









表的修改操作
不建议用 in ,not in ,exists,not exists,而是用join
in
not in
exists
not exists
join
查看表
show create table 表名
修改表:直接rename表明
hive
alter table t_name rename to (comment:说明)
alter table t3 rename to t_userinfo;
修改列名:alter table change column 改列名直接change 而且列名后面必须带上数据类型
alter table t4 change column name uname string;
修改列的位置 放在哪个字段的后面,或者直接放到第一个
改了结构,但是数据还是原样不动,所以实质的数据和元数据两边之间没有任何交互,它只是个文件,不会任何改变
alter table t4 change column uname uname string after age;
alter table t4 change column uname uname string first;
修改字段类型:string是不能转为int的
alter table t4 change column uname uname int; ----2.x
增加字段:add columns 字段名与字段类型
alter table t4 add columns(
sex int ,
addr string
)
;
不是用dorp,drop则是将数据给干掉
删除字段:replace columns
alter table t4 replace columns( --这里面写的是不删除的字段
id int,
name string,
addr string
)
;
7、内部表和外部表的转换:其实也就是修改表的属性
内部转外部
alter table t4 set tblproperties('EXTERNAL'='TRUE'); ##true必须大写
外部转内部
alter table t4 set tblproperties('EXTERNAL'='false'); ##false大小写都没关系
删除库:
drop database if exists gp1923;--但是它是要为非空的数据库才可以,否则报错
drop database if exists gp1923 cascade;##强制删除
hive的高级查询——sql的语句、执行顺序
查询基本语法:
select distinct --having比这个执行顺序高 (distinct 排序性能很差 ,having的执行顺序高,查询的字段也是having的字段)
from --从那张表
join on --关联条件
where --过滤
group by --分组(分组的字段如果不再聚合函数内,则一定在这个后面)
having --后面带的是聚合函数,对聚合后的结果进行过滤
distribute by / cluster by --分桶查询(和MapReduce的getPartitioner分区一样的操作,就是把查询分到多个Reduce里面)
order by / sort by --前一个是全局排序,就是一个reducetask,后一个是局部排序,就相当于maktask分区内进行排序
limit
union / union all --聚合多个查询的结果,前一个排序去重,后一个不排序,不去重
sql的执行顺序:
from left_table (结果集)
on id>5 (b结果集)
join (笛卡尔积)
where
group by
having
select
distinct
order by
limit
union /union all
注意点:
尽量不要使用in 、not in、exists、not exists
查询尽量避免join操作,但是join是永远避免不了的
查询永远是小表驱动大表(小结果集驱动大结果集)
表的连接:
内连接 inner join
外连接 outer join
左外连接 left outer join
右外连接 right outer join
全外连接 full outer join
hive的特有的类型:
left semi join:(代替exists、not exists)
join :
inner join :
from a,b:内连接、多表逗号,3者效果差不多,相互连接上才能出来结果
join不带任何的on或者where条件,就是笛卡尔积
left join/left outer join/left semi join :
数据以左表的数据为准,左表存在的数据都查询出,右表的数据关联上就出来,关联不上以NULL代替
left join 和left outer join 基本上是一样的
left semi join的结果集只包含左表的数据,一般用来判断数据是否存在。
right join /right outer join
以右表为准,右表的数据全都出来,左表没有关联上的数据以NULL替代
这两个得到的结果也是一样的。
full outer join (左右两表都出来)
hive提供小表标识:使用的是STREAMTABLE(小表别名)
select
/*+STREAMTABLE(d)*/
d.name,
e.name
from u1 e
join u2 d
on d.id = e.id
;map-side join:
如果所有的表中有小表,将会把小表缓存内存中,然后在map端进行连接关系查找。hive在map端
查找时将减小查询量,从内存中读取缓存小表数据,效率较快,还省去大量数据传输和shuffle耗时。
注意看该属性:
set hive.auto.convert.join=true --设置了这个就默认为小表
select
e.*
from u1 d
join u2 e
on d.id = e.id
;以前的老版本,需要添加(/*+MAPJOIN(小表名)*/)来标识该join为map端的join。hive 0.7以后hive已
经废弃,但是仍然管用:????需要再测试看看是否有效???
select
/*+MAPJOIN(d)*/
e.*
from u1 d
join u2 e
on d.id = e.id
;到底小表多大才会被转换为map-side join:
set hive.mapjoin.smalltable.filesize=25000000 约23.8MB
hive练习
create table student(
sId int,
sName string,
sAge date,
sGender String
)row format delimited fields terminated by '\t'; --以Tab键分隔
create table course(
cId int,
cname string,
tId int
)row format delimited fields terminated by '\t';
create table teacher(
tId int,
tName String
)row format delimited fields terminated by '\t';
create table score(
sid int,
cid int,
score int
)row format delimited fields terminated by '\t';
创完表,然后到将数据加载到表里面
inner join和outer join 区别:
1、分区字段对outer join的on条件无效,对inner join的on有效的
有inner join但是没有full inner join
有full outer join但是没有outer join
所有join连接,只支持等值连接(= 和 and),不支持!= <> or
on:所有on只支持等值连接 and
where:where后面通常是表达式,还可以是非聚合函数表达式(但是不能是聚合函数表达式)
group by:分组,通常和聚合函数搭配使用
查询的字段要么出现在group by 之后,要么出现在聚合函数之内
having:对分组后的集合结果进行过滤
sort by:局部排序,只保证单个的reduce中数据有序
order by:全局排序,保证所有reduce端的数据有序。
如果reduce只有一个,两者结果一样
两者通常跟asc desc搭配
只使用order by,reduce的个数只能是1个
设置reduce的数量:
set mapreduce.job.reduces=3;
limit :从结果集中取数据的条数
union:去重+排序
union all:不去重不排序
函数:
内置函数查看命令: show functions; 可以查看所有的内在函数
查看函数对应用法:desc function concat_ws; 可以查看得到给出的提示,是传字符串还是传二进制的值


