0813ab814cg01374dkecc32f3013eccbc87e4b62e
和playload里的b+'k'+c 一模一样,然后多翻几页,换几本书试试看果然一样
这里推测,前面一部分就是的某种id,后面是翻页信息
ct显然时间戳,ps,pc发现几个参数的格式都差不多应该是一种处理手法
r和s看不出来
好准备进去找找,我们还是看堆栈,我们第一次点的三第一个8.22xxx.js对吧
那个里面已经有参数了,你们说明在之前就生成了,所以我们之间看上一个8.22xxx.js
如果那个地方还没有生成参数,你们追这两个js中间的部分就可以找到参数生成的地方
然后第一遍先一直往下走看看整个逻辑,一直走一直走,大概的逻辑就是取了很多环境,然后不停的在大数据里取方法的真实的名字,然后走到这里,看起来就是组装参数的部分了
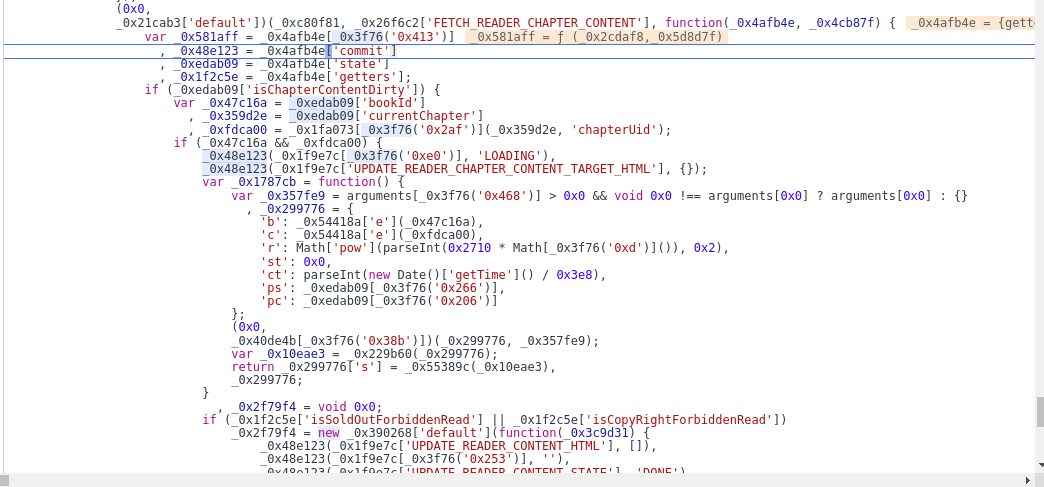
往下在滚动看看,对的下面就是四个异步请求。回来看参数咋产生的
b、c 、ct 、pc 、ps 、r 、s 、st
//r和ct 直接用就行
'r':Math['pow'](parseInt(0x2710 * Math['random']()), 0x2)
'ct': parseInt(new Date()['getTime']() / 0x3e8)
//b和c是传入的 bookID和 章节number
'b': _0x54418a['e'](_0x47c16a)
'c': _0x54418a['e'](_0xfdca00)
//ps pc是取的传入的对象的某一个属性
'ps': _0xedab09[_0x3f76('0x266')]
'pc': _0xedab09[_0x3f76('0x206')]
//st 在下面 第二个请求是改成1
s是把上面的书籍转成了str传到了一个方法里
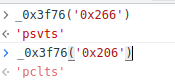
好我们先看处理b和c的e 方法就这样自己还原一下即可
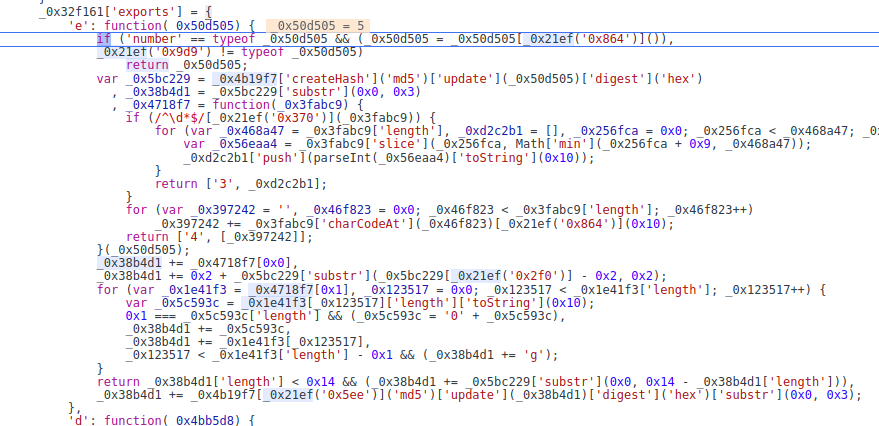
再看s,先进去,也是还原一下就行

