






点击上方“Python共享之家”,进行关注
回复“资源”即可获赠Python学习资料
今
日
鸡
汤
天阶夜色凉如水,卧看牵牛织女星。
大家好,我是黑脸怪。今天给大家分享pin嘻嘻逆向。
分析网址:'aHR0cHM6Ly9tbXMucGluZHVvZHVvLmNvbS9nb29kcy9nb29kc19saXN0'
1.介绍-为什么要逆向anti-content参数
用代码访问后台数据不带anti参数的话会提示“访问频繁”,所以需要逆向出这个参数!
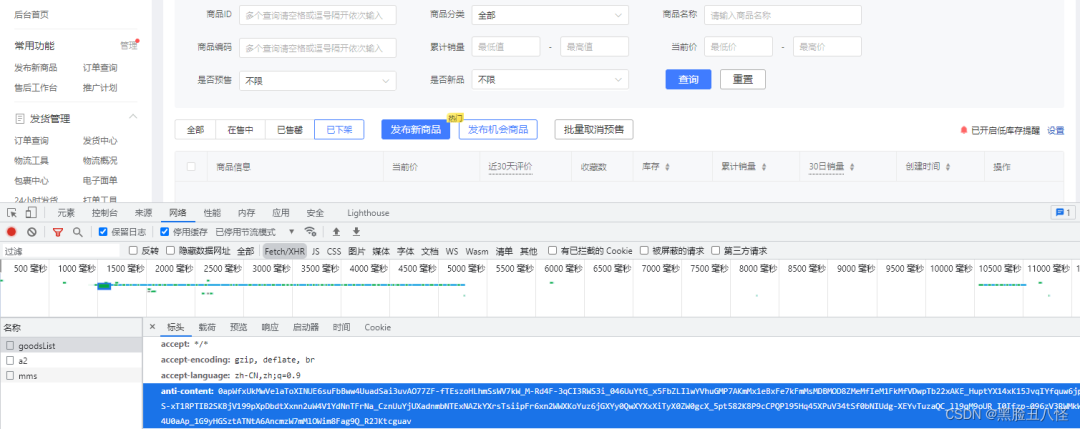
2.开始逆向js
2.1 找参数所在位置-先在控制台全局搜索参数名字
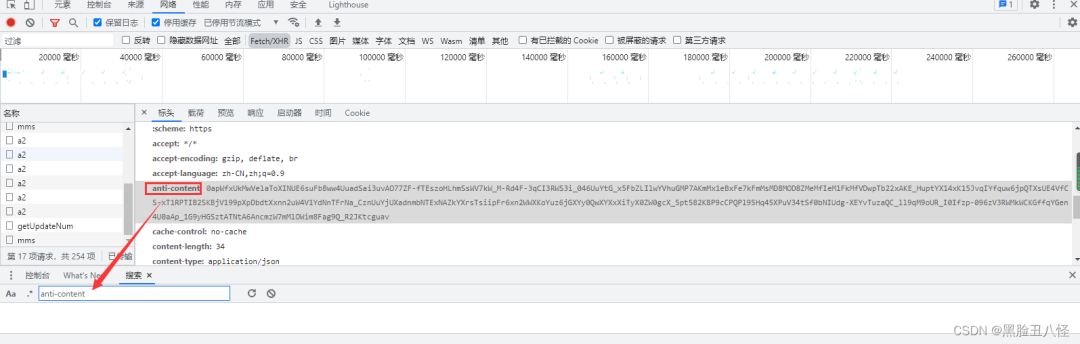
搜索出来10个结果 不算多,每个都点进去 在差不多的关键词位置打上断点先。
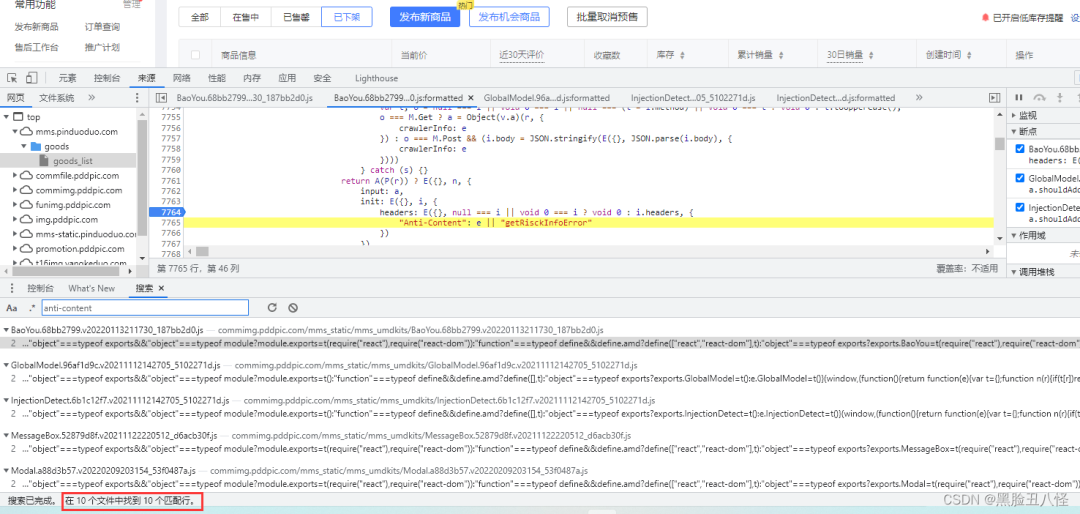
因为它Ajax请求每个页面都要anti参数 所以我们下断点之后随便点个按钮都能用 已经断下来了,这个aa1d开头的js文件(你们的不一定叫这名),可以把其他断点取消了,现在来着重分析这个。
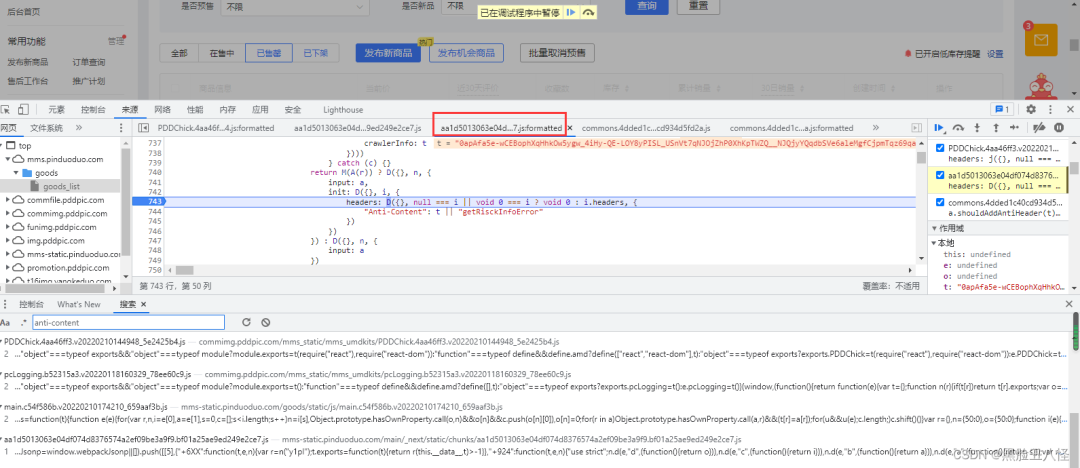
2.2 跟栈-找加密的方法
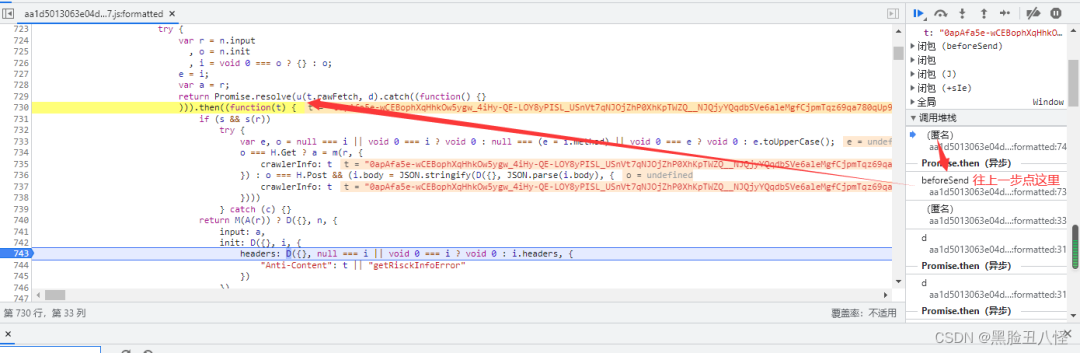
这里是一个异步代码调用,我们把断点打到它上一层这里先。
return Promise.resolve(u(t.rawFetch, d).catch((function() {}直接f8放过去 再重新点一次 会到达上面那个断点
f11单步调试进来 会跟到这里
getCrawlerInfo: function(t) {
return Promise.resolve(G((function() {
var e = I.a.getInstance(t);
return Promise.resolve(e.getServerTime()).then(F)
}
), (function() {
return ""
}
)))
}对于异步不太懂的 我这里强行演示一波 (百度小抄一下改改)
//1. Promise.resolve("111")
Promise.resolve("111")
//Promise {<fulfilled>: '111'}
// [[Prototype]]: Promise
// [[PromiseState]]: "fulfilled" 这是完成的状态
// [[PromiseResult]]: "111" 这是结果
//2.Promise.resolve("").then(函数())
Promise.resolve("我是参数?").then(function(a){console.log("111",a);return "123"})
//111 我是参数?