窗口函数(考点)
排名函数:
row_number:没有并列,相同名次顺序排
rank:有并列,相同名次有空位(有多少同名就空出多少个空位)
dense_rank:有并列,相同名次无空位
成绩表
create table if not exists stu_score(
dt string,
name string,
score int
)
row format delimited --格式
fields terminated by '\t'--用tab分隔
;1、对每次考试按照成绩的高低排序
select *
from stu_score
order by dt,score desc
over开窗子句:
开窗里面写的就是分区的语句
不带聚合的结果
开窗
需求:
求每次考试的成绩top 3 (按照考试来分组,每组出三个,所以不是用limit)
先进行下面的查询
--排名要分每次的考试,,每次的考试分到Reduce里面,所以用到开窗函数,
--开窗的话则在每一行上面都会返回对应的结果 所有的聚合函数都可以进行开窗来做,但是不带聚合的结果,几条进则几条出
select
*,
row_number() over(distribute by dt order by dt asc,score desc) rn,--写的就是分区的语句,按照谁进行分区。数据倒序排
rank() over(partition by dt order by score desc) rk,
dense_rank() over(partition by dt order by score desc) drk
from stu_score
;

在对下面的查询进行限制条件
select
*
from
(
select
*,
row_number() over(distribute by dt sort by dt asc,score desc) rn,
rank() over(distribute by dt sort by score desc) rk,
dense_rank() over(distribute by dt sort by score desc) drk
from stu_score
) a
where a.rn < 4
;
1.x:partition by只和 order by 搭配使用
distribute by 只和sort by 搭配使用
2.x:没有以上限制
2、需求:
求每次考试的最高分、最低分(单纯求最高最低才用聚合函数)
select dt,
max(score) as maxscore,
min(score) as minscore
from stu_score
group by dt
;
2、求每一次考试的的每一位同学与最高分的差值(先用聚合,再用开窗)
select sc.*,a.maxscore,a.minscore
from stu_score sc
join
(select dt,
max(score) as maxscore,
min(score) as minscore
from stu_score
group by dt) a on a.dt = sc.dt
; ---输出结果,不再是聚合的结果,分析开窗函数先将数据分区,然后在分区内进行聚合,然后将聚合的结果输出到每一条数据之中
---输出结果,不再是聚合的结果,分析开窗函数先将数据分区,然后在分区内进行聚合,然后将聚合的结果输出到每一条数据之中
窗口函数是先将数据进行分区,在分区内先计算聚合的值,计算完后,将计算结果追加到每一行的后面,然后都返回,这就是窗口函数的作用,它在分组了,分组是在over内部进行制定分组,按什么字段分组,差别是在输出结果,输出的不是聚合的结果,而是没有聚合的
--原来有多少条数据开窗后还是多少条数据,如果没有开窗,则就需要在select后面加上聚合函数 做一个group by,
--则所有的字段都要放进来
select
*,
max(score) over(distribute by dt) maxscore,--分区后求最大的一个
min(score) over(distribute by dt) minscore--分区后求最小的一个
from stu_score
;
看上面两个结果,其实是一样的。
最大最小值也可以用first_value和last_value来求
