







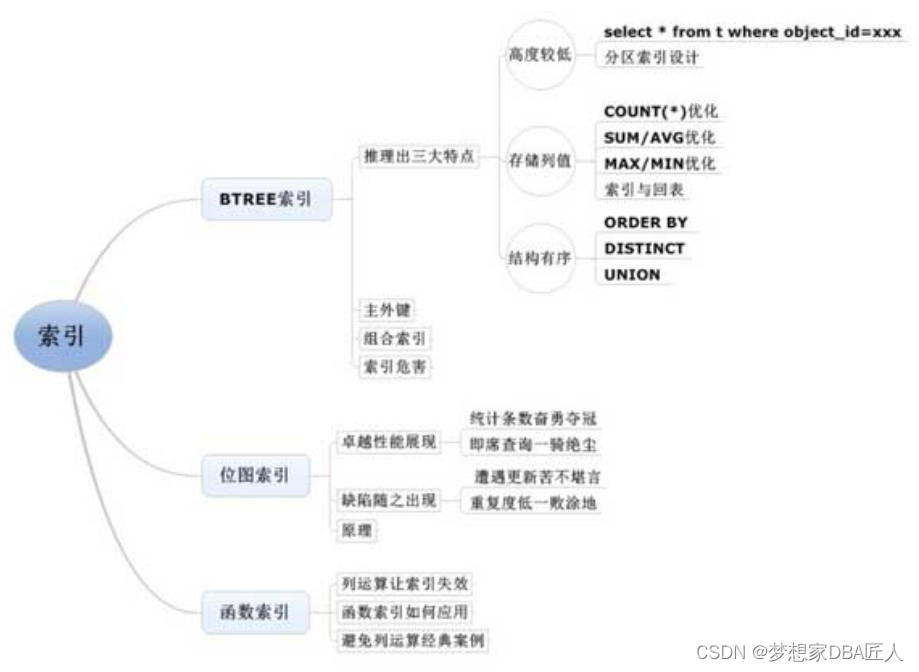
1.索引知识图框
2.索引探秘
2.1 BTREE索引
索引是建在表的具体列上的,其存在的目的是让表的查询变得更快,效率更高。表记录丢失关乎生死,而索引丢失只需重建即可。
索引却是数据库学习中最实用的技术之一。谁能深刻地理解和掌握索引的知识,谁就能在数据库相关工作中事半功倍。在了解索引之前,我们需要先了解索引结构长什么样。
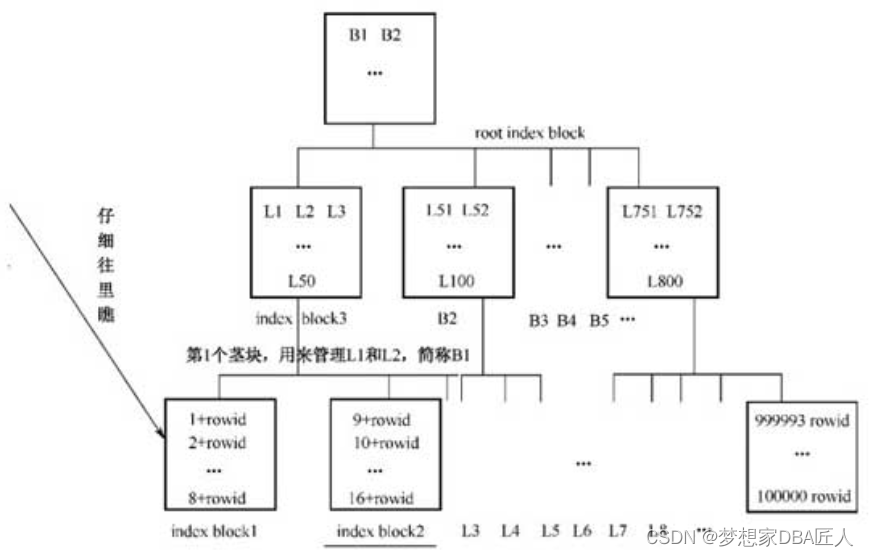
索引结构图
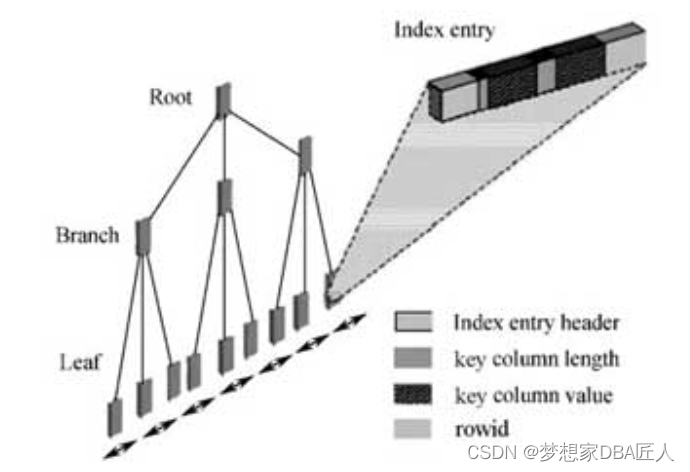
索引结构图说明索引是由Root(根块)、Branch(茎块)和Leaf(叶子块)三部分组成的,其中Leaf(叶子块)主要存储了key column value(索引列具体值),以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
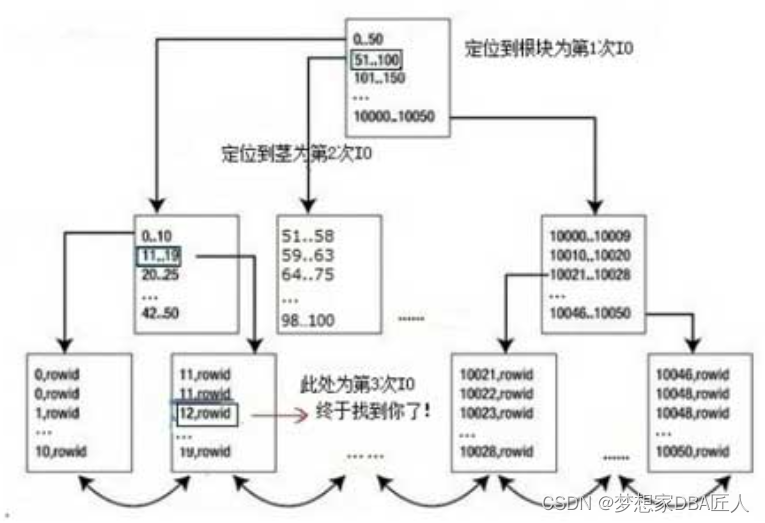
具体说说某个Oracle的索引查询吧,如:select * from t where id=12;,该t表的记录有10 050条,而id=12仅返回1条,在t表的id列上创建了一个索引,索引是如何快速检索到数据的呢?
