







1,索引结构的推理
索引由root(根块),branch(茎块)和leaf(叶子块)三部分组成,其中leaf(叶子块)主要存储key column value(索引列具体值),以及能具体定位到数据块所在位置的rowid(注意区分数据块和索引块)。
有一张test表,该表大致有name(varchar2(20)),id(number),height(number),age(number)等字段。当前该表有记录,我们要对test表的id列建索引,即create index idx_id on test(id);执行这个动作后,会发生哪些变化呢?
1,要建索引先排序
未建索引的test表大致记录如下图所示,null表示该字段为空值,此外省略号表示略去不显示的内容。注意rowid伪列,这个是每一行的唯一标识,每一行的rowid值绝对不重复,由它可定位到行的记录在数据库中的位置。
| name | age | height | id | 伪列 |
|---|---|---|---|---|
| 小余 | ...... | ...... | 100000 | rowid |
| 老张 | ...... | ...... | 5 | rowid |
| 老王 | ...... | ...... | 3 | rowid |
| 小马 | ...... | ...... | 1 | rowid |
| 大刘 | ...... | ...... | 4 | rowid |
| 小明 | ...... | ...... | rowid | |
| 小黄 | ...... | ...... | 2 | rowid |
| 老李 | ...... | ...... | 7 | rowid |
| ...... | ...... | ...... | ...... | ...... |
| ...... | ...... | ...... | 6 | ...... |
建索引后,先从test表的id列由小到大顺序取出数据放到内存中(这里要注意,除了id列的值外,还要注意取该列值的同时,该行的rowid也一并取出)。

2,列值入块成索引
一次将内存中顺序存放的列值和对应的rowid存进oracle空闲的block中,形成索引块,具体如下图所示:
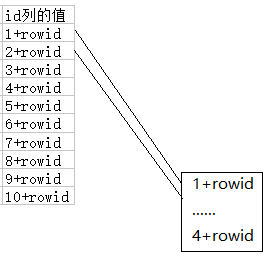
3,填满一块又一块
随着索引列的值不断插入,index block(L1)很快就被插满了,比如接下来取出的id=9的记录将无法插入index block(L1)中,只有插入到新的oracle块中,如下图所示的index block2(L2)。与此同时,发生了一件非常重要的事情,就是写新数据到另一个块index block3(B1),这是为啥呢?原来L1和L2平起平坐,谁都不服谁,于是index block3(B1)就负担起管理IDE角色,这个block记录了L1和L2的信息,并不记录具体的索引列的键值,目前只占用了B1的一点点空间。具体细节如下:
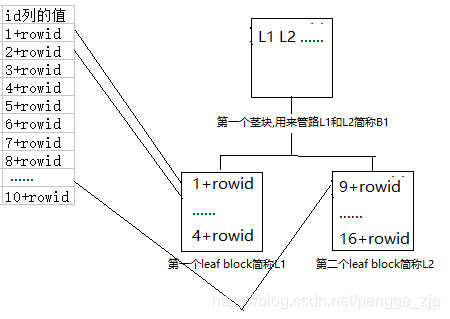
4,同级两块需人管
随着叶子块的不断增加,B1快中虽然仅存放叶子块的标记,但也挡不住量大,最终也容纳不下了。就到下一个B2块中寻找空间容纳。这时B1和B2也平起平坐了,谁都不服谁。接着,最上层的root根块就诞生了。后续还会出现B3,B4,。。。如果有一天,这些Bn把root块撑满了,root块就不是root块了,它也要被人管着,它额的上面又有了领导了。
通过上面的4个步骤,索引的结构是什么样子,终于可以一清二楚了。
2,索引特性的提炼
通过上述的索引结构推论,我们其实可以得出非常重要,非常实用的三大特性:
1,索引高度低
首先我们从上往下看,最底层的叶子块index block因为装具体额的数据,所以比较容易被填满,特别是对长度很长的列建索引时更是如此。但是第一层之上的第二层的index block就很不容易装满了吧,因为第二层只是装第一层的指针而已,而第三层装第二层的index block的指针,更不容易被填满了。
2,索引存储列值
接下来我们从里往外看,我们很清楚,索引块就是存放索引的列值以及对应的rowid,这里的rowid也是非常重要的,要想通过定位到的索引信息再返回到表中查到具体的其他列值信息,还非得靠这个rowid。
3,索引本身有序
最后我们从左往右看,可以发现索引是按顺序从表里取出数据,再按顺序插入到块里形成索引块的。所以说索引块是有序的。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