然后就到了ps和pc了,psvts和pclts
我们重新进一下上一个8.22xxx.js的断点,其实看一下bookinfo里已经有bookid和ps和pc了
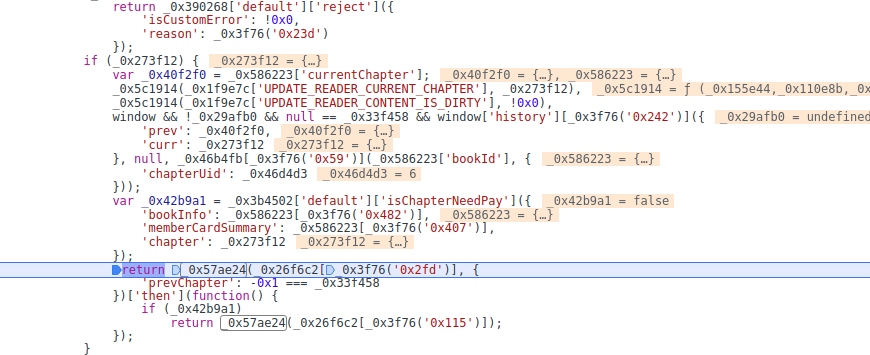
在往上看其实他也是传进来的

往上走 看上面的8.22xxx.js 这个 堆栈 ,我们看还是已经存在的了,而且这个是this,那么如果这样我们就要看一下这个控制流了
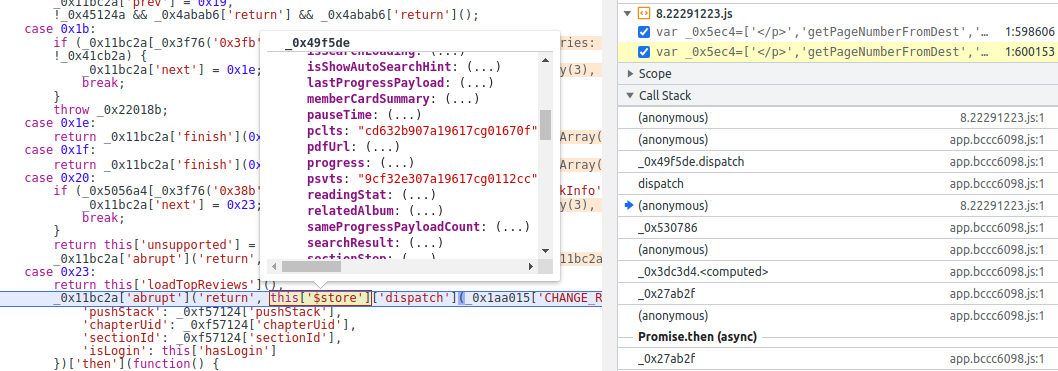
还是第一行打断点看看,进来的时候有没有,得从8.22xxx.js那个文件的函数最上面进
发现进来的时候还是已经有了,怎么回事看起来,在别的地方就加载完了,重新回到那个函数发现就是进到这里

我们直接搜psvts和pclts发现他定义在上面
这里有两个思路一个是直接hook这个参数,从最开始调到出来参数的地方那个方法替换掉xxx
Object.defineProperty(xxxxxx['state']['reader'],"pclts",{
set(){
debugger;
}
})
另外一个直接搜吗,往下找找看,最后都会发现是定义在这边的

再观察一下 这个 xxxx[e] 方法和处理b和c的e方法是同一个在看一下传入
因为这个是几乎开局就定义的
我们得直接刷新来进会方便很多对这两个方法打上断点以后f5
使用function xxx(){} 将无限debugger里的每个方法重写掉 大概6-7个方法以后
会直接进入 pclts 这里
打印一下入参是时间戳
ok然后我们看这个方法叫 'UPDATEREADERPAGECLIENTTIMESTAMP'
什么意思 浏览器时间
然后合理怀疑一下为什么没有断在 psvts上面? 打印一下上面的方法名,服务器时间,这玩意会不会是返回的呢
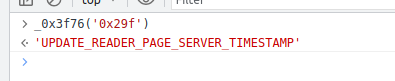
好 重新进 一搜索 有了,就在初始化的时候 这是pc还没有
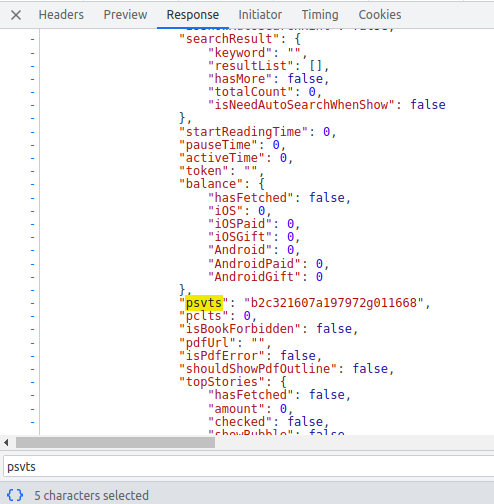
接下来就是还原算法和模拟请求了,这里其实也不用一定要服务器返回其实也可以自己取当前时间减一点点
在拼接好参数 请求e0,1,2,3
再将
e0,1,3加起来解码就是正文内容了
总结先观察,小心求证,大胆假设
技巧上
无限debugger有很多种技巧过,有些麻烦的网站不光要hook set函数还需要打日志断点
思路上
要搞清楚自己在追谁,不要漫无目的的往下走,追对了参数,就像是追对了人


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