将每次修改都把数据记录下来,找第一个版本,或者最后一个版本,所以按照时间排序
select
*,
first_value(score) over(distribute by dt sort by score desc) maxscore,
last_value(score) over(distribute by dt sort by score desc) minscore
from stu_score
;
得出的结果可以看出,最小值是当前行的最小值,也就是默认的限制了比较方法
window子句:可以指定数据窗口的范围
后面接的都是范围
ROWS BETWEEN 界限
UNBOUNDED PRECEDING 第一行
UNBOUNDED FOLLOWING 最后一行
CURRENT ROW --当前行
2 PRECEDING 当前和的前两行
2 FOLLOWING 当前行的后两行,通过这些指令来指定查询的范围
--last_value指定从第一行到最后一行
select
*,
first_value(score) over(distribute by dt sort by score desc) maxscore,
last_value(score ignore nulls) over(distribute by dt sort by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) minscore
from stu_score
;场景:
数据存在多版本的情况,获取第一个版本、最后一个版本的数据
要求的版本的数据是null,要排除null的版本数据,则在first_value和last_value中加上ignore nulls 忽略null值
需求:
求每一位学员的每次考试的成绩对比
dt name score upscore
select sc.*,upsc.score as upscore
from stu_score sc
left join stu_score upsc on upsc.name = sc.name and upsc.dt = '2019-07-06'
where sc.dt = '2019-07-13'
; 是因为得到结果集后再进行过滤
是因为得到结果集后再进行过滤
select sc.*,upsc.score as upscore
from stu_score sc
left join stu_score upsc on upsc.name = sc.name
where sc.dt = '2019-07-13' and upsc.dt = '2019-07-06'
;
lag和lead
lag(column_name,offset,default_value):往上取offset位置的数据
lead(column_name,offset,default_value):往下取offset位置的数据
--去上一次考试的成绩,偏移量是1。
--每一个学员的成绩对比,开窗则用学员名字进行分组,按照考试先后顺序排序
select
*,
lag(score,1) over(distribute by name sort by dt asc) upscore
from stu_score
;
3个排名(分析函数)
first_value、 last_value、lag lead
&& ||
false && null =false
true || null =true
自定义函数(重点)
为什么要有自定义函数
hive的内置函数满足不了所有的业务需求
hive提供很多的模块可以自定义功能,比如:自定义函数、serde(序列化和反序列化)、输入输出格式
常用的自定义函数有哪些?
udf:用户自定义函数,user defined function。一对一的输入输出。(最常用的)
udaf:用户自定义聚合函数,user defined aggregate function。多对一的输入输出
udtf:用户自定义表生成函数(查询结果返回的是一张表)。user defined table-generate function。一对多的输入输出。
1、编写UDF的方法:
1、继承UDF,重写evaluate(),允许重载()(常用)
2、继承genericUDF,重写initlizer()、getdisplay()、evaluate()。
小写转大写