首先查询定位到索引的根部,这是第1次IO;接下来根据根块的数据分布,定位到索引的茎部(查询到12的值的大致范围,在11..19的部分),这是第2次IO;然后定位到叶子块,找到 id=12的部分,此处为第3次 IO。假设 Oracle 在全表扫描记录,遍历所有的数据块,IO的数量必然将大大超过3次。有了这个索引,Oracle只会去扫描部分索引块,而非全部,少做事,必然能大大提升性能。
Leaf(叶子块)主要存储key column value(索引列具体值)以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
2.2 到底是物理结构还是逻辑结构
物理结构可以理解为真正存在根、茎、叶的块。而逻辑结构可以理解为并没有存在根、茎的块,只是一种指针或者说一种内部算法。
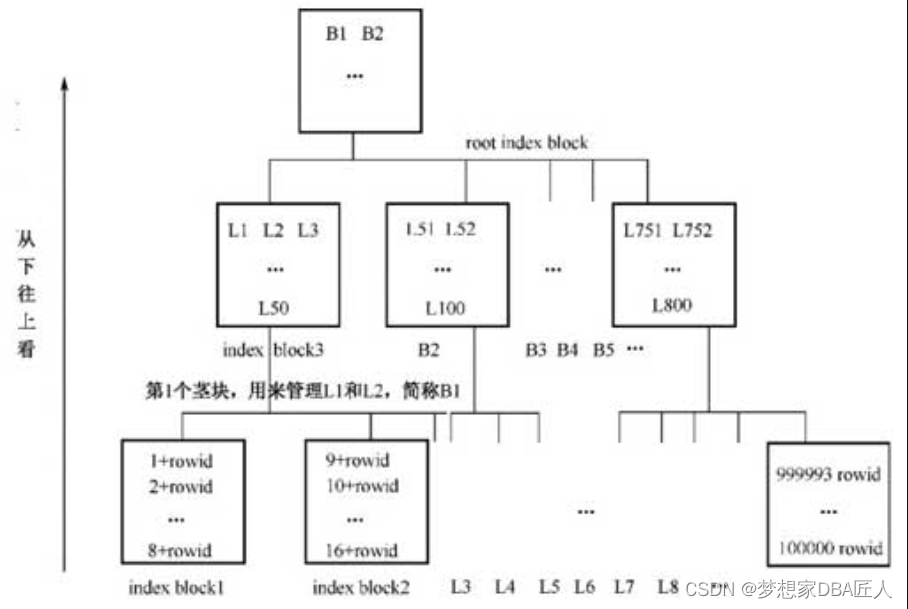
1.要建索引先排序
未建索引的test表中的记录大致如图5-4所示,NULL表示该字段为空值,此外省略号表示略去不显示内容。注意rowid伪列,这是每一行的唯一标记,每一行的rowid 值绝对不重复,它可将行的记录定位到数据库中的位置。建索引后,将test表中id列的值按顺序取出放在内存中(这里需注意,除了id列的值外,还要注意取该列的值的同时,该行的rowid也被一并取出)。
2.列值入块成索引
依次将内存中顺序存放的列值和对应的rowid存进Oracle空闲的块中,形成索引块。
3.填满一块接一块
随着索引列的值的不断插入,index block1(L1)很快就被插满了。比如接下来取出的 id=9的记录无法插入index block1(L1)中,就只能插入新的块中,插入如图5-7所示的index block2(L2)。
4.同级两块需人管
随着叶子块的不断增加,B1块中虽然仅是存放叶子块的标记,但也挡不住量大,最终也容纳不下了。怎么办?接着装呗,到下一个块B2中去寻找空间容纳。
2.3 索引结构的三大重要特点
2.3.1.索引高度较低
2.3.2.索引存储列值
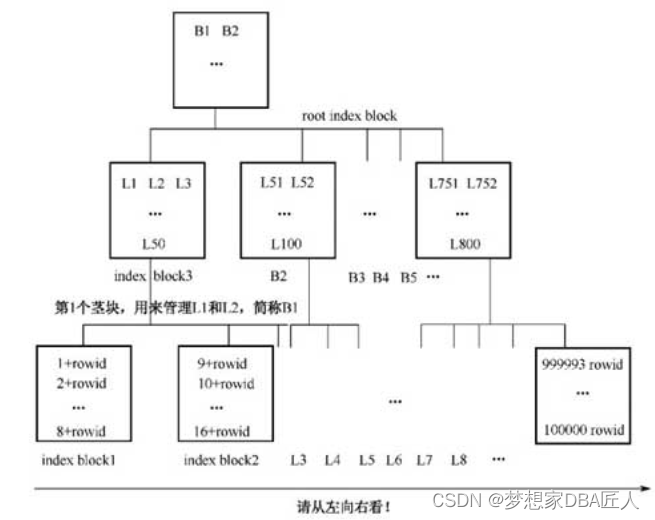
2.3.3.索引本身有序
索引的三大特点:
① 索引树的高度一般都比较低。
② 索引由索引列存储的值及rowid组成。
③ 索引本身是有序的。
索引从左向右看
2.4 妙用三特征之高度较低
2.4.1索引高度较低验证
① 构造一系列表t1到t6,记录数从5到50万依次以10倍的差额逐步增大
做索引高度较低试验前的构造表操作
SQL> show user
USER is "MAXWELLPAN"
SQL> drop table t1 purge;
drop table t1 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t2 purge;
drop table t2 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t3 purge;
drop table t3 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t4 purge;
drop table t4 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t5 purge;
drop table t5 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t6 purge;
drop table t6 purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL>
SQL> create table t1 as select rownum as id,rownum+1 as id2 from dual connect by level<=5;
Table created.