//Promise {<fulfilled>: '123'}
// [[Prototype]]: Promise
// [[PromiseState]]: "fulfilled"
// [[PromiseResult]]: "123"所以e是时间戳,f是主要函数 下断点到这 f8直接过来 再单步两次到F
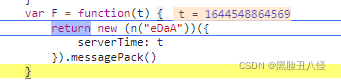
要的是里面的这串代码 :new一个对象 对象传入一个包含serverTime的对象这里我也不太理解 最后messagePack肯定就是方法了。。。不管他直接复制在控制台跑一下出结果了。
new (n("eDaA"))({
serverTime: t
}).messagePack()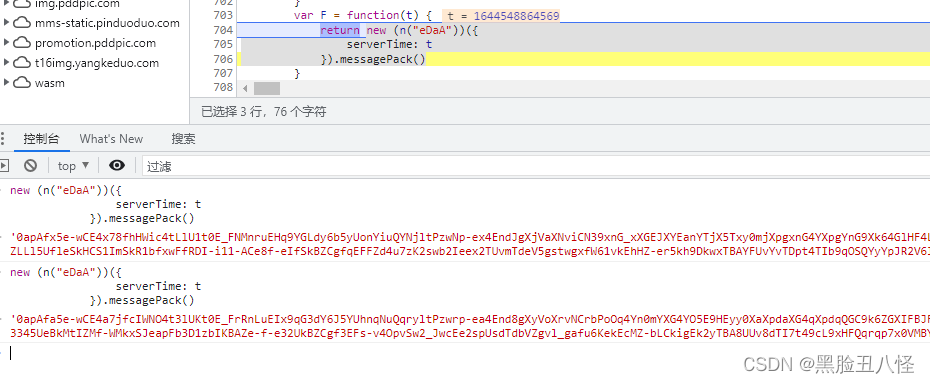
2.3 代码分析
n("eDaA") 我第一眼看这不就是个webpack吗 当时觉得还是以前的玩法 找到n方法的加载器 再复制eDaA这个模块就可以跑了。没想到跟进去发现 eDaA里面又是一个加载器和模块 第一次见到这样的 没玩过,研究了半天
eDaA导出fbeZ fbeZ又导出里面的整个webpack
所以最后我们只要fbeZ里面的webpack 跳过第一层直接取它, 因为它是第二层的 加载器不适用,需要找个通用的加载器
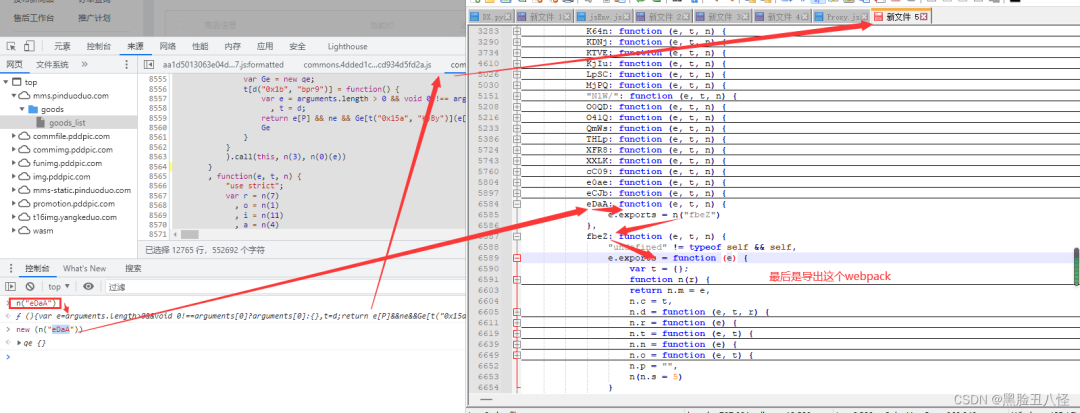
下面的加载器可以输出"111"就行
window=global;
!(function (e) {
var i = {}
, o = {
index: 0
}
function c(t) {
if (i[t])
return i[t].exports;
var n = i[t] = {
i: t,
l: !1,
exports: {}
};
// console.log(t)
return e[t].call(n.exports, n, n.exports, c),
n.l = !0,
n.exports
}
window.hliang1 = c
}
)([
function(e,t,n){