2、UDF的使用方法:
一:(只在当前session有效)
1、将编写好的jar打包并上传到服务器上,并将jar包添加到hive的classpath中(因为依赖都在里面)
如何加入呢,则用下面的命令,加进来
hive>add jar /root/gp1923demo-1.0-SNAPSHOT.jar;
如果不想写上面这的可以用
<property>
<name>hive.aux.jars.path</name>
<value>$HIVE_HOME/auxlib</value>
<description>The location of the plugin jars that contain implementations of user defined functions and serdes.</description>
</property>按照下面三个命令操作(使用hive、使用哪个库、将jar包拉取上来)

2、创建临时函数(创建永久的话要放到hdfs上)
create temporary function myUpCase as 'qfedu.com.bigdata.hiveUDF.firstUDF';
输入show functions;查看刚刚增加的方法
3、检查
第一个测试方法:也可以在本地测试
创建一个表dual,用于测试
create table if not exists dual(id string);
insert into dual values(' ');

第二个用java测试
temp
4、注销(删除临时函数的方法)
drop temporary function if exists myupcase;--要告诉是哪一个库
二:(只在当前session有效)
1、编译jar并上传
2、创建配置文件
vi ./hive-init,将下面的两句放入
add jar /root/gp1923demo-1.0-SNAPSHOT.jar;
create temporary function myUpCase as 'qfedu.com.bigdata.hiveUDF.firstUDF';
3、启动hive的时候带初始化文件
hive -i ./hive-init
三:
1、编译jar并上传
2、创建配置文件
在bin目录下创建一个配置文件,文件名.hiverc
vi bin/.hiverc
add jar /root/gp1923demo-1.0-SNAPSHOT.jar;
create temporary function myUpCase as 'qfedu.com.bigdata.hiveUDF.firstUDF';
3、重启hive (这个不用字初始化文件)
四:
编译源码:(费劲)
1)将写好的Java文件拷贝到~/install/hive-0.8.1/src/ql/src/java/org/apache/hadoop/hive/ql/udf/
cd ~/install/hive-0.8.1/src/ql/src/java/org/apache/hadoop/hive/ql/udf/
ls -lhgt |head
2)修改~/install/hive-0.8.1/src/ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java,增加import和RegisterUDF
import com.meilishuo.hive.udf.UDFIp2Long; //添加import
registerUDF("ip2long", UDFIp2Long.class, false); //添加register
3)在~/install/hive-0.8.1/src下运行ant -Dhadoop.version=1.0.1 package
cd ~/install/hive-0.8.1/src
ant -Dhadoop.version=1.0.1 package
4)替换exec的jar包,新生成的包在/hive-0.8.1/src/build/ql目录下,替换链接
cp hive-exec-0.8.1.jar /hadoop/hive/lib/hive-exec-0.8.1.jar.0628
rm hive-exec-0.8.1.jar
ln -s hive-exec-0.8.1.jar.0628 hive-exec-0.8.1.jar
5)重启进行测试
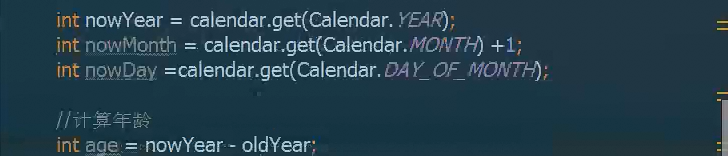
案例1:生日转换成年龄
输入:string birthday 1990-06-21
输出:int age 29



案例2:根据key值找出value值
如:sex=1&hight=180&weight=130&sal=28000
json格式:
{sex:1,hight:180,weight:130,sal:28000}



案例3:正则表达式解析日志:
解析前:
220.181.108.151 - - [31/Jan/2012:00:02:32 +0800] \"GET /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP/1.1\" 200 8784 \"-\" \"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)\"