SQL> create table t2 as select rownum as id,rownum+1 as id2 from dual connect by level<=50;
Table created.
SQL> create table t3 as select rownum as id,rownum+1 as id2 from dual connect by level<=500;
Table created.
SQL> create table t4 as select rownum as id,rownum+1 as id2 from dual connect by level<=5000;
Table created.
SQL> create table t5 as select rownum as id,rownum+1 as id2 from dual connect by level<=50000;
Table created.
SQL> create table t6 as select rownum as id,rownum+1 as id2 from dual connect by level<=500000;
Table created.
SQL>
② 分别对ID列建索引
继续完成建索引的准备工作
SQL>
SQL> create index idx_id_t1 on t1(id);
Index created.
SQL> create index idx_id_t2 on t2(id);
Index created.
SQL> create index idx_id_t3 on t3(id);
Index created.
SQL> create index idx_id_t4 on t4(id);
Index created.
SQL> create index idx_id_t5 on t5(id);
Index created.
SQL> create index idx_id_t6 on t6(id);
Index created.
SQL> 观察比较各个索引的大小
SQL> column segment_name format a20
SQL> select segment_name,bytes/1024
2 from user_segments
3 where segment_name in ('IDX_ID_T1','IDX_ID_T2','IDX_ID_T3','IDX_ID_T4','IDX_ID_T5','IDX_ID_T6');
SEGMENT_NAME BYTES/1024
-------------------- ----------
IDX_ID_T1 64
IDX_ID_T2 64
IDX_ID_T3 64
IDX_ID_T4 128
IDX_ID_T5 1024
IDX_ID_T6 9216
6 rows selected.
SQL>但是在统计索引高度时,我们观察发现这些索引的高度相差无几,记录数最小是5条,最大是50万条,而高度最小的是BLEVEL=0,表示1层,高度最大的是BLEVEL=2,表示3层,也就差了2层而已!
观察比较各个索引的高度
SQL> column index_name format a20
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_statistics
8 where table_name in ('T1','T2','T3','T4','T5','T6')
9 order by index_name;
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_ID_T1 0 1 5 5 1
IDX_ID_T2 0 1 50 50 1
IDX_ID_T3 1 2 500 500 1
IDX_ID_T4 1 11 5000 5000 9
IDX_ID_T5 1 110 50000 50000 101
IDX_ID_T6 2 1113 500000 500000 1035
6 rows selected.
SQL> 注意一下:其中BLEVEL表示高度,0表示第一个块还没被索引装满,没产生管理的索引块,这个0可以理解为高度是1层,1则表示高度为2层,以此类推。
上面下面,为什么IDX_ID_T1、IDX_ID_T2、IDX_ID_T3三个索引一样大啊,都是64KB,它们的表记录可是5、50和500啊?
数据库的最小单位虽然是块,但是最小的空间分配单位却是区,要存在一个段至少需要一个区,你说的三个索引,就是三个索引段。
比如一个区含有8个块,一个块有8KB,段的最小空间就是64KB了,这是预分配的空间,即便是建一张空表,大小也是64KB。在空表上建一个索引,这个索引大小还是64KB,表和索引的实际大小只要不超过64KB,数据库查询都是64KB这么大,因为一次性已经分配给你一个区的大小了。但是一旦超过64KB,即便超过一点点,分配到的空间可能马上就是128KB这么大了。
2.4.2 妙用索引高度较低的特性
我们建了6张表,其中t5表有5万条记录,而t6表有50万条记录。大家说说这两条查询语句 select * from t5 where id=10 和select *from t6 where id=10,它们都是返回一条记录,但是t6表的记录数是t5表的10倍,它们的查询速度会不会差别很大?
观察上述与t5、t6 表相关的索引扫描的性能
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL> select * from t5 where id=10;
Elapsed: 00:00:00.12
Execution Plan
----------------------------------------------------------
Plan hash value: 2977381114
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T5 | 1 | 10 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID_T5 | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=10)
Statistics
----------------------------------------------------------
395 recursive calls
6 db block gets
462 consistent gets
1 physical reads
1064 redo size
624 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
43 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL>
SQL>
SQL> select * from t6 where id=10;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 661597417
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T6 | 1 | 10 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID_T6 | 1 | | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=10)
Statistics
----------------------------------------------------------
341 recursive calls
6 db block gets
380 consistent gets
3 physical reads
964 redo size
624 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
40 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>这两个试验表明虽然一张表是5万条记录,另一张表是50万条记录,但是利用索引来返回同样记录数的查询,效率居然差不多?
主要是BLEVEL有关,产生的IO次数有点差别。速度相对也会有差别。
再次测试与t5、t6表相关的全表扫描查询的性能
SQL>
SQL> drop index IDX_ID_T5;
Index dropped.
Elapsed: 00:00:00.25
SQL> select * from t5 where id=10;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 2002323537
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 32 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T5 | 1 | 10 | 32 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=10)
Statistics
----------------------------------------------------------
30 recursive calls
0 db block gets
155 consistent gets
0 physical reads
0 redo size
620 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> drop index IDX_ID_T6;
Index dropped.
