







在多线程环境下为了保证线程安全,往往需要加锁,例如读写锁可以保证读写互斥,读读不互斥。有没有一种数据结构能够实现无锁的线程安全呢?答案就是使用RingBuffer循环队列。在Disruptor项目中就运用到了RingBuffer。
RingBuffer的基本原理如下:
在RingBuffer中设置了两个指针,head和tail。head指向下一次读的位置,tail指向的是下一次写的位置。RingBuffer可用一个数组进行存储,数组内元素的内存地址是连续的,这是对CPU缓存友好的——也就是说,在硬件级别,数组中的元素是会被预加载的,因此在RingBuffer中,CPU无需时不时去主内存加载数组中的下一个元素。通过对head和tail指针的移动,可以实现数据在数组中的环形存取。当head==tail时,说明buffer为空,当head==(tail+1)%bufferSize则说明buffer满了。
在进行读操作的时候,我们只修改head的值,而在写操作的时候我们只修改tail的值。在写操作时,我们在写入内容到buffer之后才修改tail的值;而在进行读操作的时候,我们会读取tail的值并将其赋值给copyTail。赋值操作是原子操作。所以在读到copyTail之后,从head到copyTail之间一定是有数据可以读的,不会出现数据没有写入就进行读操作的情况。同样的,读操作完成之后,才会修改head的数值;而在写操作之前会读取head的值判断是否有空间可以用来写数据。所以,这时候tail到head - 1之间一定是有空间可以写数据的,而不会出现一个位置的数据还没有读出就被写操作覆盖的情况。这样就保证了RingBuffer的线程安全性。
import java.util.Arrays;
public class RingBuffer<T> {
private final static int DEFAULT_SIZE = 1024;
private Object[] buffer;
private int head = 0;
private int tail = 0;
private int bufferSize;
public RingBuffer(){
this.bufferSize = DEFAULT_SIZE;
this.buffer = new Object[bufferSize];
}
public RingBuffer(int initSize){
this.bufferSize = initSize;
this.buffer = new Object[bufferSize];
}
private Boolean empty() {
return head == tail;
}
private Boolean full() {
return (tail + 1) % bufferSize == head;
}
public void clear(){
Arrays.fill(buffer,null);
this.head = 0;
this.tail = 0;
}
public Boolean put(String v) {
if (full()) {
return false;
}
buffer[tail] = v;
tail = (tail + 1) % bufferSize;
return true;
}
public Object get() {
if (empty()) {
return null;
}
Object result = buffer[head];
head = (head + 1) % bufferSize;
return result;
}
public Object[] getAll() {
if (empty()) {
return new Object[0];
}
int copyTail = tail;
int cnt = head < copyTail ? copyTail - head : bufferSize - head + copyTail;
Object[] result = new String[cnt];
if (head < copyTail) {
for (int i = head; i < copyTail; i++) {
result[i - head] = buffer[i];
}
} else {
for (int i = head; i < bufferSize; i++) {
result[i - head] = buffer[i];
}
for (int i = 0; i < copyTail; i++) {
result[bufferSize - head + i] = buffer[i];
}
}
head = copyTail;
return result;
}
}
RingBuffer解决粘包问题:
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。粘包可能由发送方造成,也可能由接收方造成。TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据,造成多个数据包的粘连。如果接收进程不及时接收数据,已收到的数据就放在系统接收缓冲区,用户进程读取数据时就可能同时读到多个数据包。因为系统传输的数据是带结构的数据,需要做分包处理。
为了适应高速复杂网络条件,我们设计实现了粘包处理模块,由接收方通过预处理过程,对接收到的数据包进行预处理,将粘连的包分开。为了方便粘包处理,提高处理效率,在接收环节使用了环形缓冲区来存储接收到的数据。其结构如表1所示。
表1 环形缓冲结构
| 字段名 | 类型 | 含义 |
| CS | CRITICAL_SECTION | 保护环形缓冲的临界区 |
| pRingBuf | UINT8* | 缓冲区起始位置 |
| pRead | UINT8* | 当前未处理数据的起始位置 |
| pWrite | UINT8* | 当前未处理数据的结束位置 |
| pLastWrite | UINT8* | 当前缓冲区的结束位置 |
当前缓冲区的结束位置
环形缓冲跟每个TCP套接字绑定。在每个TCP的SOCKET_OBJ创建时,同时创建一个PRINGBUFFER结构并初始化。这时候,pRingBuf指向环形缓冲区的内存首地址,pRead、pWrite指针也指向它。pLastWrite指针在这时候没有实际意义。初始化之后的结构如图1所示。

图1 初始化后的环形缓冲区
在每次投递一个TCP的接收操作时,从RINGBUFFER获取内存作接收缓冲区,一般规定一个最大值L1作为可以写入的最大数据量。这时把pWrite的值赋给BUFFER_OBJ的buf字段,把L1赋给bufLen字段。这样每次接收到的数据就从pWrite开始写入缓冲区,最多写入L1字节,如图 2。
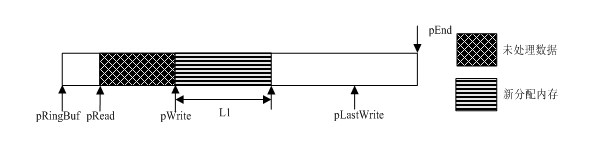
图2 分配缓冲后的环形缓冲
如果某次分配过程中,pWrite到缓冲区结束的位置pEnd长度不够最小分配长度L1,为了提高接收效率,直接废弃最后一段内存,标记pLastWrite为pWrite。然后从pRingBuf开始分配内存,如图 3。

图 3 使用到结尾的环形缓冲
特殊情况下,如果处理包速度太慢,或者接收太快,可能导致未处理包占用大部分缓冲区,没有足够的缓冲区分配给新的接收操作,如图4。这时候直接报告错误即可。

图 4 没有足够接收缓冲的环形缓冲
当收到一个长度为L数据包时,需要修改缓冲区的指针。这时候已经写入数据的位置变为(pWrite+L),如图 5。
图 5 收到长度为L的数据的环形缓冲
分析上述环形缓冲的使用过程,收到数据后的情况可以简单归纳为两种:pWrite>pRead,接收但未处理的数据位于pRead到pWrite之间的缓冲区;pWrite<pRead,这时候,数据位于pRead到pLastWrite和pRingbuf到pWrite之间。这两种情况分别对应图6、图 7。
首先分析图6。此时,pRead是一个包的起始位置,如果L1足够一个包头长度,就获取该包的长度信息,记为L。假如L1>L,就说明一个数据包接收完成,根据包类型处理包,然后修改pRead指针,指向下一个包的起始位置(pRead+L)。这时候仍然类似于之前的状态,于是解包继续,直到L1不足一个包的长度,或者不足包头长度。这时退出解包过程,等待后续的数据到来。
图 6 有未处理数据的环形缓冲(1)
图 7 有未处理数据的环形缓冲(2)
图 8稍微复杂。首先按照上述过程处理L1部分。存在一种情况,经过若干个包处理之后,L1不足一个包,或者不足一个包头。如果这时(L1+L2)足够一个包的长度,就需要继续处理。另外申请一个最大包长度的内存区pTemp,把L1部分和L2的一部分复制到pTemp,然后执行解包过程。
经过上述解包之后,pRead就转向pRingBuf到pWrite之间的某个位置,从而回归情况图 6,继续按照图 6部分执行解包。















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









