







文章目录
wiredtiger引擎定义的内存数据结构
在上一篇文章介绍整个LSM Tree的架构图中,内存结构没有给出来。也就是给各种引擎自己发挥的空间。这里来说说wiredtiger的内存数据结构。
从网上找了一张从阿里云出来的图片:
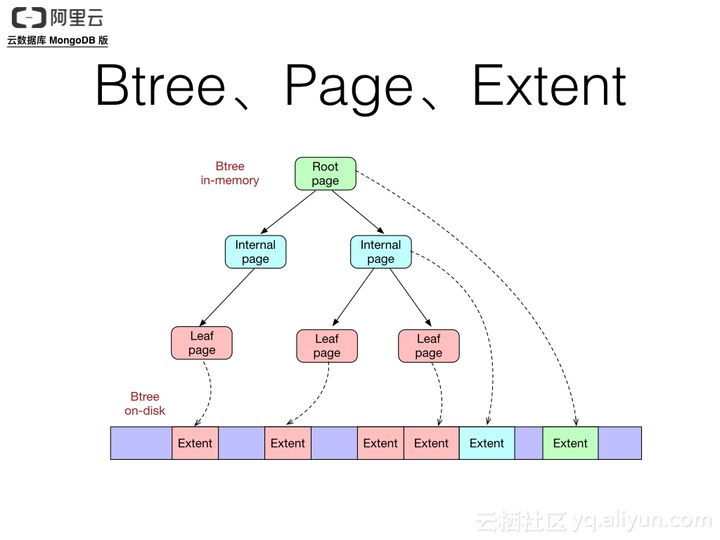
也就是说,wiredTiger在内存中的主要数据结构就是B树(B树的结构可以参考:
https://blog.csdn.net/pcgamer/article/details/107156865?spm=1001.2014.3001.5502
)。每个B树的节点称作一个Page,也是wiredTiger调度的基本单位。在B树中,总共分成三种Page:
- Root Page: 根Page。
- Internal Page:这个会存在多层,不保存真正的业务数据,只保存下一层Page节点的地址指针。
- Leaf Page:保存真正的业务数据。
源码中的page结构
删掉了很多注释和#define的内容,只留下主要的内容
/*
\* WT_PAGE --
\* The WT_PAGE structure describes the in-memory page information.
*/
struct __wt_page {
union {
struct {
WT_REF *parent_ref; /* Parent reference */
uint64_t split_gen; /* Generation of last split */
WT_PAGE_INDEX *volatile __index; /* Collated children */
} intl;
/* Row-store leaf page. */
WT_ROW *row; /* Key/value pairs */
/* Fixed-length column-store leaf page. */
uint8_t *fix_bitf; /* Values */
/* Variable-length column-store leaf page. */
/* 用于列式数据库,mongodb中没有用到 */
struct {
WT_COL *col_var; /* Values */
WT_COL_VAR_REPEAT *repeats; /* Repeats array */
} col_var;
} u; //一个联合结构体
#define pg_row u.row
/*
* Page entry count, page-wide prefix information, type and flags are positioned at the end of
* the WT_PAGE union to reduce cache misses when searching row-store pages.
*
* The entries field only applies to leaf pages, internal pages use the page-index entries
* instead.
*/
uint32_t entries; /* Leaf page entries */
uint32_t prefix_start; /* Best page prefix starting slot */
uint32_t prefix_stop; /* Maximum slot to which the best page prefix applies */
#define WT_PAGE_INVALID 0 /* Invalid page */
#define WT_PAGE_BLOCK_MANAGER 1 /* Block-manager page */
#define WT_PAGE_COL_FIX 2 /* Col-store fixed-len leaf */
#define WT_PAGE_COL_INT 3 /* Col-store internal page */
#define WT_PAGE_COL_VAR 4 /* Col-store var-length leaf page */
#define WT_PAGE_OVFL 5 /* Overflow page */
#define WT_PAGE_ROW_INT 6 /* Row-store internal page */
#define WT_PAGE_ROW_LEAF 7 /* Row-store leaf page */
uint8_t type; /* Page type */
uint8_t flags_atomic; /* Atomic flags, use F_*_ATOMIC */
uint8_t unused[2]; /* Unused padding */
size_t memory_footprint; /* Memory attached to the page */
/* Page's on-disk representation: NULL for pages created in memory. */
const WT_PAGE_HEADER *dsk; //上一篇提到过的Page_Header
/* If/when the page is modified, we need lots more information. */
WT_PAGE_MODIFY *modify;
uint64_t read_gen;
uint64_t cache_create_gen; /* Page create timestamp */
uint64_t evict_pass_gen; /* Eviction pass generation */
}
Root Page & Internal Page
Root Page和Internal Page就是形成一个B+树的基本结构,针对源码一起分析一下:
在上面提到的page的基本数据结构中,有一个union结构的成员变量u,如果是root或者internal page的话,就是使用的其中的u.intl成员变量:
struct {
WT_REF *parent_ref; /* Parent reference */
uint64_t split_gen; /* Generation of last split */
WT_PAGE_INDEX *volatile __index; /* Collated children */
} intl;
1. paretn_ref是指向父节点的,这里不是一个直接指向WT_PAGE的结构指针,而是又包装了一层:WT_REF。
/*
\* WT_REF --
\* A single in-memory page and state information.
*/
struct __wt_ref {
WT_PAGE *page; /* Page */
WT_PAGE *volatile home; /* Reference page */
volatile uint32_t pindex_hint; /* Reference page index hint */
uint8_t unused[2]; /* Padding: before the flags field so flags can be easily expanded. */
uint8_t flags;
volatile uint8_t state; /* Page state */
void *addr;
union {
uint64_t recno; /* Column-store: starting recno */
void *ikey; /* Row-store: key */
} key;
union {
WT_PAGE_DELETED *del; /* Page not instantiated, page-deleted structure */
WT_UPDATE **update; /* Page instantiated, update list for subsequent commit/abort */
} ft_info;
/* Capture history of ref state changes. */
WT_REF_HIST hist[WT_REF_SAVE_STATE_MAX];
uint64_t histoff;
};
a. 在这个结构里,第一个成员就是一个指向WT_PAGE的指针了(另外的一个home指针稍后再说)。所以说其实BTree在wiredtiger里其实是由WT_REF这种结构组成的。
b. PAGE的state也保存在这里:volatile uint8_t state; /* Page state */
c. 这个page节点的关键字在union结构里:key
接下来就是page里面指向子节点的成员变量WT_PAGE_INDEX *volatile __index了。看一下WT_PAGE_INDEX的结构:
/*
\* WT_PAGE_INDEX --
\* The page index held by each internal page.
*/
struct __wt_page_index {
uint32_t entries;
uint32_t deleted_entries;
WT_REF **index;
};
a. entries记录了有多少个子节点
b. index这个二维指针指向一个子节点的列表,每个列表又都是一个WT_REF结构
所以,这颗B+树的组成结构大概是这个样子的:

Leaf Page
叶子节点的page是存储了数据的,先来看下这些数据是怎么存储的,在_wt_page里面:
-
WT_ROW row; / Key/value pairs */ (这个是在u的union结构中,如果是leaf page,那就是用这个成员,如果是internal page,那用的就是intl的struct成员)
-
WT_ROW的结构很简单:
/* * WT_ROW -- * Each in-memory page row-store leaf page has an array of WT_ROW structures: * this is created from on-page data when a page is read from the file. It's * sorted by key, fixed in size, and starts with a reference to on-page data. * */ struct __wt_row { /* On-page key, on-page cell, or off-page WT_IKEY */ void *volatile __key; };这个void类型的指针指向一个WT_IKEY的结构,里面的cell_offset是一个偏移地址+大小,指向上一篇说过的一个CELL结构。从硬盘读取出数据后就存放在这样的一些CELL结构中。
/* \* WT_IKEY -- \* Instantiated key: row-store keys are usually prefix compressed or overflow objects. \* Normally, a row-store page in-memory key points to the on-page WT_CELL, but in some \* cases, we instantiate the key in memory, in which case the row-store page in-memory \* key points to a WT_IKEY structure. */ struct __wt_ikey { uint32_t size; /* Key length */ /* \* If we no longer point to the key's on-page WT_CELL, we can't find its \* related value. Save the offset of the key cell in the page. * \* Row-store cell references are page offsets, not pointers (we boldly \* re-invent short pointers). The trade-off is 4B per K/V pair on a \* 64-bit machine vs. a single cycle for the addition of a base pointer. */ uint32_t cell_offset; }; -
uint32_t entries; /* Leaf page entries */ 有多少个数据,也就是键值对。
-
循环获取所有数据定义了两个宏:
/* \* WT_ROW_FOREACH -- \* Walk the entries of an in-memory row-store leaf page. */ \#define WT_ROW_FOREACH(page, rip, i) \ for ((i) = (page)->entries, (rip) = (page)->pg_row; (i) > 0; ++(rip), --(i)) \#define WT_ROW_FOREACH_REVERSE(page, rip, i) \ for ((i) = (page)->entries, (rip) = (page)->pg_row + ((page)->entries - 1); (i) > 0; \ --(rip), --(i))根据 pg_row的宏定义就知道了 pg_row 就是 u.row,也就是ROW数组的起始地址指针。
-
综上所述,大概是这么个结构:

因为在leaf page里,没有用到u.intl结构,所以叶子节点没有指向父节点的指针。
WT_PAGE_MODIFY
除了基本的构成B树的结构之外,还有一些协助CRUD的一些数据结构。其中重点说一说这个WT_PAGE_MODIFY,先看看代码:
/*
\* WT_PAGE_MODIFY --
\* When a page is modified, there's additional information to maintain.
*/
struct __wt_page_modify {
/* The first unwritten transaction ID (approximate). */
uint64_t first_dirty_txn;
/* The transaction state last time eviction was attempted. */
uint64_t last_evict_pass_gen;
uint64_t last_eviction_id;
wt_timestamp_t last_eviction_timestamp;
/* Avoid checking for obsolete updates during checkpoints. */
uint64_t obsolete_check_txn;
wt_timestamp_t obsolete_check_timestamp;
uint64_t rec_max_txn;
wt_timestamp_t rec_max_timestamp;
/* The largest update transaction ID (approximate). */
uint64_t update_txn;
/* Dirty bytes added to the cache. */
size_t bytes_dirty;
size_t bytes_updates;
union {
struct { /* Single, written replacement block */
WT_ADDR replace;
void *disk_image;
} r;
struct {
WT_MULTI *multi; /* Multiple replacement blocks */
uint32_t multi_entries; /* Multiple blocks element count */
} m;
} u1;
union {
struct {
WT_PAGE *root_split; /* Linked list of root split pages */
} intl;
struct {
WT_INSERT_HEAD **append;
WT_INSERT_HEAD **update;
uint64_t split_recno;
} column_leaf;
struct {
/* Inserted items for row-store. */
WT_INSERT_HEAD **insert;
/* Updated items for row-stores. */
WT_UPDATE **update;
} row_leaf;
} u2;
/* Overflow record tracking for reconciliation. */
WT_OVFL_TRACK *ovfl_track;
\#define WT_PAGE_LOCK(s, p) __wt_spin_lock((s), &(p)->modify->page_lock)
\#define WT_PAGE_TRYLOCK(s, p) __wt_spin_trylock((s), &(p)->modify->page_lock)
\#define WT_PAGE_UNLOCK(s, p) __wt_spin_unlock((s), &(p)->modify->page_lock)
WT_SPINLOCK page_lock; /* Page's spinlock */
\#define WT_PAGE_CLEAN 0
\#define WT_PAGE_DIRTY_FIRST
\#define WT_PAGE_DIRTY 2
uint32_t page_state;
\#define WT_PM_REC_EMPTY 1 /* Reconciliation: no replacement */
\#define WT_PM_REC_MULTIBLOCK 2 /* Reconciliation: multiple blocks */
\#define WT_PM_REC_REPLACE 3 /* Reconciliation: single block */
uint8_t rec_result; /* Reconciliation state */
\#define WT_PAGE_RS_RESTORED 0x1
uint8_t restore_state; /* Created by restoring updates */
};
具体的CRUD过程,我们在下一篇再说,这里主要再展开说一下里面的两个结构:
- WT_INSERT_HEAD,顾名思义,需要新增的数据都存在这个里面。
- WT_UPDATE,有更新的数据存在这个结构中。
这两个结构都是在这个union的联合体成员u2中,对于行存储的数据库来说,直接关注里面的row_leaf。直接有两个宏定义:
#define mod_row_insert u2.row_leaf.insert
#define mod_row_update u2.row_leaf.update
跳表
在wiredtiger里面,需要插入的数据是通过跳表结构来维护的。这里先说一下这个跳表结构是个啥,这样才能更好的去理解这两个结构。
跳表简单的来说就是索引。
- 首先来看一个一般的排序好的链表结构:

在这个结构中,如果需要访问key=11的元素,就需要从Head位置一个一个的进行遍历。如果这个链表结构比较长的话,访问链表中的元素是比较耗时的。如果需要提高访问速度的话,我们就再加一层索引链表:
- 加上一层索引链表后的结构