Elapsed: 00:00:00.13
SQL> select * from t6 where id=10;
Elapsed: 00:00:00.04
Execution Plan
----------------------------------------------------------
Plan hash value: 1930642322
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 293 (2)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T6 | 1 | 10 | 293 (2)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=10)
Statistics
----------------------------------------------------------
101 recursive calls
0 db block gets
1090 consistent gets
1034 physical reads
0 redo size
620 bytes sent via SQL*Net to client
390 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 可以看出,由于删除了索引,针对t5、t6表的查询逻辑读差异明显。说明性能也是非常明显的。
由此得出结论,索引的这个高度不高的特性给查询带来了巨大的便利,但是请注意,我们的查询只返回1条记录。如果查询返回绝大部分的数据,那用索引反而要慢得多。
2.4.3 分区索引设计误区
分区表的索引分为两种,一种是局部索引,一种是全局索引。局部索引等同于为每个分区段建分区的索引,从user_segment 的数据字典中,我们可以观察到表有多少个分区,就有多少个分区索引的段。
先建分区表part_tab,插入数据,并分别在col2上建局部索引,在col3上建全局索引。
分区索引相关试验的准备工作
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table part_tab_purge;
drop table part_tab_purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.10
SQL>
SQL>
SQL> create table part_tab(id int,col2 int,col3 int)
2 partition by range(id)
3 (
4 partition p1 values less than (10000),
5 partition p2 values less than (20000),
6 partition p3 values less than (30000),
7 partition p4 values less than (40000),
8 partition p5 values less than (50000),
9 partition p6 values less than (60000),
10 partition p7 values less than (70000),
11 partition p8 values less than (80000),
12 partition p9 values less than (90000),
13 partition p10 values less than (100000),
14 partition p11 values less than(maxvalue)
15 )
16 ;
Table created.
Elapsed: 00:00:00.05
SQL>
SQL> insert into part_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <= 110000;
110000 rows created.
Elapsed: 00:00:00.14
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL>
SQL> create index idx_par_tab_col2 on part_tab(col2) local;
Index created.
Elapsed: 00:00:00.15
SQL> create index idx_par_tab_col3 on part_tab(col3);
Index created.
Elapsed: 00:00:00.09
SQL>分区索引情况查看
SQL> col segment_name format a20
SQL> col partition_name format a20
SQL> col segment_type format a20
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'PART_TAB';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
PART_TAB P1 TABLE PARTITION
PART_TAB P10 TABLE PARTITION
PART_TAB P11 TABLE PARTITION
PART_TAB P2 TABLE PARTITION
PART_TAB P3 TABLE PARTITION
PART_TAB P4 TABLE PARTITION
PART_TAB P5 TABLE PARTITION
PART_TAB P6 TABLE PARTITION
PART_TAB P7 TABLE PARTITION
PART_TAB P8 TABLE PARTITION
PART_TAB P9 TABLE PARTITION
11 rows selected.
Elapsed: 00:00:00.06
SQL>
SQL>
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'IDX_PAR_TAB_COL2';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
IDX_PAR_TAB_COL2 P1 INDEX PARTITION
IDX_PAR_TAB_COL2 P10 INDEX PARTITION
IDX_PAR_TAB_COL2 P11 INDEX PARTITION
IDX_PAR_TAB_COL2 P2 INDEX PARTITION
IDX_PAR_TAB_COL2 P3 INDEX PARTITION
IDX_PAR_TAB_COL2 P4 INDEX PARTITION
IDX_PAR_TAB_COL2 P5 INDEX PARTITION
IDX_PAR_TAB_COL2 P6 INDEX PARTITION
IDX_PAR_TAB_COL2 P7 INDEX PARTITION
IDX_PAR_TAB_COL2 P8 INDEX PARTITION
IDX_PAR_TAB_COL2 P9 INDEX PARTITION
11 rows selected.
Elapsed: 00:00:00.09
SQL>
SQL> select segment_name,partition_name,segment_type
2 from user_segments
3 where segment_name = 'IDX_PAR_TAB_COL3';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------------- -------------------- --------------------
IDX_PAR_TAB_COL3 INDEX
Elapsed: 00:00:00.03
SQL>
建一张普通表norm_tab,字段和记录数与part_tab一样,并且同样在col2和col3上分别建索引.
继续做准备工作,构建普通表及索引
SQL>
SQL> drop table norm_tab purge;
drop table norm_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.08
SQL> create table norm_tab(id int,col2 int,col3 int);
Table created.
Elapsed: 00:00:00.03
SQL> insert into norm_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <= 110000;
110000 rows created.
Elapsed: 00:00:00.16
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL> create index idx_nor_tab_col2 on norm_tab(col2);
Index created.
Elapsed: 00:00:00.11
SQL> create index idx_nor_tab_col3 on norm_tab(col3);
Index created.
Elapsed: 00:00:00.07
SQL>我们来看看分别针对part_tab和norm_tab两表的col2列的查询效率如何,语句分别是select* from part_tab where col2=8;和select * from norm_tab where col2=8;,依然采用set autotrace 的跟踪方式。先查看针对part_tab的查询结果,发现索引扫描遍历了全部11个分区,在执行计划中我们可以观察到,Pstart和Pstop是从1到11。
全分区索引扫描产生大量逻辑读
SQL>
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL> select * from part_tab where col2=8;
Elapsed: 00:00:00.05
Execution Plan
----------------------------------------------------------
Plan hash value: 3980401122
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 11 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE ALL | | 1 | 39 | 11 (0)| 00:00:01 | 1 | 11 |
| 2 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| PART_TAB | 1 | 39 | 11 (0)| 00:00:01 | 1 | 11 |
|* 3 | INDEX RANGE SCAN | IDX_PAR_TAB_COL2 | 1 | | 11 (0)| 00:00:01 | 1 | 11 |
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
972 recursive calls
6 db block gets
1464 consistent gets
11 physical reads
1020 redo size
698 bytes sent via SQL*Net to client
618 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
102 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 普通表索引扫描逻辑读少得多
SQL>
SQL> select * from norm_tab where col2=8;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2321776653
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| NORM_TAB | 1 | 39 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_NOR_TAB_COL2 | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
57 recursive calls
6 db block gets
164 consistent gets
2 physical reads
1008 redo size
702 bytes sent via SQL*Net to client
397 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 分别观察分区表和普通表的索引高度
SQL>
SQL> set autotrace off
SQL>
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_partitions
8 where index_name='IDX_PAR_TAB_COL2';
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_PAR_TAB_COL2 1 21 9999 9999 24
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10001 10001 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
IDX_PAR_TAB_COL2 1 23 10000 10000 28
11 rows selected.