console.log("111")
}
])
window.hliang1(0)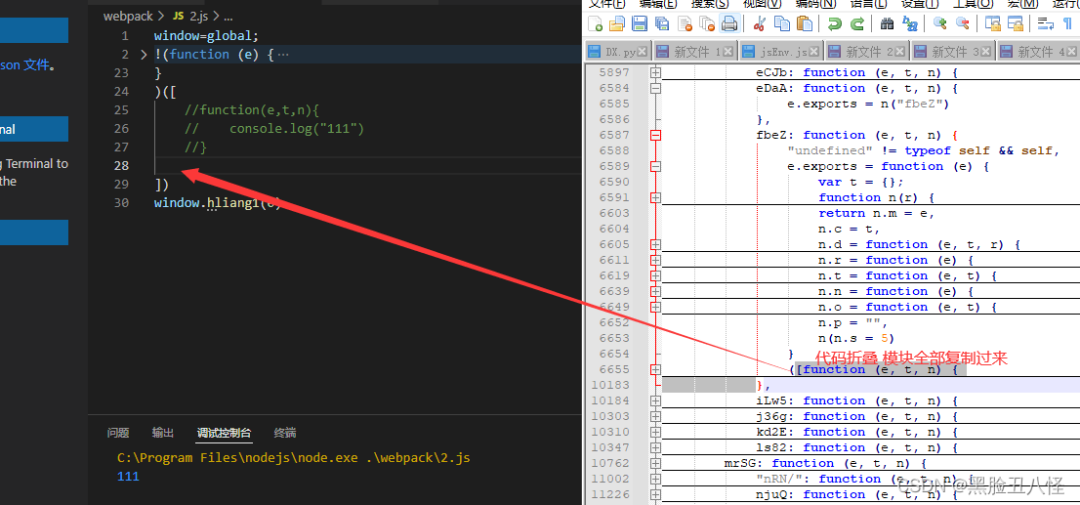
复制过来后 把前面列表的[和屁股后面的}]删除掉一个 因为会复制多
因为用notepad++代码格式化的问题,有一个模块会提示代码有问题
去网站重新粘贴一下这串代码到vscode(pycharm)
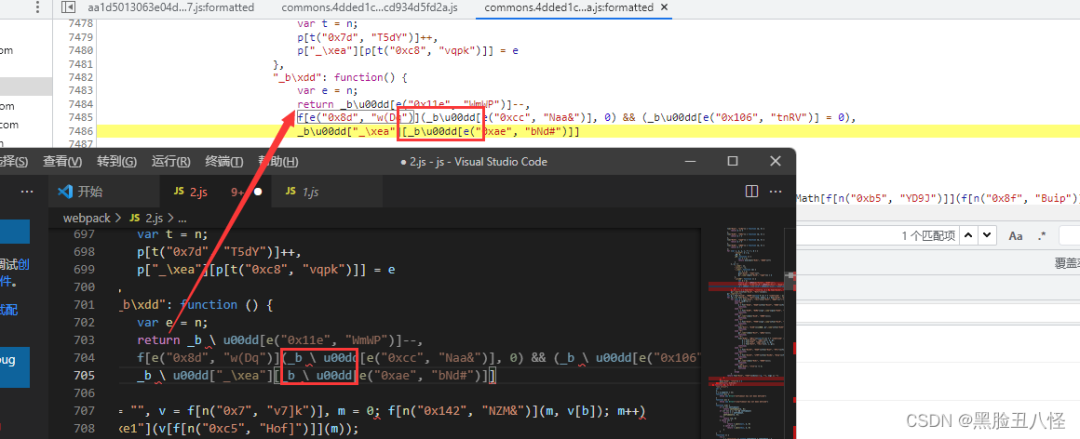
这样就完成了,用window.hliang1 就可以调用模块了
下面开始复制qe对象
它new 的qe对象就在模块里面啊,我不知道怎么直接new 所以新建了一个函数 然后对它改写
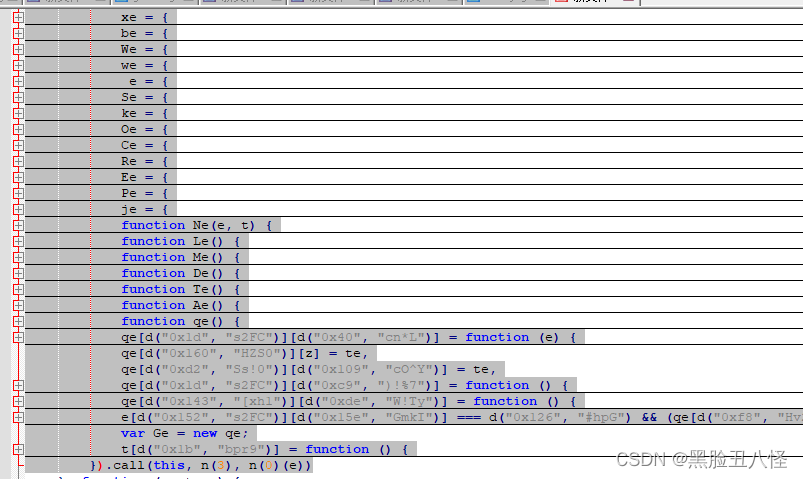
全部复制下来
function hliang_qe(){
//复制进这里来
}(function (e, t) {}).call(this,a,b) 这种就是 把a,b传参到e,t
所以改写 匿名删除去掉,.call去掉,传参的e,t直接设置成
var e=window.hliang1(3) 还有其他地方n() 这里加载器名字改一下
t原本的作用是导出(t.exports)那我这里不要t了 直接导出改成return
如下图
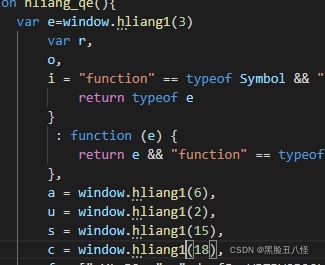
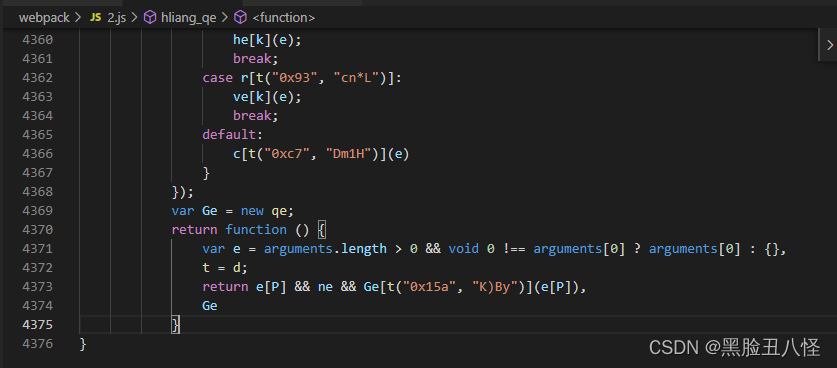
复制到浏览器执行,成功出结果。但是这个代码在node.js还需要补环境和改环境。
3.环境检测
在浏览器能跑 在node.js跑不了 需要补环境。
这都啥报错啊,看不懂。 先上环境吧。
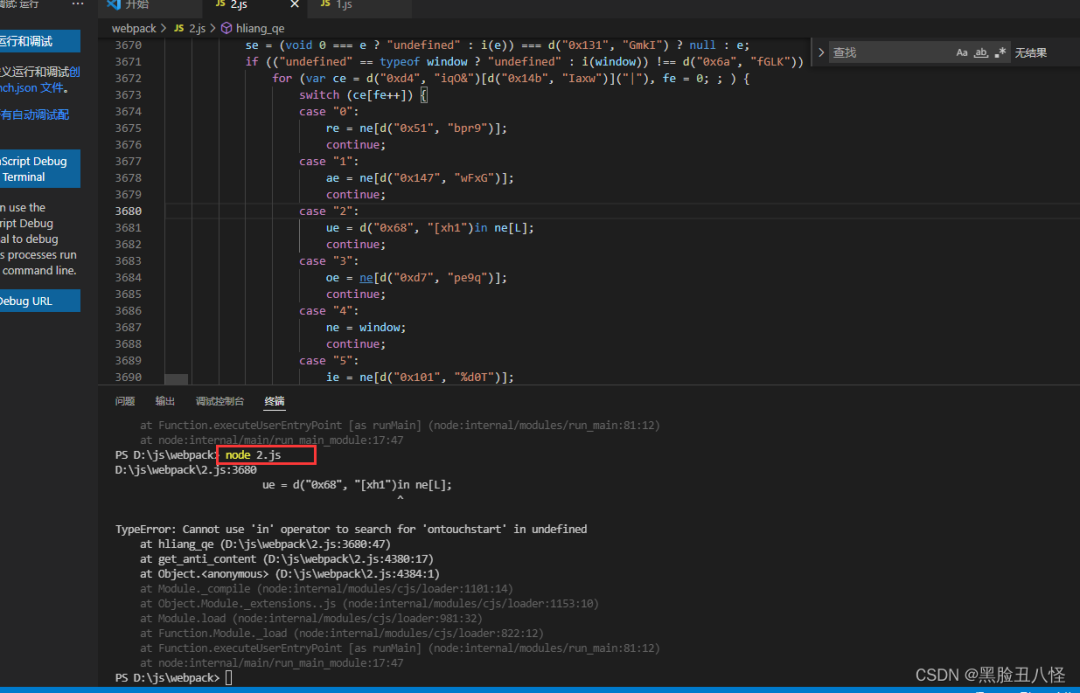
算了懒得写了。
直接告诉你们要补啥吧。
cookie和localStorage.Item传入自己的就行了 过期的也没事
window = global
document={
addEventListener:function addEventListener(a,b){