加上一层索引的链表后如果需要访问key=11的元素,就可以从1跳到7后,然后再从7往后走一个就到了。
- 还可以继续加

如果要访问key=18以后的元素,从二层索引走就会更快了。
当然,这样的结构在有插入和删除的操作时会有一些额外的操作。这样可以一跳一跳往后走的结构就叫做跳表。
WT_INSERT_HEAD
这个结构从名字上就可以看出来,这是为了插入数据的时候准备的。
/*
\* WT_INSERT_HEAD --
\* The head of a skiplist of WT_INSERT items.
*/
struct __wt_insert_head {
WT_INSERT *head[WT_SKIP_MAXDEPTH]; /* first item on skiplists */
WT_INSERT *tail[WT_SKIP_MAXDEPTH]; /* last item on skiplists */
};
参考上面的跳表结构,这个WT_INSERT_HEAD结构就是包含了所有层级的索引加真实数据,比如WT_INSERT *HEAD[0]就是最上面的一级索引,HEAD[1]就是下一级,一直到最下面。在源码里定义了这个层级的最大数:
#define WT_SKIP_MAXDEPTH 10
除了设置每级索引的头指针,还定义了每级索引的尾指针,我看后面的结构里没有双向指针,这个尾指针应该是用于比对是否已经到了每级链表的尾部了。
WT_INSERT_HAED结构里的head数组中的每一个都是指向WT_INSERT的指针,也就是说这个WT_INSERT是上述跳表中的链表节点。
看一下源码中的WT_INSERT结构:
struct __wt_insert {
WT_UPDATE *upd; /* value */
union {
uint64_t recno; /* column-store record number */
struct {
uint32_t offset; /* row-store key data start */
uint32_t size; /* row-store key data size */
} key;
} u;
#define WT_INSERT_KEY_SIZE(ins) (((WT_INSERT *)(ins))->u.key.size)
#define WT_INSERT_KEY(ins) ((void *)((uint8_t *)(ins) + ((WT_INSERT *)(ins))->u.key.offset))
#define WT_INSERT_RECNO(ins) (((WT_INSERT *)(ins))->u.recno)
WT_INSERT *next[0]; /* forward-linked skip list */
};
总共就是3个成员变量:
- 一个WT_UPDATE结构,用于保存需要插入的数据
- 一个key值,union结构中的key部分。这个key包含两个部分:
- offset,用于记录这个数据需要插入的位置。
- size
- 还有就是指向下一个节点的指针。
key和下一节点的指针都好理解,再重点看一下WT_UPDATE这个结构,这个结构在WT_PAGE_MODIFY中和WT_INSERT_HEADER是并列的。
WT_UPDATE
这个结构是用于更新的数据结构。
struct __wt_update {
volatile uint64_t txnid; /* transaction ID */
wt_timestamp_t durable_ts; /* timestamps */
wt_timestamp_t start_ts;
WT_UPDATE *next; /* forward-linked list */
uint32_t size; /* data length */
\#define WT_UPDATE_INVALID 0 /* diagnostic check */
\#define WT_UPDATE_MODIFY 1 /* partial-update modify value */
\#define WT_UPDATE_RESERVE 2 /* reserved */
\#define WT_UPDATE_STANDARD 3 /* complete value */
\#define WT_UPDATE_TOMBSTONE 4 /* deleted */
uint8_t type; /* type (one byte to conserve memory) */
/* If the update includes a complete value. */
\#define WT_UPDATE_DATA_VALUE(upd) \
((upd)->type == WT_UPDATE_STANDARD || (upd)->type == WT_UPDATE_TOMBSTONE)
volatile uint8_t prepare_state; /* prepare state */
/* AUTOMATIC FLAG VALUE GENERATION START 0 */
\#define WT_UPDATE_DS 0x01u /* Update has been written to the data store. */
\#define WT_UPDATE_FIXED_HS 0x02u /* Update that fixed the history store. */
\#define WT_UPDATE_HS 0x04u /* Update has been written to history store. */
\#define WT_UPDATE_PREPARE_RESTORED_FROM_DS 0x08u /* Prepared update restored from data store. */
\#define WT_UPDATE_RESTORED_FAST_TRUNCATE 0x10u /* Fast truncate instantiation */
\#define WT_UPDATE_RESTORED_FROM_DS 0x20u /* Update restored from data store. */
\#define WT_UPDATE_RESTORED_FROM_HS 0x40u /* Update restored from history store. */
uint8_t flags;
uint8_t data[]; /* start of the data */
};
- txn是事务ID,在CRUD的过程中会提到。
- 用于指向下一个更新数据的next指针(用于保存多次修改,因为都是需要缓存的)。
- 保存数据的字节数组:data[]
- 数据长度,也就是这个数组的长度size。
在跳表的结构上看一下,保存插入数据的数据结构大概是这么个样子(在wiredtiger里面,可以
不是一个简单的数字,这么写更好理解一点):

WT_BTREE
上面是基本结构,然后还有一个WT_BTREE结构,这个结构很大。我挑几个放出来:
struct __wt_btree {
WT_DATA_HANDLE *dhandle;
WT_CKPT *ckpt;
WT_REF root; /* Root page reference */
WT_BM *bm; /* Block manager reference */
WT_REF *evict_ref; /* Eviction thread's location */
...
}
- 一个WT_REF结构的root成员。
- 一个WT_BM的block manager结构,这是一个函数指针集合,操作的对象是WT_BLOCK结构,定义在block.h头文件中。这个结构也是用于读写和checkpoint的,后续再说。
- 一个WT_CKPT结构,用于保存checkpoint,这个结构后续要多次提到,这里就不列举了。
- 一个evict_ref成员,这个也是和内存的换入换出相关,后面再提。















 6086
6086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