Elapsed: 00:00:00.10
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_statistics
8 where index_name='IDX_NOR_TAB_COL2';
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
-------------------- ---------- ----------- ---------- ------------- -----------------
IDX_NOR_TAB_COL2 1 244 110000 110000 299
Elapsed: 00:00:00.21
SQL>分区索引扫描仅落在某一分区,性能大幅提升
SQL>
SQL> set autotrace traceonly
SQL> select * from part_tab where col2=8 and id=7;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2640417554
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 4 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE | | 1 | 39 | 4 (0)| 00:00:01 | 1 | 1 |
|* 2 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| PART_TAB | 1 | 39 | 4 (0)| 00:00:01 | 1 | 1 |
|* 3 | INDEX RANGE SCAN | IDX_PAR_TAB_COL2 | 11 | | 3 (0)| 00:00:01 | 1 | 1 |
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("ID"=7)
3 - access("COL2"=8)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
698 bytes sent via SQL*Net to client
406 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>5.2.6 巧用三特征之存储列值
1.count(*) 优化
(1)考虑用索引,理论很完美
COUNT(*)优化试验前的建表及建索引
SQL> conn maxwellpan/maxwellpan@PDB1
Connected.
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL>
SQL> drop table t purge;
drop table t purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> create table t as select * from dba_objects;
Table created.
SQL> create index idx1_object_id on t(object_id);
Index created.
SQL> select count(*) from t;
COUNT(*)
----------
73296
SQL> 因为表的情况和索引的情况的差别在于,表是把整行的记录依次放进块中形成数据块,而索引是把所在列的记录排序后依次放进块里形成索引块。既然在没有索引的情况下,在数据块中可以统计出表的记录数,那索引块肯定也可以。方法就是前者汇总各个在数据块中的行的插入记录数,后者汇总各个索引块中的索引列的插入记录数。
最关键的是,索引块里存放的值是表的特定的索引列,一列或者几列,所需容纳空间要比存放整行也就是所有列的数据块要少得多。假如当前这个 T 段的数据块需要几百个块来容纳,或许索引段只需几十个块就够装了。所以用索引一定高效。
(2)未料到空值,现实很残酷
COUNT(*)在索引列有空值时无法用到索引
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> set timing on
SQL> select count(*) from t;
COUNT(*)
----------
73296
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73296 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1426 consistent gets
0 physical reads
0 redo size
552 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> (3)空值有想到,生活仍美好
明确索引列非空,即可让COUNT(*)用到索引
SQL>
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> set timing on
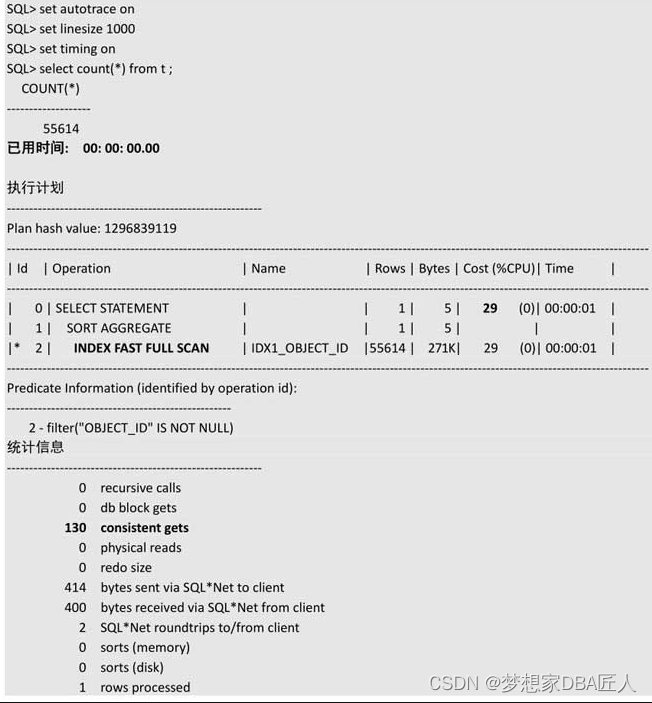
SQL> select count(*) from t where object_id is not null;
COUNT(*)
----------
73294
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 1296839119
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 46 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 73294 | 357K| 46 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJECT_ID" IS NOT NULL)
Statistics
----------------------------------------------------------
23 recursive calls
0 db block gets
172 consistent gets
162 physical reads
0 redo size
552 bytes sent via SQL*Net to client
633 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 看来我告诉Oracle此列为非空后,终于用到索引了。执行计划从原先的TABLE ACCESS FULL变化为INDEX FAST FULL SCAN,逻辑读由原先的1426减少为172,代价由原来的397减少为46,性能大大提升了!
(4)多条道路通往幸福彼岸
SQL> set pagesize 200
SQL> set linesize 200
SQL> desc t;
Name Null? Type
----------------------------------------------------------------------------------------------------------------- -------- ----------------------------------------------------------------------------
OWNER VARCHAR2(128)
OBJECT_NAME VARCHAR2(128)
SUBOBJECT_NAME VARCHAR2(128)
OBJECT_ID NUMBER
DATA_OBJECT_ID NUMBER
OBJECT_TYPE VARCHAR2(23)
CREATED DATE
LAST_DDL_TIME DATE
TIMESTAMP VARCHAR2(19)
STATUS VARCHAR2(7)
TEMPORARY VARCHAR2(1)
GENERATED VARCHAR2(1)
SECONDARY VARCHAR2(1)
NAMESPACE NUMBER
EDITION_NAME VARCHAR2(128)
SHARING VARCHAR2(18)
EDITIONABLE VARCHAR2(1)
ORACLE_MAINTAINED VARCHAR2(1)
APPLICATION VARCHAR2(1)
DEFAULT_COLLATION VARCHAR2(100)
DUPLICATED VARCHAR2(1)
SHARDED VARCHAR2(1)
CREATED_APPID NUMBER
CREATED_VSNID NUMBER
MODIFIED_APPID NUMBER
MODIFIED_VSNID NUMBER
SQL> show user;
USER is "MAXWELLPAN"
SQL> 修改OBJECT_ID列为非空

不改SQL语句,让COUNT(*)用到索引
OBJECT_ID列为主键,也可说明非空属性

(5)成功源于多角度的思考
2.SUM/AVG优化
(1)理想再次被空值击碎
SUM/AVG优化试验准备之表及索引的构建
SQL>
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> set timing on
SQL> select count(*) from t;
COUNT(*)
----------
73296
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73296 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
44 recursive calls
0 db block gets
1470 consistent gets
0 physical reads
0 redo size
552 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL>
SQL>
SQL> drop table t purge;
Table dropped.