// console.log("addevent",a,b)
return undefined
},
referrer:'',
getElementById:function getElementById(a){
console.log("getbyid",a)
return "<head></head>"
},
cookie:''//这里传一个自己的cookie 过期了的也没事
}
var Plugins={0:{}}
navigator={
webdriver:false,
plugins: Plugins,
languages:["zh-CN","zh"],
hasOwnProperty:function hasOwnProperty(a){
// console.log(a,"hasOwnProperty");
if (a=="webdriver"){
return false
}
},
userAgent:"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36"
}
screen={availWidth:1920,availHeight:1040}
history={
back:function back(){console.log("back",arguments)}
}
location={
href:"https://mms.pinduoduo.com/goods/goods_list",
port:""
}
chrome={}
localStorage={
getItem:function getItem(a){
// console.log("item",arguments)
if (a=="_nano_fp"){
return "" //这里也传一个自己的
}
}
}
window["chrome"]=chrome
window["location"]=location
window["navigator"]=navigator
window["history"]=history
window["document"]=document
window["screen"]=screen
window["localStorage"]=localStorage
Object.defineProperty && Object.defineProperty(window, "outerHeight", {
value: 1040,
writable: false
});
Object.defineProperty && Object.defineProperty(window, "outerWidth", {
value: 1920,
writable: false
});
function DeviceOrientationEvent(){
console.log("DeviceOrientationEvent",arguments)
}
window["DeviceOrientationEvent"]=DeviceOrientationEvent
function DeviceMotionEvent(){
console.log("DeviceMotionEvent",arguments)
}
window["DeviceMotionEvent"]=DeviceMotionEvent
//delete window.Buffer //e("0x3c", "anZ%")
document.getElementById.toString=function(){
return 'function getElementById() { [native code] }'
}可以了。环境+上面的代码就能跑了
{"success":true,"errorCode":1000000,"errorMsg":null,"result":{"sessionId":"e70ae011c9c64f8fbf0e70fada362385","total":0,"goods_list":[]}}演示地址:
http://z.hl98.cn/index.php?share/file&user=102&sid=CiAXx7ry小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