解析后:
220.181.108.151 20120131 120232 GET /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP 200 Mozilla
案例4:Json数据解析UDF开发
有原始json数据如下:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
最终我要得到一个结果表:
movie rate timestamp uid
1197 3 978302268 1
步骤:
1、创建一个单字段的表关联原始的json数据
2、创建一个自定义的UDF,利用自定义函数将json数据解析成\t分割的字符串
3、将数据插入到临时表
4、使用split函数将解析后的数据切分成4个字段存入到最终结果表
设计四个字段,实现get,set方法




将json解析成类(对象)
1、先创建这个表,然后将json整进去
create table if not exists t_movie_rate(
json string
)
;
2、上传json文件,加载数据,查看一下
![]()

3、然后将jar包copy出来,
add jar /root/gp1923demo-1.0-SNAPSHOT.jar;
create temporary function parserJson as 'qfedu.com.bigdata.hiveUDF.JsonParser';
执行一下这个命令
然后可以查询

create table if not exists t_movie_tmp
as
select parserjson(json) as json from t_movie_rate;
测试:(看看能不能截取)
select split(json,'\t')[0] as movie,split(json,'\t')[1] rate,split(json,'\t')[2] ts,split(json,'\t')[3] uid
from t_movie_tmp
limit 10
;
将数据按tab分隔
再创表,将查询的结果插入进去
create table t_movierate
row format delimited
fields terminated by '\t'
as
select split(json,'\t')[0] as movie,split(json,'\t')[1] rate,split(json,'\t')[2] ts,split(json,'\t')[3] uid
from t_movie_tmp
;select * from t_movierate
limit 10;
get_json_object(第一种处理json串)
里面是有一个函数的,get_json_object可以处理一般的json的解析,传入json传,给定一个路径,路径就是key的值,就会将路径转为json的串
select get_json_object(json,'$.movie') as movie,get_json_object(json,'$.rate') as rate,get_json_object(json,'$.timeStamp') as ts,get_json_object(json,'$.uid') as uid
from t_movie_rate
limit 10
;
json_tuple(第二种处理json串)
p1,p2,pn,多个参数,返回一个元组,输入输出都是string

select movie,rate,ts,uid
from t_movie_rate lateral view json_tuple(json,'movie','rate','timeStamp','uid') js as movie,rate,ts,uid
limit 10
;
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (movie ,rate, ts,uid)
USING 'python weekday.py'
AS (movieid, rating, weekday,userid)
FROM t_movierate;
练习:
Hive实战案例——级联求和accumulate
需求:
有如下访客访问次数统计表 t_access_times
访客 月份 访问次数
A 2015-01 5
A 2015-01 15
B 2015-01 5
A 2015-01 8
B 2015-01 25
A 2015-01 5
A 2015-02 4
A 2015-02 6
B 2015-02 10
B 2015-02 5
…… …… ……
需要输出报表:t_access_times_accumulate
访客 月份 月访问总计 累计访问总计
A 2015-01 33 33
A 2015-02 10 43
A 2015-03 23 66
……. ……. ……. …….
B 2015-01 30 30
B 2015-02 15 45
……. ……. ……. …….
select uid,month,sum(mpv) over(distibute by uid sort by month asc ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS totalpv
from (
select uid,month,sum(pv) as mpv
from t
group by uid,month
)
;
hive的高级应用
hive的总结

r是rownumber ,d是有并列,a是有并列

select id,unix_timestamp(uv_time) - unix_timestamp(lag(uv_time,1,uv_time) over(sort by uv_time asc)),unix_timestamp(lead(uv_time,1,uv_time) over(sort by uv_time) - unix_timestamp(uv_time)
from t
;

select aa.name ,bb.name
from team aa
join team bb
where aa.name < bb.name (<>双循环)
;

select uid
from t
where unix_timstamp(ts) - unix_timestamp(lag(ts,100) over(distribute by uid sort by ts asc)) < 300
group by uid
;















 2652
2652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