Elapsed: 00:00:00.32
SQL> create table t as select * from dba_objects;
Table created.
Elapsed: 00:00:00.41
SQL> create index idx1_object_id on t(object_id);
Index created.
Elapsed: 00:00:00.30
SQL> 在说明索引列非空后,SUM/AVG可用到索引
SQL>
SQL> show user
USER is "MAXWELLPAN"
SQL> set autotrace on
SQL> set linesize 1000
SQL> set timing on
SQL> select sum(object_id) from t;
SUM(OBJECT_ID)
--------------
2702612882
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 1296839119
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 46 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 73296 | 357K| 46 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
44 recursive calls
0 db block gets
174 consistent gets
162 physical reads
0 redo size
560 bytes sent via SQL*Net to client
611 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>SUM、AVG、COUNT综合写法试验
SQL>
SQL> select sum(object_id),avg(object_id),count(*) from t where object_id is not null;
SUM(OBJECT_ID) AVG(OBJECT_ID) COUNT(*)
-------------- -------------- ----------
2702612882 36873.5897 73294
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 1296839119
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 46 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 73294 | 357K| 46 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJECT_ID" IS NOT NULL)
Statistics
----------------------------------------------------------
260 recursive calls
0 db block gets
479 consistent gets
0 physical reads
0 redo size
749 bytes sent via SQL*Net to client
442 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
54 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 3.MAX/MIN优化
MAX/MIN语句应用索引非常高效
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table t purge;
Table dropped.
Elapsed: 00:00:00.43
SQL> create table t as select * from dba_objects;
Table created.
Elapsed: 00:00:00.45
SQL> create index idx1_object_id on t(object_id);
Index created.
Elapsed: 00:00:00.06
SQL>
SQL> select max(object_id) from t;
MAX(OBJECT_ID)
--------------
74905
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 692082706
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX1_OBJECT_ID | 1 | 5 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
2 consistent gets
1 physical reads
0 redo size
558 bytes sent via SQL*Net to client
611 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> (2)MAX/MIN的惊天力量
测试MAX性能前的准备,构建一张大表
SQL>
SQL> create table t_max as select * from dba_objects;
Table created.
SQL> create index idx_t_max_obj on t_max(object_id);
Index created.
SQL> insert into t_max select * from t_max;
73298 rows created.
SQL> insert into t_max select * from t_max;
146596 rows created.
SQL> insert into t_max select * from t_max;
293192 rows created.
SQL> insert into t_max select * from t_max;
586384 rows created.
SQL> commit;
Commit complete.
SQL> select count(*) from t_max;
COUNT(*)
----------
1172768
SQL> 表大小差异明显,MAX/MIN的性能却几无差异
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> select max(object_id) from t_max;
MAX(OBJECT_ID)
--------------
74913
Execution Plan
----------------------------------------------------------
Plan hash value: 1235166074
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_MAX_OBJ | 1 | 13 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Note
-----
- dynamic statistics used: statistics for conventional DML
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
4 consistent gets
0 physical reads
132 redo size
558 bytes sent via SQL*Net to client
394 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select min(object_id) from t_max;
MIN(OBJECT_ID)
--------------
2
Execution Plan
----------------------------------------------------------
Plan hash value: 1235166074
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_MAX_OBJ | 1 | 13 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Note
-----
- dynamic statistics used: statistics for conventional DML
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
1 physical reads
0 redo size
556 bytes sent via SQL*Net to client
394 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> (3)MAX/MIN的性能陷阱
MIN和MAX同时写的优化(空值导致用不到索引)
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> select min(object_id),max(object_id) from t;
MIN(OBJECT_ID) MAX(OBJECT_ID)
-------------- --------------
2 74905
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | TABLE ACCESS FULL| T | 73296 | 357K| 397 (1)| 00:00:01 |
---------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1424 consistent gets
1422 physical reads
0 redo size
645 bytes sent via SQL*Net to client
626 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
MIN和MAX同时写的优化(无法用INDEX FULL SCAN(MIN/MAX))
SQL>
SQL> set autotrace on
SQL> set linesize 1000
SQL> select min(object_id),max(object_id) from t where object_id is not null;
MIN(OBJECT_ID) MAX(OBJECT_ID)
-------------- --------------
2 74905
Execution Plan
----------------------------------------------------------
Plan hash value: 1296839119
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 46 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 73294 | 357K| 46 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJECT_ID" IS NOT NULL)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
170 consistent gets
163 physical reads
0 redo size
645 bytes sent via SQL*Net to client
433 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
有趣的改写,完成了MAX/MIN同时写的最佳优化
SQL> selset autotrace on
SQL> set linesize 1000
SQL> set timing on
SQL> select max,min from (select max(object_id) max from t) a,(select min(object_id) min from t) b;
MAX MIN
---------- ----------
74905 2
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 251798682
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 26 | 4 (0)| 00:00:01 |
| 2 | VIEW | | 1 | 13 | 2 (0)| 00:00:01 |
| 3 | SORT AGGREGATE | | 1 | 5 | | |
| 4 | INDEX FULL SCAN (MIN/MAX)| IDX1_OBJECT_ID | 1 | 5 | 2 (0)| 00:00:01 |
| 5 | VIEW | | 1 | 13 | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 5 | | |
| 7 | INDEX FULL SCAN (MIN/MAX)| IDX1_OBJECT_ID | 1 | 5 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
42 recursive calls
0 db block gets
8 consistent gets
1 physical reads
0 redo size
623 bytes sent via SQL*Net to client
455 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> ---另一种写法参考如下
SQL>
SQL> select (select max(object_id) max from t) max_id,(select min(object_id) min from t) min_id from dual;
MAX_ID MIN_ID
---------- ----------
74905 2
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 1144601230
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 6 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX1_OBJECT_ID | 1 | 5 | 2 (0)| 00:00:01 |
| 3 | SORT AGGREGATE | | 1 | 5 | | |
| 4 | INDEX FULL SCAN (MIN/MAX)| IDX1_OBJECT_ID | 1 | 5 | 2 (0)| 00:00:01 |
| 5 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
45 recursive calls
0 db block gets
26 consistent gets
0 physical reads
0 redo size
629 bytes sent via SQL*Net to client
462 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> (4)索引汇报与优化
(1)你确定查询需要返回所有字段吗
索引回表读的例子
SQL> show user
USER is "MAXWELLPAN"
SQL>
SQL>
SQL> drop table t purge
2 ;
Table dropped.
SQL> create table t as select * from dba_objects;
Table created.
SQL> create index idx1_object_id on t(object_id);
Index created.
SQL> set automatically traceonly
SP2-0735: unknown SET option beginning "automatica..."
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL>
SQL> select * from t where object_id<=5;
Elapsed: 00:00:00.05
Execution Plan
----------------------------------------------------------
Plan hash value: 2919362295
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 528 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 4 | 528 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX1_OBJECT_ID | 4 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<=5)
Statistics
----------------------------------------------------------
57 recursive calls
128 db block gets
55 consistent gets
5 physical reads
25228 redo size
3056 bytes sent via SQL*Net to client
396 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
SQL> 如果 select * from t where object_id<=5;真的可以修改为 select object_id from t where object_id<=5;的话,那代码的效率将会有很大的差别。
比较消除TABLE ACCESS BY INDEX ROWID后的性能
SQL>
SQL>
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> set timing on
SQL> select object_id from t where object_id<=5;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 1056850546
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 20 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX1_OBJECT_ID | 4 | 20 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OBJECT_ID"<=5)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
621 bytes sent via SQL*Net to client
625 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
SQL> 发现逻辑读从55减少为3,代价从3缩减为2,大家知道主要是因为什么吗?
因为在select object_id from t where object_id<=5;的查询中,索引就可以提供object_id列的返回信息了,少了一个TABLE ACCESS BY INDEX ROWID的动作,所以性能就能提升。大家不要小看这个优化,经历的优化案例中,消除TABLE ACCESS BY INDEX ROWID 这个回表动作改进性能的案例占比达20%左右,相当常见。有时就是根据业务需求,将多余的字段取消,恰好留下索引字段,就避免了回表。有时是某些字段不能取消展现,考虑联合索引的方式来避免回表,
(2)索引不含查询列可考虑组合索引
我们前面在业务允许的情况下,将select * from t where object_id<=5;修改为select object_id from t where object_id<=5;从而消除回表,提升了性能,假如有些字段必须展现,但又不多,该怎么办呢?“比如select object_id,object_name from t where object_id<=5;这个写法,非得展现object_name,此时由于object_id索引不包含object_name的信息,回表获取object_name的动作势在必行,
再观察一个TABLE ACCESS BY INDEX ROWID的例子
SQL>
SQL> set autotrace traceonly
SQL>
SQL> set linesize 1000
SQL>
SQL> select object_id,object_name from t where object_id <= 5;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2919362295
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 160 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 4 | 160 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX1_OBJECT_ID | 4 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<=5)
Statistics
----------------------------------------------------------
23 recursive calls
0 db block gets
7 consistent gets
0 physical reads
0 redo size
726 bytes sent via SQL*Net to client
639 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
SQL>
联合索引消除了TABLE ACCESS BY INDEX ROWID
SQL>
SQL> create index idx_un_objid_objname on t(object_id,object_name);
Index created.
Elapsed: 00:00:00.09
SQL> select object_id,object_name from t where object_id <= 5;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2827629532
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 160 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX_UN_OBJID_OBJNAME | 4 | 160 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OBJECT_ID"<=5)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
1 physical reads
0 redo size
726 bytes sent via SQL*Net to client
418 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
SQL> 创建联合索引后,回表的动作TABLE ACCESS BY INDEX ROWID压根儿在执行计划中就找不到,3个逻辑读及值为2的代价还是胜过有回表的7个逻辑读和值为3的代价。
这里要注意平衡,如果联合索引的联合列太多,必然导致索引过大,虽然消除了回表动作,但是索引块变多,在索引中的查询可能就要遍历更多的块了,所以要全面考虑,联合索引列不宜过多,一般超过3个字段组成的联合索引都是不合适的。
(3)聚合因子决定了回表查询的速度
如果在不可避免TABLE ACCESS BY INDEX ROWID的情况下,必须执行这个回表动作,回表查询方式是否也有效率高低之分呢?
实际上,回表查询的速度也是有差异的,这里引出一个重要概念叫聚合因子。
聚合因子试验准备,建有序和无序的表各一张
SQL>
SQL> drop table t_colocated purge;
drop table t_colocated purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.04
SQL> create table t_colocated(id number,col2 varchar2(100));
Table created.
Elapsed: 00:00:00.04
SQL> begin
2 for i in 1 .. 100000
3 loop
4 insert into t_colocated(id,col2) values(i,rpad(dbms_random.random,95,'*'));
5 end loop;
6 end;
7 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:02.91
SQL> alter table t_colocated add constraint pk_t_colocated primary key(id);
Table altered.
Elapsed: 00:00:00.17
SQL> drop table t_disorganized purge;
drop table t_disorganized purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.04
SQL> create table t_disorganized
2 as
3 select id,col2
4 from t_colocated
5 order by col2;
Table created.
Elapsed: 00:00:00.29
SQL> alter table t_disorganized add constraint pk_t_disorg primary key(id);
Table altered.
Elapsed: 00:00:00.14
SQL>
请大家先听我解释,我构造的t_colocated和t_disorganized是何目的。在t_colocated表中,表中的数据基本上是依据id从1到100 000的顺序插入的。而我们都知道,索引是有排列的,此时id列上的索引存放的数据也是按1到100 000的顺序插入的。表和索引两者的排列顺序相似度很高,我们就称之为聚合因子比较低。
接下来看这个t_disorganized表,很显然,由于表的插入顺序是依据col2这个插入记录为随机值的列来排序的,显然和有序的索引块1到100 000的顺序有天壤之别。表和索引两者之间的排列顺序相似度差异明显,我们就称之为聚合因子比较高。
分别分析两张表的聚合因子情况
可以通过数据字典来判断索引的聚合因子的情况
SQL>
SQL> set linesize 1000
SQL> select index_name,
2 blevel,
3 leaf_blocks,
4 num_rows,
5 distinct_keys,
6 clustering_factor
7 from user_ind_statistics
8 where table_name in ('T_COLOCATED', 'T_DISORGANIZED');
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ ---------- ----------- ---------- ------------- -----------------
PK_T_COLOCATED 1 208 100000 100000 1469
PK_T_DISORG 1 208 100000 100000 99937
Elapsed: 00:00:00.21
SQL>
大家是否都还清楚地记得我经常用如下方法来做性能跟踪,查看执行计划和逻辑读的情况:

现在准备教大家使用另外一个跟踪性能的工具:

这种查看执行计划分析性能的方法将会在后续讲表连接时大量使用,这里先让大家熟悉一下。这种方法和set autotrace on的差别大家日后自然会明白,不过这里有一个不方便的地方,那就是alter session set statistics_level=all;方法必须让你的SQL语句执行完毕后才能SELECT *FROM table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last'));进行跟踪。如果你的SQL语句执行返回大量结果,屏幕将不停翻滚,这点要习惯。而autotrace的跟踪却有关闭显示的功能,执行set autotrace off命令即可。
下面我们来分别统计select /*+index(t)*/* from t_colocated t where id>=20000 and id<=40000;和select /*+index(t)*/* from t_disorganized t where id>=20000 and id<=40000;的性能,这里的HINT是我要强迫Oracle使用索引,因为查询返回大部分记录,用索引反而低效,Oracle会选择全表扫描。我故意使用索引,就是要放大索引回表的次数,将性能的差距拉大,加深大家的印象。
首先观察有序表的查询性能
SQL>
SQL> set linesize 1000
SQL> alter session set statistics_level=all;
Session altered.
Elapsed: 00:00:00.00
SQL> select /*+index(t)*/ * from t_colocated t where id>=20000 and id<=40000;
39957 422316419**************************************************************************************
39958 -1393806697************************************************************************************
39959 -1867741122************************************************************************************
39960 -498734919*************************************************************************************
39961 -1152504419************************************************************************************
39962 1573157900*************************************************************************************
39963 1917885110*************************************************************************************
39964 -1416844770************************************************************************************
39965 33560113***************************************************************************************
39966 1101322637*************************************************************************************
39967 -1810319859************************************************************************************
39968 -4621036***************************************************************************************
39969 -1244723612************************************************************************************
39970 -1844862290************************************************************************************
39971 1711176962*************************************************************************************
39972 1319230504*************************************************************************************
39973 -261457153*************************************************************************************
39974 -1417435303************************************************************************************
39975 -1830540328************************************************************************************
39976 -103185233*************************************************************************************
39977 423938897**************************************************************************************
39978 -51715368**************************************************************************************
39979 1657069185*************************************************************************************
39980 -57445566**************************************************************************************
39981 918188444**************************************************************************************
39982 -385695506*************************************************************************************
39983 248209463**************************************************************************************
39984 1674241571*************************************************************************************
39985 636752472**************************************************************************************
39986 -329772948*************************************************************************************
39987 -614086301*************************************************************************************
39988 301427289**************************************************************************************
39989 -292561463*************************************************************************************
39990 502725857**************************************************************************************
39991 -1585119810************************************************************************************
39992 -2104865036************************************************************************************
39993 -2037871245************************************************************************************
39994 1260463480*************************************************************************************
39995 2135359223*************************************************************************************
39996 1410881931*************************************************************************************
39997 538689110**************************************************************************************
39998 764514800**************************************************************************************
39999 -25151934**************************************************************************************
40000 358740384**************************************************************************************
20001 rows selected.
Elapsed: 00:00:06.21
SQL>
SQL> select * from table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID b29s020c6tbyd, child number 0
-------------------------------------
select /*+index(t)*/ * from t_colocated t where id>=20000 and id<=40000
Plan hash value: 1513619617
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20001 |00:00:00.02 | 2985 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T_COLOCATED | 1 | 30844 | 20001 |00:00:00.02 | 2985 |
|* 2 | INDEX RANGE SCAN | PK_T_COLOCATED | 1 | 30844 | 20001 |00:00:00.01 | 1374 |
----------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=20000 AND "ID"<=40000)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
23 rows selected.
Elapsed: 00:00:00.21
SQL> 再观察无序表的查询性能
SQL> set linesize 1000
SQL> alter session set statistics_level=all;
SQL> select /*+index(t)*/ * from t_disorganized t where id>=20000 and id<=40000;
ID COL2
---------- ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
20000 -992114213*************************************************************************************
20001 1920624382*************************************************************************************
39998 764514800**************************************************************************************
39999 -25151934**************************************************************************************
40000 358740384**************************************************************************************
20001 rows selected.
Elapsed: 00:00:06.14
SQL> select * from table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 1gr3svkfdtcax, child number 0
-------------------------------------
select /*+index(t)*/ * from t_disorganized t where id>=20000 and
id<=40000
Plan hash value: 3927524887
-------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20001 |00:00:00.05 | 21365 | 43 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T_DISORGANIZED | 1 | 20002 | 20001 |00:00:00.05 | 21365 | 43 |
|* 2 | INDEX RANGE SCAN | PK_T_DISORG | 1 | 20002 | 20001 |00:00:00.01 | 1374 | 43 |
-------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=20000 AND "ID"<=40000)
20 rows selected.
Elapsed: 00:00:00.02
SQL> 通过比较发现,t_colocated表的索引读产生的逻辑读为2985,而t_disorganized表的索引读产生的逻辑读为21365,差别居然达到近10倍。“同样大小的表和同样大小的索引,且记录数也相同,执行的是同样的语句,仅是聚合因子的差异,或者说是表的排列顺序的差异,居然导致性能差异达到10倍之多















 3857
3857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









